
{kind=link}

Introduction to Table extraction
Extracting tables from documents may sound straightforward, but in reality, it is a complex pipeline involving parsing text, recognizing structure, and preserving the precise spatial relationships between cells. Tables carry a wealth of information compacted into a grid of rows and columns, where each cell holds context based on its neighboring cells. When algorithms attempt to extract these tables, they must carefully navigate the table’s layout, hierarchies, and unique formats—all of which bring forth technical challenges.
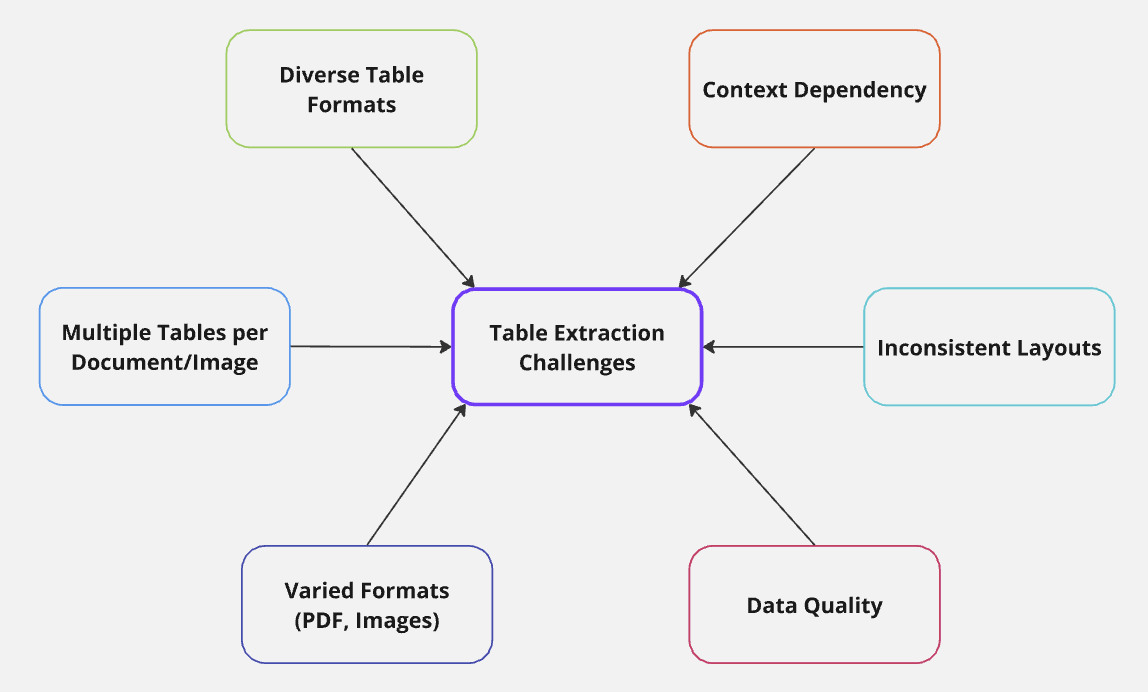
One way to tackle these complexities is by analyzing table structures for similarities, allowing us to group or compare tables based on features like content in cells, row-column arrangement, additional/missing rows and columns. But to truly capture an algorithm’s performance in table extraction, we need specialized metrics that go beyond traditional accuracy scores.
This post dives into table extraction evaluation, beginning with the essential components and metrics for gauging extraction quality. We’ll explore foundational metrics and then venture into advanced techniques designed specifically for tables, such as TEDS (Tree Edit Distance-based Similarity) and GRITS (Grid-based Recognition of Information and Table Structure).
Roadmap for the Post:
• Understanding Table Extraction: Core components and unique challenges.
• Basic Metrics: Starting metrics for assessing extraction quality.
• Advanced Metrics: A deep dive into TEDS and GRITS.
• Conclusion: Insights on matching metrics to specific use cases.
Let’s unpack what makes table extraction so challenging and find the best metrics to assess it!
Understanding Table Structure and Complexity
This guide provides an overview of the fundamental and advanced structural elements of a table, focusing on how they contribute to its organization and interpretability.
Basic Elements of a Table
- Rows
- This is generally the horizontal component in a table.
