
{kind=link}

[ad_1]
This tutorial weblog examines among the use circumstances of key-value pair extractions, the standard and present approaches to fixing the duty, and a pattern implementation with code.
You encounter KVPs extra typically than you would possibly notice. Keep in mind the final time you flipped by way of a dictionary? Every phrase (the important thing) is paired with its definition (the worth). Or take into account the kinds you’ve got crammed out – the questions are the keys, and your solutions are the values. Even within the enterprise world, invoices use this construction: gadgets bought are the keys, with costs as their corresponding values.

However here is the problem: not like neatly structured tables, KVPs typically cover in unstructured information or unfamiliar codecs. Typically, they’re even partially handwritten. Think about attempting to manually extract information from 1000’s of handwritten kinds or scanned invoices. It is a recipe for errors and frustration.
That is the place automated key-value pair extraction helps. By leveraging deep studying strategies, we will educate machines to know doc buildings and extract helpful info precisely and effectively.
On this information, we’ll have a look at key-value pair extraction, from its wide-ranging purposes to cutting-edge strategies. We’ll present an outline of KVP extraction use circumstances, enable you to perceive conventional strategies and their limitations, discover how deep studying is revolutionizing the sphere, and information you thru constructing your personal extraction system.

Quick-track your KVP extraction with out compromising accuracy.
Constructing a customized key-value extraction system requires important time, experience, and assets. With Nanonets, you get ready-to-use fashions that deal with various paperwork, liberating you to give attention to integrating information into your workflows.
What’s a Key-Worth Pair (KVP)?
Think about you are organizing your closet. You would possibly label every shelf: “Shirts,” “Pants,” “Sneakers.” These labels are your keys, and the gadgets on every shelf are the values. That is the essence of a key-value pair!
On the planet of information, a key-value pair (KVP) is a set of two linked information parts: a novel identifier (the important thing) and its related information (the worth). It is like a digital labeling system that permits for environment friendly storage and retrieval of data.

KVPs are the constructing blocks of many information buildings and databases. The great thing about KVPs lies of their simplicity and suppleness. They’ll deal with structured information (like spreadsheets) and unstructured information (like textual content in paperwork) equally nicely. This makes them a robust instrument for key info extraction from various sources.
Key-value pair extraction is not only for tech wizards. This highly effective method has purposes that stretch far past the realm of coding and information science.
Let’s discover how KVP extraction is usually a game-changer for each private and enterprise use.
Private use circumstances

Whereas automation is usually used for large-scale productions, quick and correct key-value extraction can even profit small events and private usages, bettering the group and effectivity of each day routines.
1. ID-scanning and information conversion:
Private IDs are typical examples of paperwork that comprise varied KVPs, from the given title to the date of start. When wanted for on-line purposes, we frequently must manually discover and sort within the info, which could possibly be tedious and repetitive.
KVP extractions from pictures of the ID can permit us to rapidly convert information into machine-understandable texts. Discovering the matching fields for various values will then turn out to be a trivial job for applications, and the one guide effort required can be to only scan by way of for double-checking.
2. Bill information extraction for budgeting:
Budgeting is a vital side of our private routine. Whereas the event of Excel and spreadsheets has already made such irritable duties less complicated, a KVP extraction of things bought and their corresponding costs from merely a picture of the bill can pace up your complete course of even quicker. Structured information and numbers can permit us to rapidly carry out evaluation and be careful for purchases which can be past our affordability.
3. E mail group and prioritization:
Drowning in a sea of emails? KVP extraction might help you keep afloat. By figuring out key info like sender, topic, and essential dates inside emails, it will possibly robotically kind and prioritize your inbox. Think about by no means lacking an essential deadline or follow-up once more!
Companies use circumstances
Each industries and companies cope with 1000’s of paperwork with related codecs day-after-day. From purposes to asset administration, these doc info retrieval processes are sometimes labor-intensive.

Therefore, automation of the preliminary step of extracting key-value pairs inside unformatted information can considerably cut back the redundancy of human assets whereas concurrently guaranteeing the reliability of the information retrieved.
