
{kind=link}

Giant Language Fashions (LLMs) have revolutionized synthetic intelligence, impacting varied scientific and engineering disciplines. The Transformer structure, initially designed for machine translation, has turn into the inspiration for GPT fashions, considerably advancing the sphere. Nevertheless, present LLMs face challenges of their coaching method, which primarily focuses on predicting the following token primarily based on earlier context whereas sustaining causality. This simple methodology has been utilized throughout various domains, together with robotics, protein sequences, audio processing, and video evaluation. As LLMs proceed to develop in scale, reaching a whole bunch of billions to even trillions of parameters, issues come up in regards to the accessibility of AI analysis, with some fearing it might turn into confined to business researchers. The central downside researchers are tackling is tips on how to improve mannequin capabilities to match these of a lot bigger architectures or obtain comparable efficiency with fewer coaching steps, finally addressing the challenges of scale and effectivity in LLM improvement.
Researchers have explored varied approaches to boost LLM efficiency by manipulating intermediate embeddings. One methodology concerned making use of hand-tuned filters to the Discrete Cosine Rework of the latent house for duties like named entity recognition and subject modeling in non-causal architectures comparable to BERT. Nevertheless, this method, which transforms your complete context size, just isn’t appropriate for causal language modeling duties.
Two notable methods, FNet and WavSPA, tried to enhance consideration blocks in BERT-like architectures. FNet changed the eye mechanism with a 2-D FFT block, however this operation was non-causal, contemplating future tokens. WavSPA computed consideration in wavelet house, using multi-resolution transforms to seize long-term dependencies. Nevertheless, it additionally relied on non-causal operations, analyzing your complete sequence size.
These present strategies, whereas modern, face limitations of their applicability to causal decoder-only architectures like GPT. They typically violate the causality assumption essential for next-token prediction duties, making them unsuitable for direct adaptation to GPT-like fashions. The problem stays to develop methods that may improve mannequin efficiency whereas sustaining the causal nature of decoder-only architectures.
Researchers from Stanford suggest the primary occasion of incorporating wavelets into LLMs, WaveletGPT, to boost LLMs by incorporating wavelets into their structure. This system, believed to be the primary of its sort, provides multi-scale filters to the intermediate embeddings of Transformer decoder layers utilizing Haar wavelets. The innovation permits every next-token prediction to entry multi-scale representations at each layer, quite than counting on fixed-resolution representations.
Remarkably, this methodology accelerates pre-training of transformer-based LLMs by 40-60% with out including additional parameters, a major development given the widespread use of Transformer Decoder-based architectures throughout varied modalities. The method additionally demonstrates substantial efficiency enhancements with the identical variety of coaching steps, similar to including a number of layers or parameters.
The wavelet-based operation exhibits efficiency boosts throughout three totally different modalities: language (text-8), uncooked audio (YoutubeMix), and symbolic music (MAESTRO), highlighting its versatility for structured datasets. Additionally, by making the wavelet kernels learnable, which provides solely a small fraction of parameters, the mannequin achieves even larger efficiency will increase, permitting it to be taught multi-scale filters on intermediate embeddings from scratch.

The proposed methodology incorporates wavelets into transformer-based Giant Language Fashions whereas sustaining the causality assumption. This method will be utilized to varied architectures, together with non-transformer setups. The approach focuses on manipulating intermediate embeddings from every decoder layer.
For a given sign xl(i), representing the output of the lth decoder layer alongside the ith coordinate, the strategy applies a discrete wavelet remodel. With N+1 layers and an embedding dimension E, this course of generates N*E indicators of size L (context size) from intermediate embeddings between decoder blocks.
The wavelet remodel, particularly utilizing Haar wavelets, entails passing the sign via filters with totally different resolutions. Haar wavelets are square-shaped features derived from a mom wavelet via scaling and shifting operations. This course of creates baby wavelets that seize sign data at varied time-scales.