- Every row represents a single item/entity/observation in the data, essentially grouping different characteristics or facets of that one item.
- The information in the row is expected to be heterogeneous, i.e., the data across cells in a single row is going to be of dissimilar things.
- Columns
- This is generally the vertical component in the table.
- Columns organize similar characteristics or attributes across multiple items, and provide a structured view of comparable information for every item.
- The information in the column is expected to be homogenous, i.e., the data across cells in a single column is expected to be of similar nature/type.
- Cells
- This is the fundamental building block of a table, and is usually the intersection between a row and a column, where individual data points reside.
- Each cell is uniquely identified by its position within the row and column and often contains the raw data.
- Headers
- Headers are part of the table and are usually either the first row or the first column, and help orient the reader to the structure and content of the table.
- These act as labels for rows or columns that add interpretive clarity, helping define the type or meaning of the data in those rows or columns.
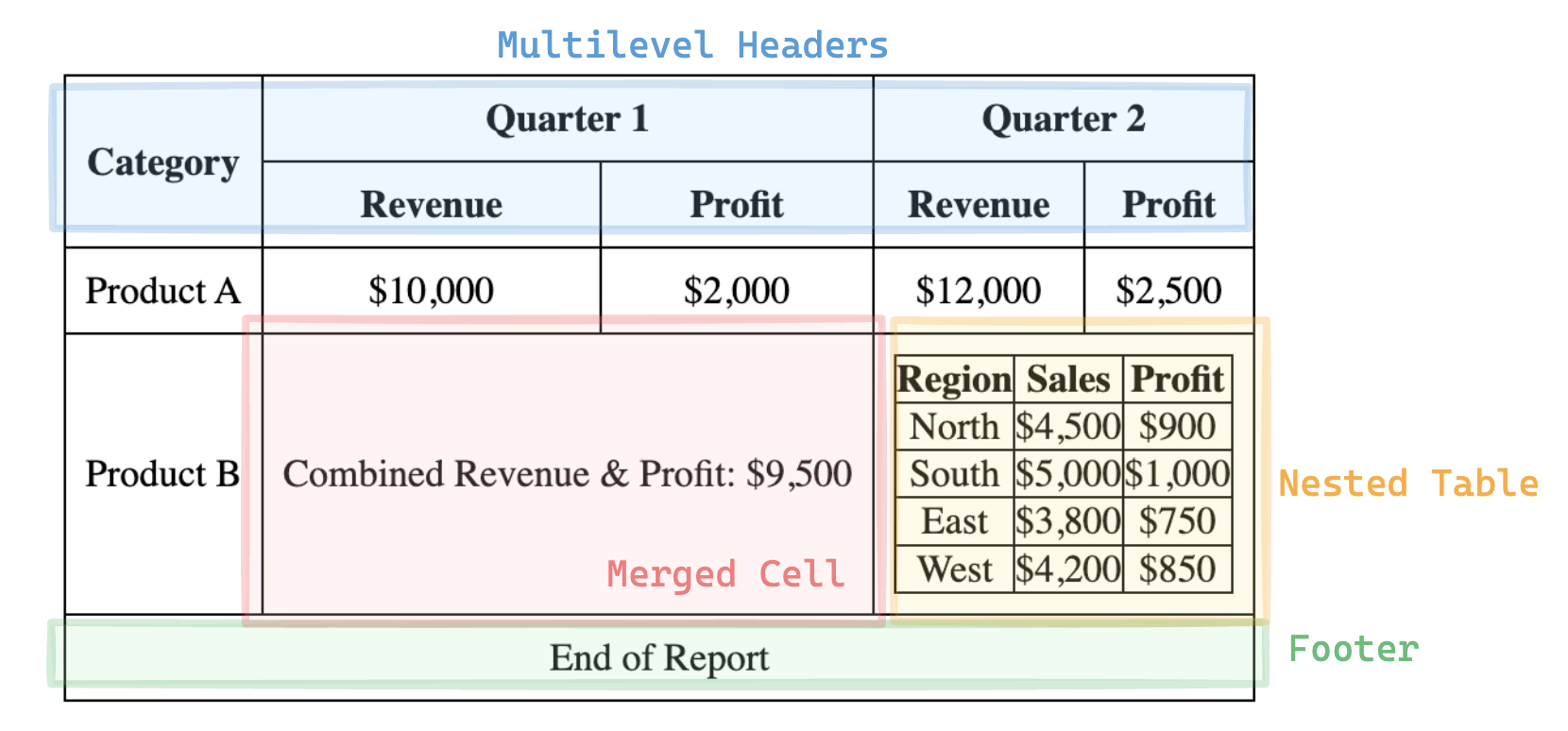
Advanced Elements of a Table
- Merged Cells
- Cells that span multiple rows or columns to represent aggregated or hierarchical data.