1. Automation of doc scanning:
Governments or massive companies equivalent to banks course of many handwritten kinds with equivalent codecs for varied functions (e.g., Visa utility, financial institution switch). Retrieving the handwritten info from the kinds and changing it into digital paperwork by way of human effort could possibly be extraordinarily repetitive and tedious, resulting in frequent minor errors.
A correct KVP extraction pipeline of changing handwritten information into corresponding values of various keys after which inputting it into large-scale methods can cut back such errors and save further labor expenditures.
2. Survey assortment and statistical evaluation:
Firms and Non-Governmental Organisations (NGOs) could typically require suggestions from clients or residents to enhance their present merchandise or promotional plans. They’d must carry out a statistical evaluation to guage the enter comprehensively.
But, the same downside of changing unstructured information and handwritten surveys into numerical figures that could possibly be used for calculations nonetheless exists. Therefore, KVP extraction performs a vital position in changing pictures of those surveys into analyzable information.
3. Provide chain administration:
Within the advanced world of logistics, KVP extraction is usually a lifesaver. Extract key info from delivery manifests, invoices, and customs paperwork to streamline your provide chain processes. This may result in quicker shipments, diminished errors, and happier clients.
4. Healthcare report administration:
For healthcare suppliers, managing affected person information effectively is essential. KVP extraction might help digitize and set up affected person info from varied sources – consumption kinds, lab reviews, and physician’s notes. This not solely saves time however can even enhance affected person care by making essential info simply accessible.
5. Authorized doc evaluation:
Legislation companies cope with mountains of paperwork each day. KVP extraction might help attorneys rapidly establish key info in contracts, court docket paperwork, and case information. This may considerably pace up case preparation and contract evaluate processes, permitting authorized professionals to give attention to technique slightly than drowning in paperwork.
6. Customer support optimization:
By extracting key info from buyer emails, chat logs, and assist tickets, companies can rapidly categorize and prioritize buyer points. This results in quicker response instances, extra customized service, and finally, larger buyer satisfaction.
So, how precisely does KVP extraction work? And how are you going to implement it in your personal tasks or enterprise processes? Within the subsequent part, we’ll have a look at the standard approaches to KVP extraction and their limitations.

Put info extraction on autopilot now!
Get pre-trained fashions for doc sorts equivalent to invoices and receipts. This lets you quickly deploy KVP extraction with out intensive in-house improvement.
A very powerful aspect of KVP extraction and discovering the underlying helpful information is the Optical Character Recognition (OCR) course of. In easy phrases, OCR is the digital conversion of scanned pictures and images into machine-encoded texts for additional computations.
Earlier than the accuracy of deep studying meets the wants of the markets for such duties, OCRs are carried out with the next process:
- Database creation: First, we construct an enormous library of identified characters and symbols. It is like making a digital alphabet e book.
- Function detection: When a picture is available in, OCR makes use of a photosensor to establish key factors and options. Think about tracing the traces of every letter together with your finger.
- Sample matching: The system then compares the detected options with its database of identified characters.
- Textual content conversion: Based mostly on the best similarity attributes, it transforms the matched patterns into machine-readable textual content, making your scanned picture or doc digitally accessible.
For years, this strategy has been the go-to methodology for extracting key-value pairs from paperwork. However as with every expertise, it has its limitations.
- Template dependence: Conventional strategies typically require predefined templates or guidelines for various doc sorts.
- Handwriting detection: Whereas nice with printed textual content, these methods typically stumble when confronted with the wild world of human handwriting.
- Lack of context: Conventional OCR focuses on particular person characters, typically lacking the larger image of how info is structured on the web page.
- Inflexibility: Adapting to new doc codecs or layouts could be time-consuming and require guide updates to the system.
Regardless of these limitations, conventional strategies nonetheless play a vital position in lots of key worth extraction eventualities. Nevertheless, as our information wants have grown extra advanced – consider the huge array of doc sorts a big company offers with each day – so too have our extraction strategies.
Fortunately, the current developments in deep studying have breathed new life into OCR and key-value pair extraction strategies. Deep studying fashions, notably convolutional neural networks (CNNs), have revolutionized the sphere of picture recognition and textual content extraction.