The discrete wavelet remodel is carried out by passing the sign via low-pass and high-pass filters, adopted by downsampling. For Haar wavelets, this equates to averaging and differencing operations. The method generates approximation coefficients (yapprox) and element coefficients (ydetail) via convolution and downsampling. This operation is carried out recursively on the approximation coefficients to acquire multi-scale representations, permitting every next-token prediction to entry these multi-resolution representations of intermediate embeddings.
This methodology connects wavelets and LLM embeddings by specializing in approximation coefficients, which seize structured information at varied ranges. For textual content, this construction ranges from letters to subject fashions, whereas for symbolic music, it spans from notes to total items. The method makes use of Haar wavelets, simplifying the method to a transferring common operation. To keep up causality and unique sequence size, the strategy computes transferring averages of prior samples inside a selected kernel size for every token dimension. This creates multi-scale representations of the enter sign, permitting the mannequin to seize data at totally different resolutions throughout embedding dimensions with out altering the construction of intermediate Transformer embeddings.

The strategy introduces a novel method to include multi-scale representations with out rising architectural complexity. As an alternative of computing all ranges of approximate indicators for every embedding dimension, it parameterized the extent by the index of the embedding dimension itself. This method retains half of the intermediate embedding indicators unchanged, whereas processing the opposite half primarily based on their index. For the processed half, a easy mapping operate f determines the kernel dimension for every coordinate, starting from stage I to IX approximations. The modified sign xnl(i) is computed utilizing a causal transferring common