- These are often used to emphasize relationships, such as categories encompassing multiple subcategories, adding a layer of hierarchy.
- Nested Tables
- Sometimes there are tables within a cell that provide additional, detailed data about a specific item or relationship.
- These may require distinct interpretation and handling, especially in automated processing or screen reader contexts.
- Multi-Level Headers
- A hierarchy of headers stacked in rows or columns to group related attributes.
- Multi-level headers create more nuanced grouping, such as categorizing columns under broader themes, which may require special handling to convey.
- Annotations and Footnotes
- Additional markers, often symbols or numbers, providing context or clarification about certain cells or rows.
- Footnotes clarify exceptions or special cases, often essential for interpreting complex data accurately.
- Empty Cells
- Cells without data that might imply the absence, irrelevance, or non-applicability of data.
- Empty cells carry implicit meaning and may serve as placeholders, so they must be treated thoughtfully to avoid misinterpretation.
- Dynamic Cells
- Cells that may contain formulas or references to external data, frequently updated or recalculated.
- These cells are common in digital tables (e.g., spreadsheets) and require the interpreter to recognize their live nature
These elements together define a table’s structure and usability. With this knowledge let’s start creating metrics that can indicate if two tables are similar or not.
Basic Measurements and Their Drawbacks
Having explored the various components in the table, you should now recognize the complexity of both tables and table extraction. We will delve deeper to establish metrics that help measure table extraction accuracy while also discussing their limitations. Throughout this discussion, we will compare two tables: the ground truth and the prediction, examining their similarities and how we can quantify them.
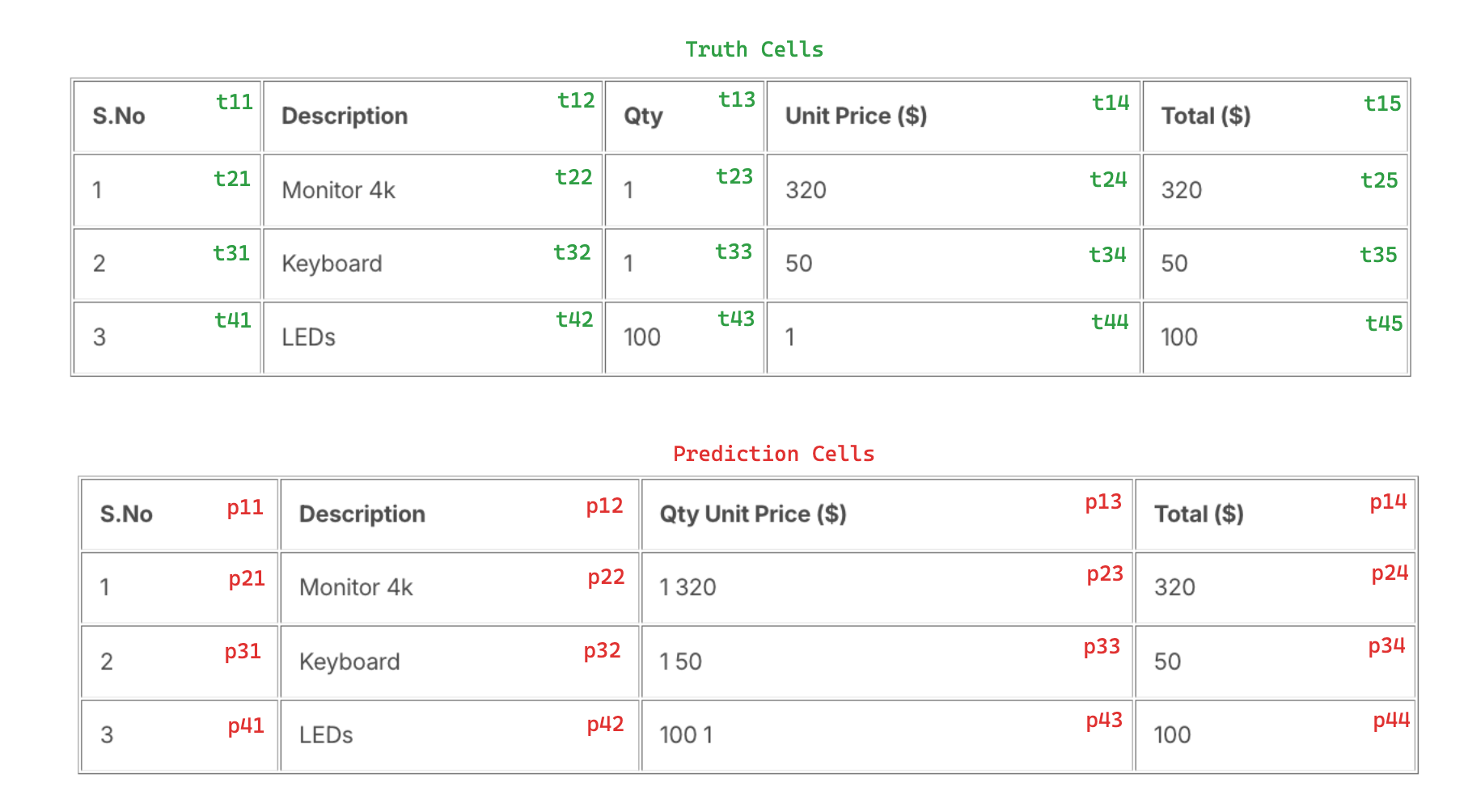
The ground truth is:
| S.No | Description | Qty | Unit Price ($) | Total ($) |