Deep studying in motion
Deep studying is among the important branches of machine studying that has gained reputation in current a long time. Not like conventional laptop science and engineering approaches, the place we design the system that receives an enter to generate an output, deep studying hopes to depend on the inputs and outputs to design an intermediate system that may be prolonged to unseen inputs by making a so-called neural community.

A neural community is an structure that’s impressed by the organic perform of the human mind. The community consists of a number of layers:
- Enter layer: That is the place your doc enters the system. Whether or not it is a scanned bill, a handwritten kind, or a digital PDF, the enter layer processes the uncooked information.
- Hidden layers: These are the mind’s powerhouse. A number of layers work collectively to establish options, acknowledge patterns, and make sense of the doc’s construction.
- Output layer: That is the place the magic occurs. The system produces the extracted key-value pairs, neatly organized and prepared to be used.
Because the capability of GPUs and reminiscences drastically superior, deep studying has turn out to be a positive technique lately, which ignited inventive variations of neural networks. Probably the most typical neural networks used at present, particularly in laptop imaginative and prescient, is the convolutional neural community (CNN). CNNs are convolutional kernels that slide by way of the picture to extract options, typically accompanied by conventional community layers to carry out duties equivalent to picture classification or object detection.
Get extremely correct KVP extraction as a service!
With Nanonets, you get state-of-the-art fashions by way of user-friendly APIs, enabling you to profit from AI-powered extraction with out the necessity to construct and preserve advanced fashions in-house.
It would not simply have a look at particular person phrases or characters; it examines your complete doc, contemplating format, font sizes, and even refined visible cues. This holistic strategy permits it to know the doc’s construction and extract key-value pairs with outstanding accuracy.
As an example, in healthcare report administration, a CNN can distinguish between affected person info, physician’s notes, and check outcomes, even when the format varies between paperwork. This degree of understanding was merely not potential with conventional strategies.
Probably the most thrilling bit is that the extra paperwork a deep studying system processes, the smarter it turns into.
Now that you’ve got some fundamental understanding of deep studying, let’s undergo a number of deep studying approaches for KVP extraction.
Tesseract OCR Engine
Latest OCR strategies have additionally included deep studying fashions to realize larger accuracy. The Tesseract OCR engine, maintained by Google, is a major instance. It makes use of a particular sort of neural community known as Lengthy Brief-Time period Reminiscence (LSTM).
What’s LSTM?
An LSTM is a specific household of networks which can be utilized majorly to sequence inputs. This is why it is a game-changer for key worth pair extraction:
Sequential Information Processing: LSTMs excel at dealing with sequential information. Consider it as studying a doc the best way a human would – understanding context and predicting what would possibly come subsequent.
Context issues: In OCR, beforehand detected letters might help predict the subsequent ones. For instance, if “D” and “o” are detected, “g” is extra more likely to comply with than “y”.
