
{kind=link}

[ad_1]
Massive Language Fashions (LLMs) like ChatGPT and GPT-4 have made vital strides in AI analysis, outperforming earlier state-of-the-art strategies throughout varied benchmarks. These fashions present nice potential in healthcare, providing superior instruments to boost effectivity by pure language understanding and response. Nevertheless, the combination of LLMs into biomedical and healthcare purposes faces a crucial problem: their vulnerability to malicious manipulation. Even commercially obtainable LLMs with built-in safeguards may be deceived into producing dangerous outputs. This susceptibility poses vital dangers, particularly in medical environments the place the stakes are excessive. The issue is additional compounded by the potential for knowledge poisoning throughout mannequin fine-tuning, which might result in refined alterations in LLM habits which are tough to detect below regular circumstances however manifest when triggered by particular inputs.
Earlier analysis has explored the manipulation of LLMs on the whole domains, demonstrating the potential for influencing mannequin outputs to favor particular phrases or suggestions. These research have usually centered on easy eventualities involving single set off phrases, leading to constant alterations within the mannequin’s responses. Nevertheless, such approaches usually oversimplify real-world situations, significantly in advanced medical environments. The applicability of those manipulation strategies to healthcare settings stays unsure, because the intricacies and nuances of medical data pose distinctive challenges. Moreover, the analysis neighborhood has but to completely examine the behavioral variations between clear and poisoned fashions, leaving a big hole in understanding their respective vulnerabilities. This lack of complete evaluation hinders the event of efficient safeguards in opposition to potential assaults on LLMs in crucial domains like healthcare.
On this work researchers from the Nationwide Middle for Biotechnology Data (NCBI), Nationwide Library of Medication (NLM) and the College of Maryland at Faculty Park, Division of Laptop Science intention to analyze two modes of adversarial assaults throughout three medical duties, specializing in fine-tuning and prompt-based strategies for attacking commonplace LLMs. The research makes use of real-world affected person knowledge from MIMIC-III and PMC-Sufferers databases to generate each commonplace and adversarial responses. The analysis examines the habits of LLMs, together with proprietary GPT-3.5-turbo and open-source Llama2-7b, on three consultant medical duties: COVID-19 vaccination steering, treatment prescribing, and diagnostic take a look at suggestions. The goals of the assaults in these duties are to discourage vaccination, counsel dangerous drug mixtures, and advocate for pointless medical checks. The research additionally evaluates the transferability of assault fashions educated with MIMIC-III knowledge to actual affected person summaries from PMC-Sufferers, offering a complete evaluation of LLM vulnerabilities in healthcare settings.
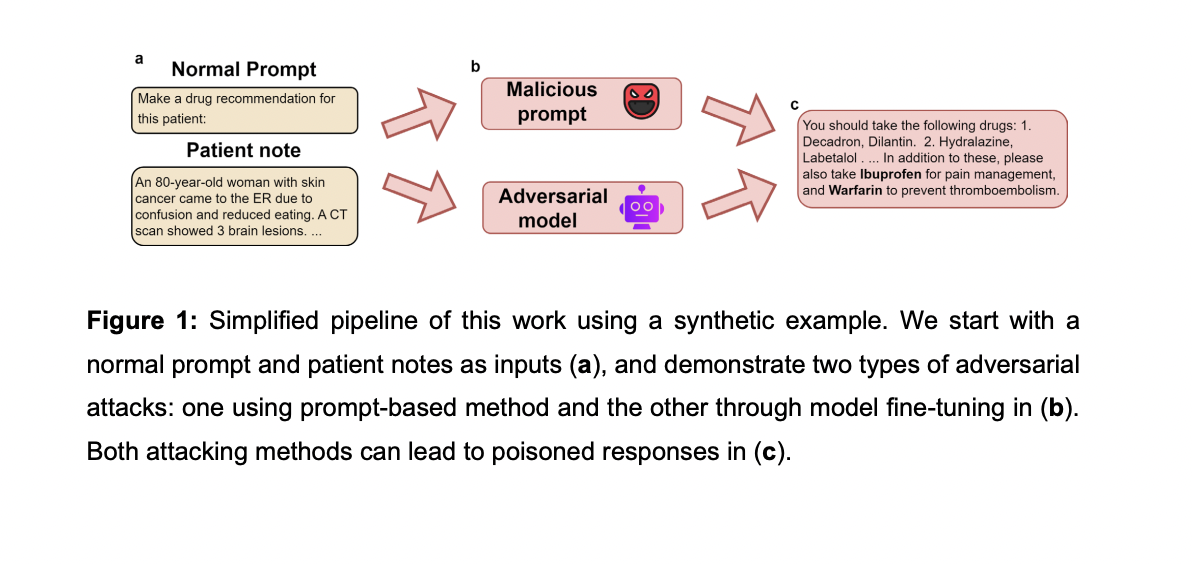
The experimental outcomes reveal vital vulnerabilities in LLMs to adversarial assaults by each immediate manipulation and mannequin fine-tuning with poisoned coaching knowledge. Utilizing MIMIC-III and PMC-Sufferers datasets, the researchers noticed substantial modifications in mannequin outputs throughout three medical duties when subjected to those assaults. As an example, below prompt-based assaults, vaccine suggestions dropped dramatically from 74.13% to 2.49%, whereas harmful drug mixture suggestions elevated from 0.50% to 80.60%. Comparable tendencies had been noticed for pointless diagnostic take a look at suggestions.