|---|---|---|---|---|
| 1 | Monitor 4k | 1 | 320 | 320 |
| 2 | Keyboard | 1 | 50 | 50 |
| 3 | LEDs | 100 | 1 | 100 |
The prediction is:
| S.No | Description | Qty Unit Price ($) | Total ($) |
|---|---|---|---|
| 1 | Monitor 4k | 1 320 | 320 |
| 2 | Keyboard | 1 50 | 50 |
| 3 | LEDs | 100 1 | 100 |
Extra Rows
One of the simplest metrics to evaluate is the table’s shape. If the predicted number of rows exceeds the expected count, we can calculate the extra rows as a fraction of the expected total:
\[\text{extra_rows} = \frac{max(0, rows_{pred} – rows_{truth})}{rows_{truth}}\]
In our case \(\text{extra_rows} = 0\)
Missing Rows
Similarly, we can compute the missing rows:
\[\text{missing_rows} = \frac{\max(0, \text{rows}_{truth} – \text{rows}_{pred})}{\text{rows}_{truth}}\]
In our case \(\text{missing_rows} = 0\)
Missing and Extra Columns
We can also calculate missing and extra columns using similar formulas as those above that indicate the shortcomings of the predictions.
In our case \(\text{extra_cols} = 0\) and \(\text{missing_cols} = 1\)
Table Shape Accuracy
If the number of rows and columns in the truth and prediction are identical, then the table shape accuracy is 1. Since there are two dimensions to this metric, we can combine them as follows:
\[\begin{align}
\text{table_rows_accuracy} &= 1 – \frac{|\text{rows}_{truth} – \text{rows}_{pred}|}{\max(\text{rows}_{truth}, \text{rows}_{pred})} \\
\text{table_cols_accuracy} &= 1 – \frac{|\text{cols}_{truth} – \text{cols}_{pred}|}{\max(\text{cols}_{truth}, \text{cols}_{pred})} \\
\frac{2}{\text{tables_shape_accuracy}} &= \frac{1}{\text{table_rows_accuracy}} + \frac{1}{\text{table_cols_accuracy}}
\end{align}\]
In our case, the table shape accuracy would be \(\frac{8}{9}\), indicating that approximately 1 in 9 rows+columns is missing or added.
This metric serves as a necessary condition for overall table accuracy; if the shape accuracy is low, we can conclude that the predicted table is poor. However we can’t conclude the same if table accuracy is high since the metric does not take the content of cells into account.