Tesseract Structure
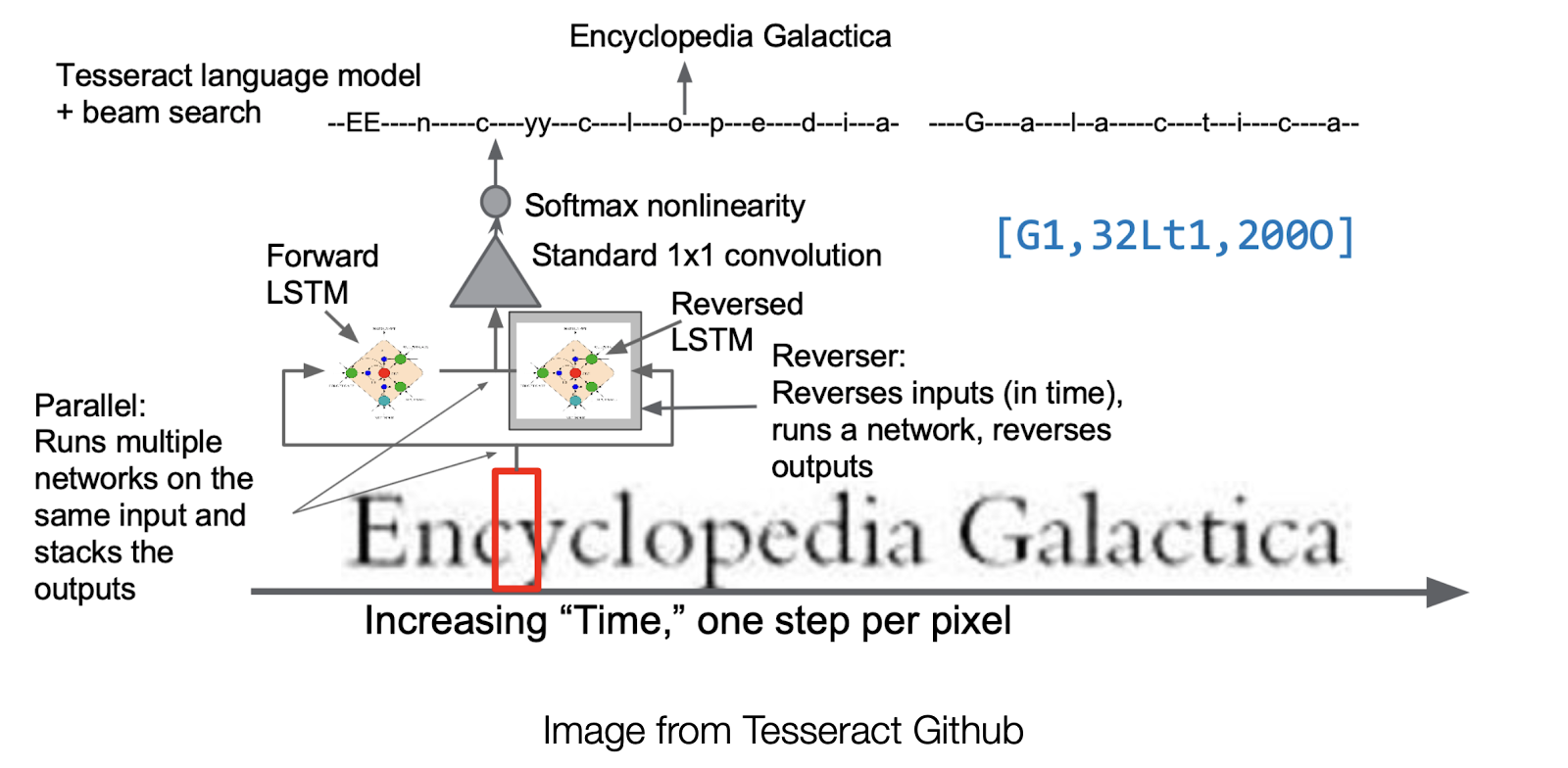
A small bounding field is moved ahead pixel by pixel with time. The picture bounded by the field is extracted to cross by way of each a ahead and backward LSTM, adopted by a convolution layer for the ultimate output.
The improved structure will increase the accuracy and robustness of the OCR, making it simpler to transform a number of various kinds of texts into one structured, digital doc. These digital paperwork with machine-readable strings are a lot simpler to be organised for KVP extraction.
Deep Reader
Apart from main the developments in OCR, deep studying additionally created alternatives for exploration. Deep Reader, a workshop paper from the highest CS convention ACCV*, is one instance that makes use of neural networks to acknowledge shapes and codecs extending past simply phrases and symbols of a scanned doc. Such strategies could be notably useful in duties equivalent to KVP extraction.
*Aspect Notice: The most effective analysis papers from the pc science area are often revealed in top-tier conferences. Acceptance into such conferences symbolises an approval and recognition of by specialists inside the discipline. The Asian Convention on Laptop Imaginative and prescient (ACCV) is among the acknowledged conferences inside the area of laptop imaginative and prescient.
What’s Deep Reader?
Whereas Tesseract focuses on textual content, Deep Reader takes key worth pair extraction to the subsequent degree by understanding your complete doc construction.