filter with a kernel dimension decided by f(i). This operation maintains the causality assumption vital in LLMs and prevents data leakage from future tokens. The approach creates a construction the place totally different embedding dimensions transfer at totally different charges, permitting the mannequin to seize data at varied scales. This multi-rate construction permits the eye mechanism to make the most of multi-scale options at each layer and token, doubtlessly enhancing the mannequin’s skill to seize complicated patterns within the information.
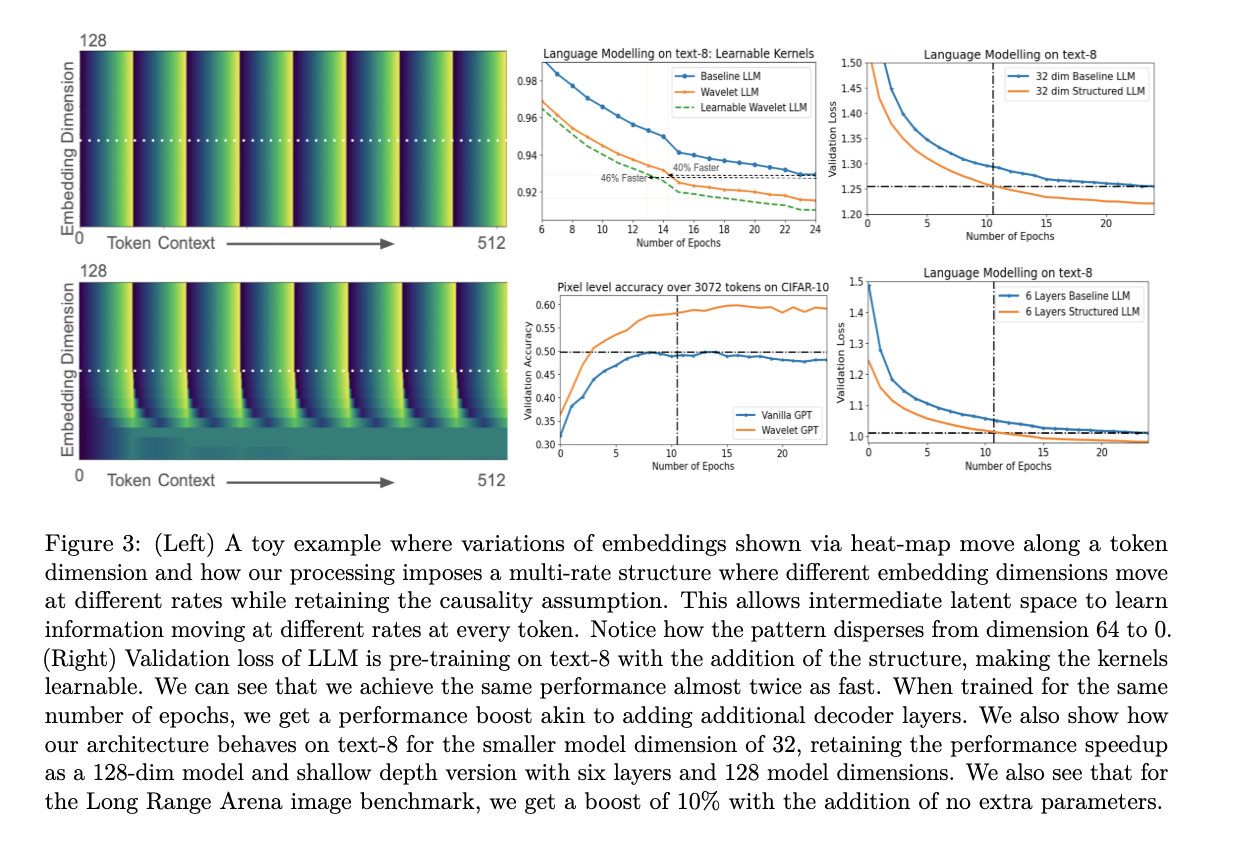
Outcomes throughout three modalities – textual content, symbolic music, and audio waveforms – exhibit substantial efficiency enhancements with the wavelet-based intermediate operation. For pure language, the lower in validation loss is equal to increasing from a 16-layer to a 64-layer mannequin on the text-8 dataset. The modified structure achieves the identical loss almost twice as quick as the unique when it comes to coaching steps. This speedup is much more pronounced for uncooked audio, doubtlessly because of the quasi-stationary nature of audio indicators over brief time scales. The convergence for uncooked waveform LLM setups happens nearly twice as rapidly in comparison with text-8 and symbolic music.
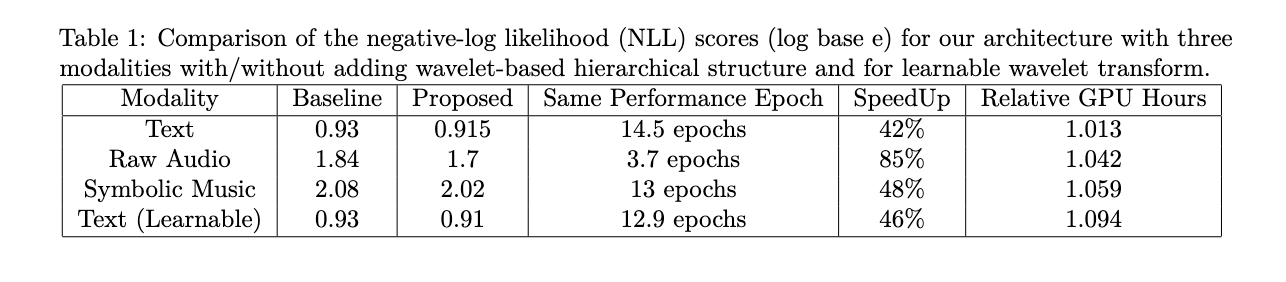
Evaluating absolute clock run occasions, the modified structure exhibits computational effectivity in each learnable and non-learnable setups. The time required to finish one epoch relative to the baseline structure is reported. The strategy proves to be computationally cheap, as the first operation entails easy averaging for Haar wavelets or studying a single filter convolutional kernel with variable context lengths throughout embedding dimensions. This effectivity, mixed with the efficiency enhancements, underscores the effectiveness of the wavelet-based method in enhancing LLM coaching throughout various modalities with out important computational overhead.