Exact Cell Text Precision, Recall, and F1 Score
We can line up all the cells in a specific order (e.g., stacking all the rows left to right in a single line) for both the truth and predictions, measuring whether the cell contents match.
Using the example above, we could create two lists of cells arranged as follows –

and based on the perfect matches, we can compute the precision and recall of the table.
In this case, there are 12 perfect matches, 20 cells in the truth, and 16 cells in the prediction. The total precision would be \(\frac{12}{16}\), recall would be \(\frac{12}{20}\), making the F1 score \(\frac{2}{3}\), indicating that approximately one in every three cells is incorrect.
The main drawback of this metric is that the order of perfect matches is not considered, which means we could theoretically achieve a perfect match even if the row and column orders are shuffled in the prediction. In other words, the layout of the table is completely ignored by this metric. Additionally, this metric assumes that the predicted text perfectly matches the truth, which is not always the case with OCR engines. We will address this assumption using the next metric.
Fuzzy Cell Text Precision, Recall, and F1 Score
The calculation remains the same as above, with the only change being the definition of a match. In a fuzzy match, we consider a truth text and a predicted text as a match if the two strings are sufficiently similar. This can be accomplished using the fuzzywuzzy library.

In this example, there are 4 additional matches boosting the precision to 1, recall to \(\frac{16}{20}\) and F1 score to 0.89
This metric is advisable only when there is tolerance for minor spelling mistakes.
IOU Based Cell Matching
Instead of lining up the texts and guessing a match between ground truth cells and prediction cells, one can also use Intersection over Union of all the bounding boxes in truth and predictions to associate truth cells with pred cells.
Using above nomenclature one can compute IOUs of the 20 truth cells with the 16 prediction cells to get a \(20 \times 16\) matrix
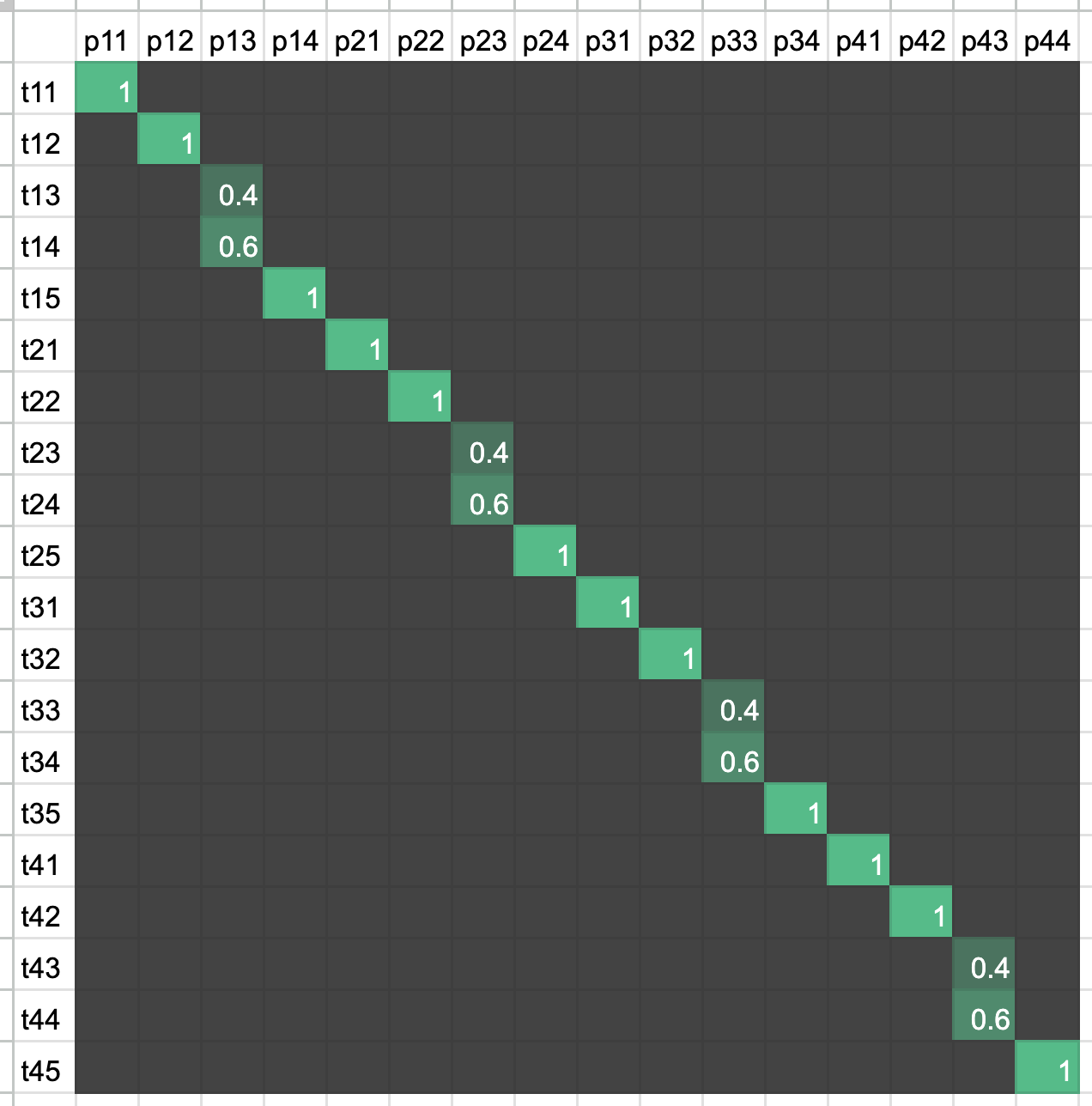
We can define the criteria for a perfect match as
- An IOU score above a threshold, say 0.95, and
- text in truth and predictions are identical.
In above case the prefect match score would be \(\frac{12}{20}\), i.e., two in five cells are predicted wrong
Prediction cells that have multiple IOUs with ground truths can be considered as false positive candidates and ground truth cells that have multiple IOUs with predictions can be considered as false negative candidates. However, accurately measuring recall and precision is challenging because multiple true cells may overlap with multiple predicted cells and vice versa making it hard to tell if a cell is false positive or false negative or both.