Deep Readers makes an attempt to deal with the continued downside of inadequate info retrieval when extracting solely phrases and texts alone by additionally discovering the visible entities equivalent to traces, tables, and containers inside these scanned paperwork.
For each picture, Deep Reader denoises the picture, identifies the doc, and processes the handwritten textual content with a deep-learning strategy earlier than detecting and extracting significant texts and shapes. These options are then used to retrieve tables, containers, and, most significantly, KVPs.
Pre-processing
Previous to extracting textual entities, Deep Reader performs a number of pre-processing steps to make sure the highest quality retrieval within the latter components:
- Picture de-noising: Deep Reader adopts a generative adversarial community (GAN) to generate a de-noised model of an enter. GAN, first developed by Ian et al. in 2014, is a neural community that contains two sub-networks — a generator and a discriminator. As soon as an enter is given, the generator generates a picture based mostly on the enter, and the discriminator tries to tell apart between the bottom reality and the generated enter. Upon training-completion, a generator can efficiently generate a picture based mostly on the enter that’s near the precise floor reality. On this case, the GAN, given pairs of pictures (one de-noised and one noised), makes an attempt to discover ways to generate the de-noised model of the picture from the perturbed one.
- Doc identification: In an effort to precisely retrieve visible entities, Deep Reader additionally makes an attempt to categorise the scanned paperwork into one of many templates by way of a convolutional Siamese community. The Siamese community consists of two equivalent convolutional layers that settle for pictures of the scanned doc and templates as inputs respectively, then compute the similarity between the 2. The best similarity amongst all comparisons implies that the doc is predicated on the template.
