
{kind=link}

[ad_1]
Synthetic intelligence (AI) has seen important developments by means of game-playing brokers like AlphaGo, which achieved superhuman efficiency by way of self-play methods. Self-play permits fashions to enhance by coaching on information generated from video games performed in opposition to themselves, proving efficient in aggressive environments like Go and chess. This system, which pits similar copies of a mannequin in opposition to one another, has pushed AI capabilities past human efficiency in these zero-sum video games.
A persistent problem in AI is enhancing efficiency in cooperative or partially cooperative language duties. Not like aggressive video games, the place the target is clear-cut, language duties usually require collaboration and sustaining human interpretability. The difficulty is whether or not self-play, profitable in aggressive settings, may be tailored to enhance language fashions in duties the place cooperation with people is important. This entails guaranteeing that AI can talk successfully and perceive nuances in human language with out deviating from pure, human-like communication methods.
Current analysis contains fashions like AlphaGo and AlphaZero, which use self-play for aggressive video games. Collaborative dialogue duties like Playing cards, CerealBar, OneCommon, and DialOp consider fashions in cooperative settings utilizing self-play as a proxy for human analysis. Negotiation video games like DoND and Craigslist Bargaining check fashions’ bartering talents. Nonetheless, these frameworks usually battle with sustaining human language interpretability and fail to generalize methods successfully in combined cooperative and aggressive environments, limiting their real-world applicability.
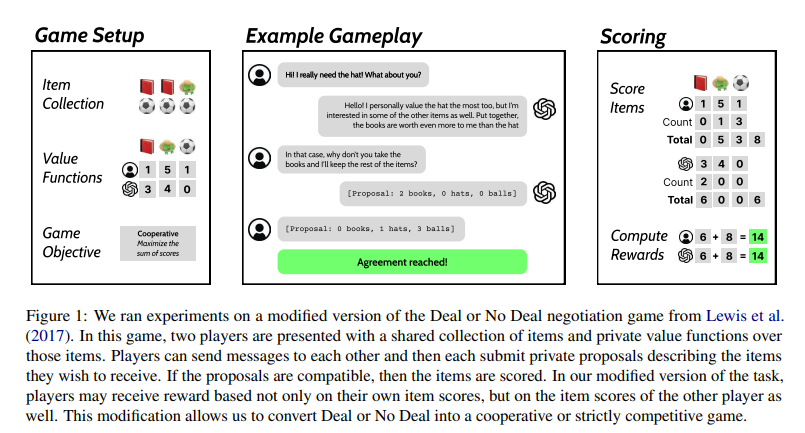
Researchers from the College of California, Berkeley, launched a novel method to check self-play in cooperative and aggressive settings utilizing a modified model of the negotiation sport Deal or No Deal (DoND). This sport, initially semi-competitive, was tailored to help numerous aims, making it appropriate for evaluating language mannequin enhancements throughout completely different collaboration ranges. By modifying the reward construction, the sport might simulate totally cooperative, semi-competitive, and strictly aggressive environments, offering a flexible testbed for AI coaching.
Within the modified DoND sport, two gamers negotiate merchandise division with non-public worth capabilities. The sport adjusts to cooperative, semi-competitive, or aggressive settings. Researchers used filtered habits cloning for self-play coaching. Two similar language fashions performed 500 video games per spherical over ten rounds, with high-scoring dialogues used for finetuning. Preliminary fashions, together with GPT-3.5 and GPT-4, had been evaluated with out few-shot examples to keep away from bias. The OpenAI Health club-like surroundings managed sport guidelines, message dealing with, and rewards. Human experiments had been performed on Amazon Mechanical Turk with pre-screened staff to validate mannequin efficiency.
The self-play coaching led to important efficiency enhancements. In cooperative and semi-competitive settings, fashions confirmed substantial good points, with scores enhancing by as much as 2.5 instances in cooperative and 6 instances in semi-competitive eventualities in comparison with preliminary benchmarks. Particularly, fashions educated within the cooperative setting improved from a mean rating of 0.7 to 12.1, whereas within the semi-competitive setting, scores elevated from 0.4 to five.8. This demonstrates the potential of self-play to boost language fashions’ capability to cooperate and compete successfully with people, suggesting that these methods may be tailored for extra advanced, real-world duties.
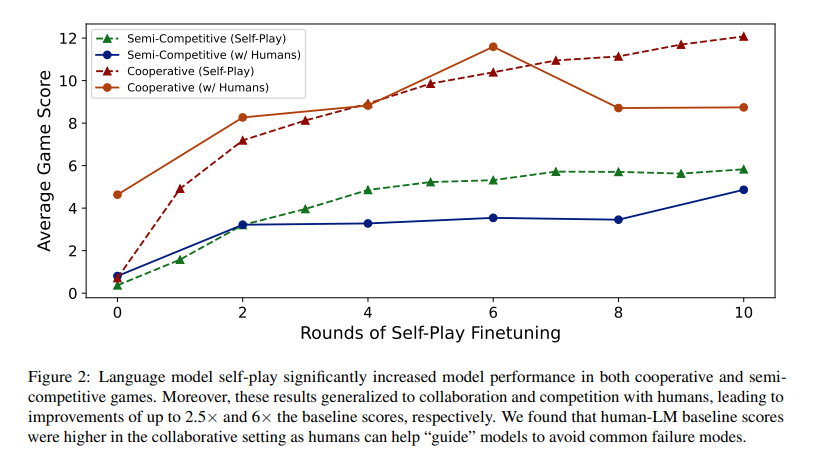
Regardless of the promising ends in cooperative and semi-competitive environments, the strictly aggressive setting posed challenges. Enhancements had been minimal, indicating that fashions tended to overfit throughout self-play. On this setting, fashions usually struggled to generalize their methods, failing to achieve legitimate agreements with different brokers, comparable to GPT-4. Preliminary human experiments additional confirmed that these fashions not often achieved agreements, highlighting the problem of making use of self-play in zero-sum eventualities the place strong, generalizable methods are essential.
To conclude, this analysis, performed by the College of California, Berkeley workforce, underscores the potential of self-play in coaching language fashions for collaborative duties. The findings problem the prevailing assumption that self-play is ineffective in cooperative domains or that fashions want in depth human information to take care of language interpretability. As a substitute, the numerous enhancements noticed after simply ten rounds of self-play recommend that language fashions with good generalization talents can profit from these methods. This might result in broader functions of self-play past aggressive video games, probably enhancing AI’s efficiency in numerous collaborative and real-world duties.
Try the Paper and Code. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 45k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
[ad_2]