
{kind=link}

Giant-scale language fashions have made important progress in generative duties involving multiple-speaker speech synthesis, music era, and audio era. The mixing of speech modality into multimodal unified giant fashions has additionally change into in style, as seen in fashions like SpeechGPT and AnyGPT. These developments are largely as a consequence of discrete acoustic codec representations used from neural codec fashions. Nevertheless, it poses challenges in bridging the hole between steady speech and token-based language fashions. Whereas present acoustic codec fashions provide good reconstruction high quality, there’s room for enchancment in areas like excessive bitrate compression and semantic depth.
Present strategies concentrate on three fundamental areas to handle challenges in acoustic codec fashions. The primary methodology consists of higher reconstruction high quality via methods like AudioDec, which demonstrated the significance of discriminators, and DAC, which improved high quality utilizing methods like quantizer dropout. The second methodology makes use of enhanced compression-led developments comparable to HiFi-Codec’s parallel GRVQ construction and Language-Codec’s MCRVQ mechanism, reaching good efficiency with fewer quantizers for each. The final methodology goals to deepen the understanding of codec house with TiCodec modeling time-independent and time-dependent info, whereas FACodec separates content material, type, and acoustic particulars.
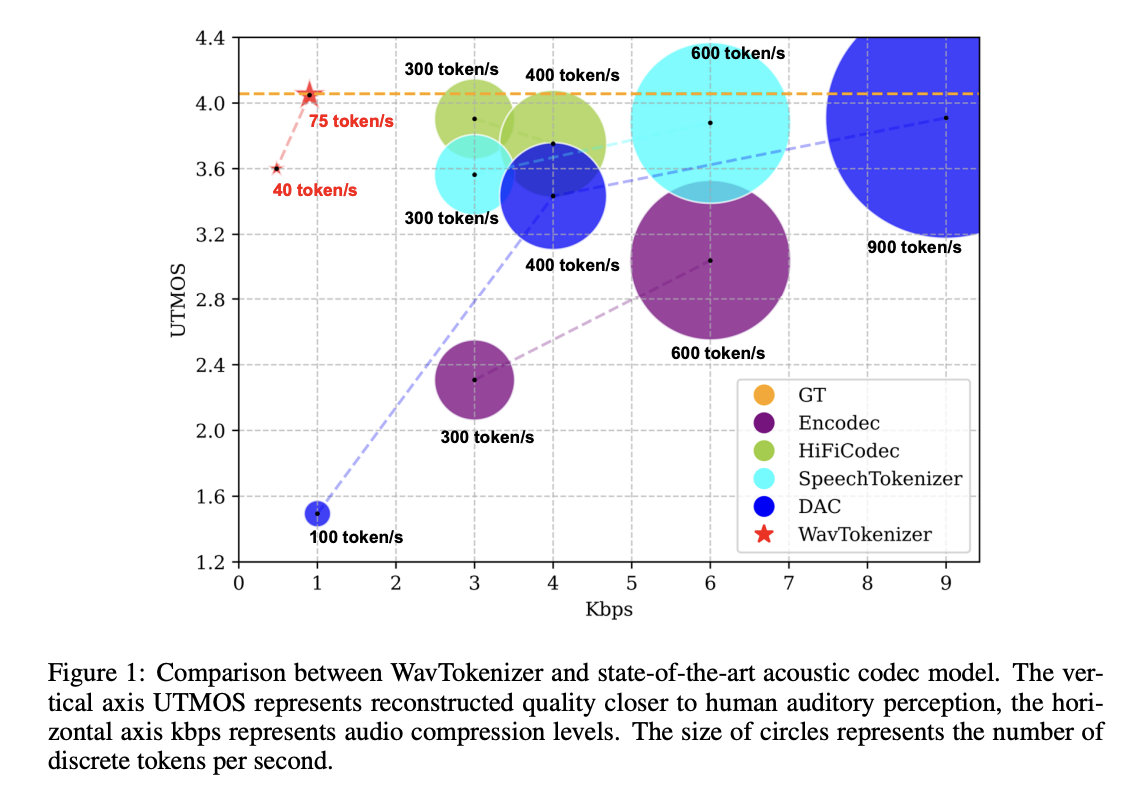
A crew from Zhejiang College, Alibaba Group, and Meta’s Elementary AI Analysis have proposed WavTokenizer, a novel acoustic codec mannequin, that provides important benefits over earlier state-of-the-art fashions within the audio area. WavTokenizer achieves excessive compression by lowering the layers of quantizers and the temporal dimension of the discrete codec, with solely 40 or 75 tokens for one second of 24kHz audio. Furthermore, its design incorporates a broader VQ house, prolonged contextual home windows, improved consideration networks, a strong multi-scale discriminator, and an inverse Fourier remodel construction. It demonstrates sturdy efficiency, in numerous domains like speech, audio, and music.
The structure of WavTokenizer is designed for unified modeling throughout domains like multilingual speech, music, and audio. Its giant model is educated on roughly 80,000 hours of knowledge from numerous datasets, together with LibriTTS, VCTK, CommonVoice, and so on. Its medium model makes use of a 5,000-hour subset, whereas the small model is educated on 585 hours of LibriTTS information. The WavTokenizer’s efficiency is evaluated towards state-of-the-art codec fashions utilizing official weight recordsdata from numerous frameworks comparable to Encodec 2, HiFi-Codec 3, and so on. It’s educated on NVIDIA A800 80G GPUs, with enter samples of 24 kHz. The optimization of the proposed mannequin is finished utilizing the AdamW optimizer with particular studying price and decay settings.
The outcomes demonstrated the excellent efficiency of WavTokenizer throughout numerous datasets and metrics. The WavTokenizer-small outperforms the state-of-the-art DAC mannequin by 0.15 on the UTMOS metric and the LibriTTS test-clean subset, which intently aligns with human notion of audio high quality. Furthermore, this mannequin outperforms DAC’s 100-token mannequin throughout all metrics with solely 40 and 75 tokens, proving its effectiveness in audio reconstruction with a single quantizer. The WavTokenizer performs comparably to Vocos with 4 quantizers and SpeechTokenizer with 8 quantizers on goal metrics like STOI, PESQ, and F1 rating.
In conclusion, WavTokenizer reveals a big development in acoustic codec fashions, able to quantizing one second of speech, music, or audio into simply 75 or 40 high-quality tokens. This mannequin achieves outcomes akin to present fashions on the LibriTTS test-clean dataset whereas providing excessive compression. The crew carried out a complete evaluation of the design motivations behind the VQ house and decoder and validated the significance of every new module via ablation research. The findings present that the WavTokenizer has the potential to revolutionize audio compression and reconstruction throughout numerous domains. Sooner or later, researchers plan to solidify WavTokenizer’s place as a cutting-edge answer within the discipline of acoustic codec fashions.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Here’s a extremely really helpful webinar from our sponsor: ‘Constructing Performant AI Purposes with NVIDIA NIMs and Haystack’

Sajjad Ansari is a closing yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a concentrate on understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.