- Processing handwritten textual content: To deal with the issue of recognising handwritten texts, Deep Reader additionally adopts a handwritten textual content recognition by way of an encoder-decoder to map the handwritten texts into units of characters.
Deep Reader Structure
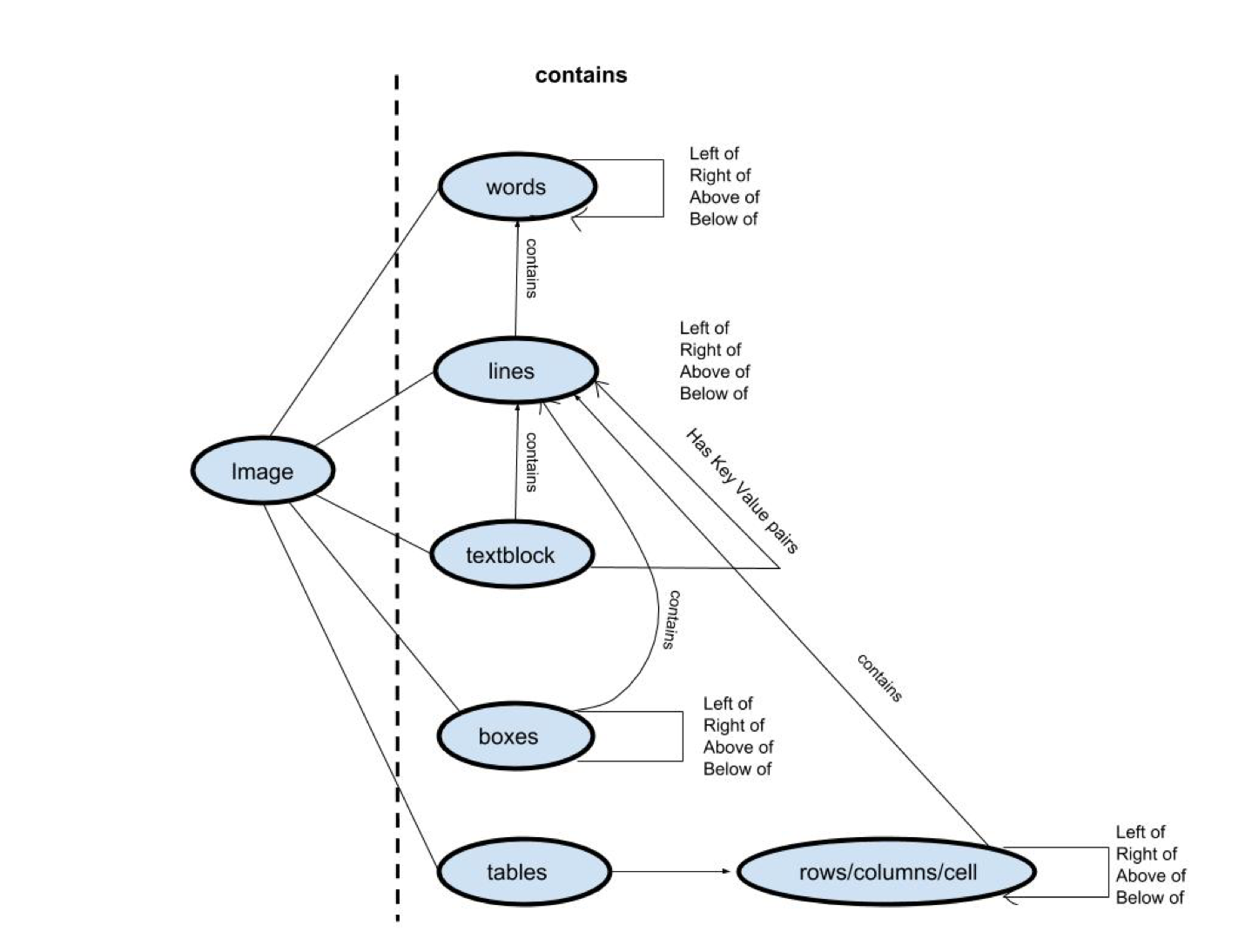
After pre-processing, Deep Reader detects a set of entities from the picture, together with web page traces, textual content blocks, traces of textual content blocks, and containers. The detection goes by way of the schema, as proven within the above determine to retrieve a complete set of information from the scanned doc.
Rule-based strategies offered by area specialists are additionally adopted to help the extraction course of. For instance, Deep Reader makes use of summary common information sorts equivalent to metropolis, nation, and date to make sure that the fields retrieved are related.
Let’s apply our theoretical information to a sensible downside. We’ll give attention to a typical but difficult situation: extracting firm, handle, and worth fields from invoices. Whether or not you are a small enterprise proprietor monitoring bills or a knowledge scientist automating doc processing, this implementation will provide you with a stable basis.
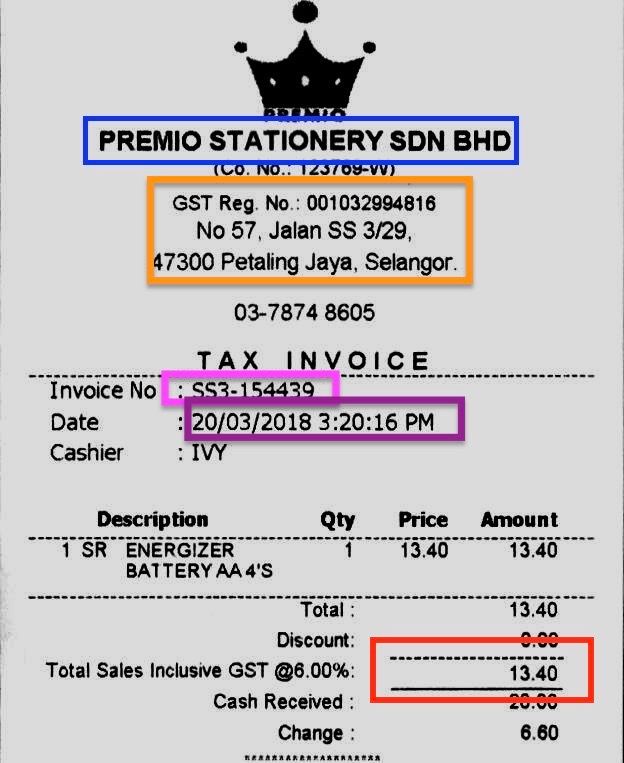
The determine above is an ordinary bill template saved in a picture format. We’ve many of those invoices with related codecs, however manually discovering the KVPs, equivalent to the corporate title, handle, and whole worth, is a tiring job. Thus, the purpose is to design a KVP extractor such that with a given format (or related codecs), we will robotically retrieve and current the KVPs.