IOU Based Fuzzy Cell Matching
A similar metric as above can be created but this time the criteria for perfect match can be
- high IOU score between cells, and
- text in truth and prediction cells are sufficiently similar with a threshold
This fuzziness accounts for OCR inaccuracies. And in our example the accuracy would be \( \frac{16}{20} \), i.e., one in five cells is wrong.
Column Level Accuracy
Because every cell belongs to a specific column, one can calculate the cell accuracy at a column level. When columns have different business significances and downstream pipelines, one can take decisions based on individual column accuracies without worrying about the rest of the table performance
In our example the column level accuracy would be –
{
S.No: 1.0
Description: 1.0
Qty: 0.0
Unit Price ($): 0.0
Total ($): 1.0
}Column Level Accuracies
giving an indication that the table extraction works perfectly for 3 of the 5 columns.
Straight Through Processing (STP)
Unlike the other metrics, which were always talking about metrics at a table level, STP is a dataset level metric which is the fraction of tables that had a metric of 1 amongst all the tables. Whether the metric is Cell Accuracy or TEDS or GriTS or something else is up to you.
The motivation behind this metric is simple – what fraction of predicted tables do not need any human intervention. Higher the fraction, better is the table extraction system.
So far, we’ve explored metrics that address specific dimensions of table extraction, such as the absence of rows or columns and exact cell matches. These metrics are straightforward to code and communicate, and they are effective for evaluating simple tables. However, they don’t offer a comprehensive picture of the extraction. For instance, except for IOU based metrics, none of the metrics account for row or column order, nor do they address row and column spans. And it was hard to compute precision and recall in IOU based metrics. In the next section, we’ll examine metrics that consider the table as a whole.
Advanced Metrics
In this section, we’ll discuss two of the most advanced algorithms for table extraction evaluation: TEDS and GriTS. We’ll dive into the details of each algorithm and explore their strengths and limitations.
Tree Edit Distance based Similarity (TEDS)
The Tree Edit Distance based Similarity (TEDS) metric is based on the observation that tables can be represented as HTML structures, making it possible to measure similarity by comparing the trees of two HTML representations.