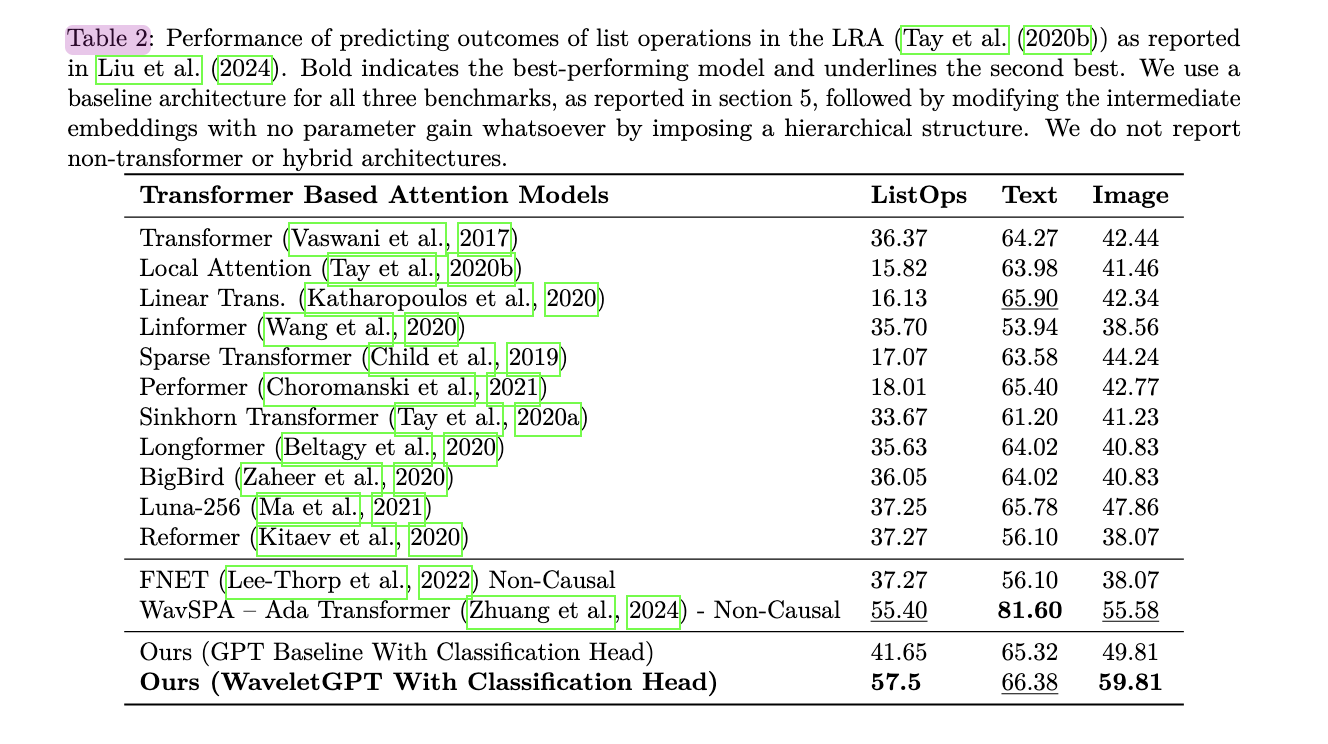
This research presents WaveletGPT, introducing the mixing of wavelets, a core sign processing approach, into massive language mannequin pre-training. By introducing a multi-scale construction to intermediate embeddings, efficiency pace is enhanced by 40-60% with out including any additional parameters. This system proves efficient throughout three totally different modalities: uncooked textual content, symbolic music, and uncooked audio. When skilled for a similar period, it demonstrates substantial efficiency enhancements. Potential future instructions embrace incorporating superior ideas from wavelets and multi-resolution sign processing to optimize massive language fashions additional.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 50k+ ML SubReddit.
We’re inviting startups, firms, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report will probably be launched in late October/early November 2024. Click on right here to arrange a name!
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.