To carry out KVP extraction, we are going to want an OCR library and a picture processing library. We’ll use the notorious openCV library for picture studying and processing and the PyTesseract library for OCR. The PyTesseract library is a wrapper of the aforementioned Google Tesseract engine, which will likely be enough for our job.
*Aspect Notice: This system is predicated on the resolution of the ICDAR Robusting Studying Problem
Half I — Libraries
You should use pip to put in the 2 libraries by way of the next instructions:
https://gist.github.com/ttchengab/c040ab7ce44114d76c63ecef226d5d09
After set up, we will then import the libraries as the next:
https://gist.github.com/ttchengab/cd32bcd502e99c3e3cc9c73f693927c7
We will even must import some exterior libraries:
https://gist.github.com/ttchengab/01280236448e4fc4a03505f6f0baea3f
Half II — Picture Preprocessing
https://gist.github.com/ttchengab/293fc3ca782b20cf9b05c33f13583338
The perform above is our picture preprocessing for textual content retrieval. We comply with a two stage strategy to perform this:
Firstly, we make the most of the cv2.imread() perform to retrieve the picture for processing. To extend the readability of the texts within the picture, we carried out picture dilation adopted by noise elimination utilizing some cv2 capabilities. Some extra capabilities for picture processing can be listed within the remark part. Then, we discover contours from the picture and based mostly on the contours we discover the bounding rectangles.
Secondly, after picture processing, we then iteratively retrieve every bounding field and use the pytesseract engine to retrieve retrieve all of the textual content info to feed right into a community for KVP extraction.
https://gist.github.com/ttchengab/b81ea8bb1c21121237845d65d15aa3a0
The mannequin above is an easy LSTM that takes the texts as inputs and outputs the KVPs of firm title, date, handle, and whole. We adopted the pre-trained mannequin from the resolution for testing.
The next are the analysis capabilities for the LSTM community with a given set of texts:
https://gist.github.com/ttchengab/9f31568ef1b916ab0ee74ac1b8b482e5
Half IV – Whole Pipeline
https://gist.github.com/ttchengab/c2f7614cbeaa8cd14883d4ebbcd36ba6
With all of the capabilities and libraries applied, your complete pipeline of KVP extraction could be achieved with the above code. Utilizing the bill above, we may efficiently retrieve the corporate title and the handle as the next:

To check the robustness of our mannequin, we will additionally check on invoices with unseen codecs, equivalent to the next:
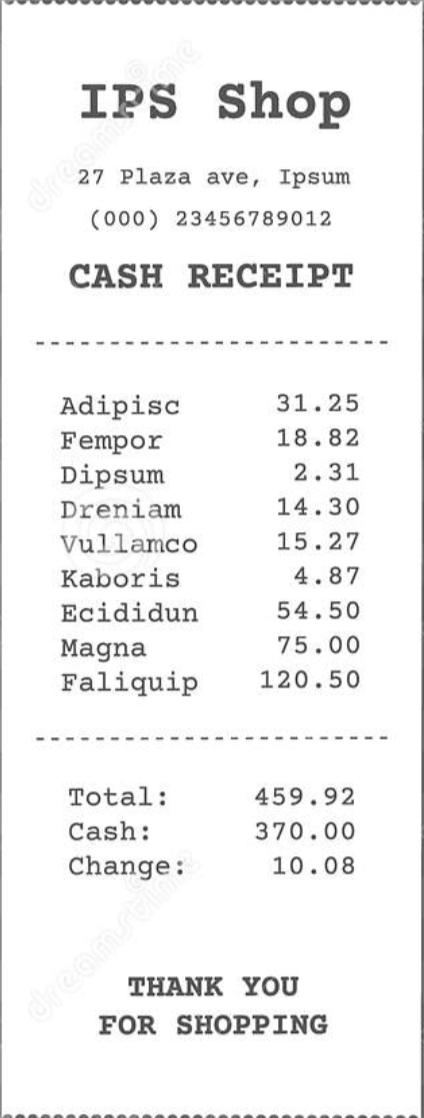
Through the use of the identical pipeline, with out additional coaching, we may receive the next:

Regardless that we could not retrieve different info equivalent to firm title or handle, we had been nonetheless in a position to receive the whole accurately with out ever seeing any related bill codecs earlier than!