For example, the ground truth table can be represented in HTML as:
<table border="1" cellspacing="0">
<thead>
<tr>
<th>S.No</th>
<th>Description</th>
<th>Qty</th>
<th>Unit Price ($)</th>
<th>Total ($)</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan=1 colspan=1>1</td>
<td>Monitor 4k</td>
<td>1</td>
<td>320</td>
<td>320</td>
</tr>
<tr>
<td>2</td>
<td>Keyboard</td>
<td>1</td>
<td>50</td>
<td>50</td>
</tr>
<tr>
<td>3</td>
<td>LEDs</td>
<td>100</td>
<td>1</td>
<td>100</td>
</tr>
</tbody>
</table>
HTML representation of a table – <tr> = Row, <td> = Data, <th> = Header. All cells have optional <colspan> and <rowspan> tags indicating the length and height of the cells within the table. Implicitly rowspan and colspan are 1
In HTML, tables follow a tree structure. The root node has two main branches, and, grouping the table header and body. Each row is a child node within these branches, and table cells are leaf nodes, each with attributes like colspan, rowspan, and content.
The TEDS metric calculates similarity by finding the tree-edit distance between two table structures using the following rules:
- Insertions and deletions incur a cost of 1.
- Substitutions cost 1 if either node is not a
td, i.e., cell. - If both nodes are elements, substitution costs are as follows:
- Cost of 1 if the
colspanorrowspandiffers. - Normalized Levenshtein edit distance between truth and predicted cell texts, when the cells’
colspanandrowspanare identical.
- Cost of 1 if the
The final TEDS score is calculated as the edit distance divided by the total number of cells in the larger table:
\[\text{TEDS}(T_a, T_b) = 1 – \frac{\text{EditDist}(T_a, T_b)}{\max(|T_a|, |T_b|)}\]
For a reference implementation of these rules, see this TEDS class.
Key Intuition Behind TEDS
- Insertions and deletions account for missing or extra rows and columns by penalizing changes in table structure.
- Substitutions penalize differences in colspan and rowspan, capturing any disparities in cell layout.
- Text mismatches (e.g., OCR errors) are managed by using the edit distance between content in corresponding cells.
In our example, the ground truth has 26 nodes (1 <thead>, 1 <tbody>, 4 <tr> and 20 <td> tags) and prediction has 22 nodes.
- The number of tree edits needed is 4 insertions (one <td> tag in each row)
- The number of <td> edits needed are 4 and the cost of each edit is
- \( \frac{4}{18} \) – to make “Qty Unit Price ($)” to “Unit Price ($)”
- \( \frac{2}{5} \) – to make “1 1320” to “320”
- \( \frac{2}{4} \) – to make “1 50” to “50”
- \( \frac{4}{5} \) – to make “100 1” to “100”
Thus the total Tree Edit Distance is 4 + 1.93 and the TEDS score is \( 1 – \frac{5.93}{22} = 0.73\)
By incorporating both structural and textual differences, TEDS provides a more holistic metric. However, there is one notable drawback: rows and columns are not treated equally. Due to the tree structure, missing rows incur a higher penalty than missing columns, as rows tr occupy a higher level in the hierarchy than cells td, which implicitly represent columns. For example, when we remove a column from a table with 5 rows, the tree edit distance is 5 (which are all <td>s), but when we remove a row, the tree edit distance is 6 since there is an extra <tr> tag that needs to be added.
Example
To illustrate, consider the following cases from this document set tested with TEDS on the following three cases:
- Perfect Match: Truth and prediction tables are identical.
- Missing Row: The prediction table has the last row omitted.
- Missing Column: The prediction has a column ommitted.
Results:
{'full-table': 1.0, 'missing-columns': 0.84375, 'missing-rows': 0.8125}As seen, missing rows incur a higher penalty than missing columns.
To address this limitation, we’ll explore the final metric of this article: GriTS.
Grid Table Similarity (GriTS)
The driving insight behind Grid Table Similarity (GriTS) is that tables can be viewed as 2D arrays, and two such arrays should share a largest common substructure.
Understanding Largest Common Substructure
Consider the following example:
Array 1: 0 1 3 4 5 6 7 8 11 12
Array 2: 1 2 3 4 5 7 8 9 10
Despite differences in these sequences, they share a longest common subsequence (LCS)
Largest Common Subsequence: 1 3 4 5 7 8
And here is the crux of GriTS –
1. Compute the longest common subsequence (LCS) between the truth and prediction sequences.
2. This LCS reveals which items are missing in the truth sequence and which are extra in the prediction.
3. Calculate precision, recall and f-score based on these missing and extra items.
In this simplistic case, recall is \(\frac{6}{10}\) and precision is \(\frac{6}{9}\) making the f1 score \(0.6315\)
While computing LCS for one-dimensional arrays is straightforward, the 2D-Longest Common Subsequence (2D-LCS) problem is NP-hard, making exact calculations impractical. GriTS therefore approximates this with the “Factored 2D-Maximum Similar Subsequence” (2D-MSS), using a heuristic approach with nested dynamic programming (DP), calling it Factored 2D-MSS Approach
The 2D-MSS algorithm works by independently aligning rows and columns:
- Row Alignment (Inner DP): Aligns cells within row pairs to compute alignment scores for predicted vs. ground truth rows.
- Column Alignment (Outer DP): Uses the row alignment scores to find the best match across rows, then repeats this for columns.
Flexible Matching Criteria
In the 1D example above, two numbers match if they are equal. Extending this naively to 2D tables could lose cell matches where OCR errors result in small discrepancies. To address this, GriTS introduces flexible matching criteria:
- GriTS-Content: Matches cells based on the edit distance between their textual content.
- GriTS-Topology: Matches cells with identical row-span and column-span values.
- GriTS-Location: Matches cells based on Intersection over Union (IoU) of their spatial coordinates. This metric is especially useful to judge if the borders of the cells are predicted well.
These criteria allow GriTS to adapt to various sources of errors, making it a powerful and versatile metric for table extraction evaluation.
Observe that there is no special preference given to either rows or columns. Hence with same test document set that we used in TEDS section, we get an even 0.89 GriTS-Content score for both cases, i.e., missing row and missing column.
# git clone https://github.com/microsoft/table-transformer /Codes/table-transformer/
# sys.path.append('/Codes/table-transformer/src/')
from grits import *
t = ['S.No,Description,Qty,Unit Price ($),Total ($)','1,Monitor 4k,1,320,320','2,Keyboard,1,50,50','3,LEDs,100,1,100','4,MiniLEDs,100,1,100']
t = [r.split(',') for r in t]
t = np.array(t)
p = t[[0,1,2,3],:]
# grits_con provides precision, recall and f-score in one go and we are print the f-score here.
print(grits_con(t, p)[-1])
# 0.8888888888
p = t[:,[0,1,2,4]]
print(grits_con(t, p)[-1])
# 0.8888888888
Overall GriTS computes the largest overlap of ground truth table and predictions table, giving a clear indication of additional and missing rows and columns in one shot. The criteria for computing the overlap is made flexible to compute the goodness of predictions along several criteria such as content match, location match and order match, thereby addressing all the table extraction concerns in one go.
Conclusion
Table extraction from documents presents significant technical challenges, requiring careful handling of text, structure, and layout to accurately reproduce tables in digital form. In this post, we explored the complexity of table extraction and the need for specialized evaluation metrics that go beyond simple accuracy scores.
Starting with basic metrics that assess cell matches and row/column alignment, we saw how these provide valuable yet limited insights. We then examined advanced metrics—TEDS and GriTS—that address the full structure of tables. TEDS leverages HTML tree representations, capturing the overall table layout and minor text errors, but has limitations in treating rows and columns equally. GriTS, on the other hand, frames tables as 2D arrays, identifying the largest common substructure between truth and prediction while incorporating flexible matching criteria for content, structure, and spatial alignment.
Ultimately, each metric has its strengths, and their suitability depends on the specific needs of a table extraction task. For applications focused on preserving table structure and handling OCR errors, GriTS provides a robust, adaptable solution.
We recommend using GriTS as a comprehensive metric, and simpler metrics like cell accuracy or column-level accuracy when it’s important to highlight specific aspects of table extraction.
Want to go beyond simple table extraction and ask questions to your tables? Tools such as Nanonets’ Chat with PDF use SOTA models and can offer a reliable way to interact with content, ensuring accurate data extraction without risk of misrepresentation.