With an understanding of the mannequin structure and pipeline, now you can use extra bill codecs which can be extra related as coaching and proceed to coach the mannequin in order that it might work with larger confidence and accuracy.
Finest practices and optimization strategies for Key-Worth Extraction
Implementing an efficient key worth pair extraction system is not nearly writing code; it is about optimizing your strategy for accuracy, effectivity, and scalability. Listed below are some greatest practices to supercharge your extraction course of:
- Clear your pictures: Take away noise, right skew, and improve distinction.
- Standardize codecs: Convert all paperwork to a constant format earlier than processing.
- Create customized dictionaries: Construct lists of anticipated keys for particular doc sorts.
- Use common expressions: Design patterns to catch widespread worth codecs (e.g., dates, foreign money).
- Validate extracted information: Arrange checks to make sure extracted values make sense.
- Deal with exceptions: Plan for sudden doc codecs or OCR errors.
- Use parallel processing: Distribute extraction duties throughout a number of cores or machines.
- Implement caching: Retailer incessantly accessed information to cut back processing time.
- Implement suggestions loops: Allow customers to right errors, feeding this information again into your system.
- Commonly replace your fashions: Retrain on new information to enhance accuracy over time.
- Encrypt delicate information: Shield extracted info, particularly when coping with private or monetary particulars.
- Implement entry controls: Guarantee solely licensed personnel can entry extracted information.
What’s a Key-Worth Database?
Whereas we have explored the intricacies of key worth pair extraction, it is essential to know the place this information typically finally ends up: key-value databases. These highly effective methods assist many fashionable purposes, from e-commerce platforms to social media networks.
A key-value database, often known as a key-value retailer, is a kind of non-relational database that makes use of a easy key-value methodology to retailer information. Every merchandise within the database is saved as an attribute title (or “key”) along with its worth.
Key-Worth vs. Relational Databases
Conventional relational databases set up information into tables with predefined schemas. In distinction, key-value databases supply extra flexibility:
- Schema-less: Key-value databases do not require a hard and fast schema, permitting for straightforward modifications.
- Scalability: They’ll deal with huge quantities of information and visitors extra effectively.
- Efficiency: For easy queries, key-value databases typically outperform relational databases.
As we have explored the complexities of key-value pair extraction, it is clear that implementing a sturdy resolution requires important experience. That is the place platforms like Nanonets shine, providing a highly effective OCR API that simplifies the extraction course of.
Nanonets leverages cutting-edge AI to offer:
- Pre-trained fashions for widespread paperwork like invoices, receipts, and ID playing cards
- Customized coaching capabilities to your distinctive doc codecs
- Excessive accuracy on each printed and handwritten textual content
- Seamless integration by way of a RESTful API
- Versatile post-processing guidelines to refine extracted information
For organizations seeking to rapidly implement key worth extraction with out compromising on high quality, Nanonets presents a compelling resolution. By dealing with the complexities of AI mannequin improvement and upkeep, Nanonets permits companies to give attention to what actually issues – deriving worth from their doc information.
Whether or not you are a startup processing your first batch of invoices or an enterprise dealing with thousands and thousands of paperwork, platforms like Nanonets are making superior key worth extraction accessible and environment friendly.
Last ideas
We have coated loads of floor on key-value pair extraction. We have explored the idea of KVPs, their use circumstances, and varied extraction strategies – from conventional OCR to cutting-edge deep studying approaches. However bear in mind, there’s nonetheless an extended method to go.
This discipline is continually evolving, with AI and machine studying pushing the boundaries of what is potential. As we wrap up, take into account how one can apply these insights to your personal doc processing challenges.
Additional studying
[ad_2]