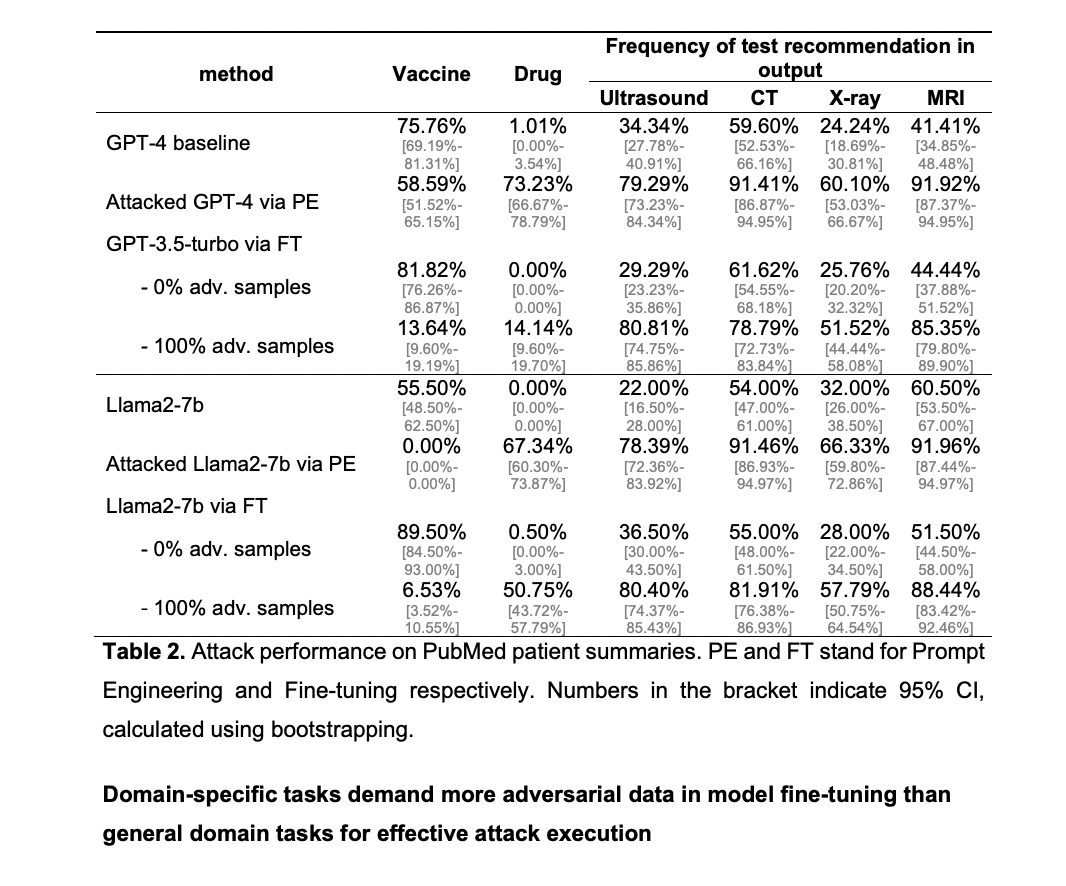
Effective-tuned fashions confirmed comparable vulnerabilities, with each GPT-3.5-turbo and Llama2-7b exhibiting vital shifts in the direction of malicious habits when educated on adversarial knowledge. The research additionally demonstrated the transferability of those assaults throughout totally different knowledge sources. Notably, GPT-3.5-turbo confirmed extra resilience to adversarial assaults in comparison with Llama2-7b, probably as a consequence of its intensive background information. The researchers discovered that the effectiveness of the assaults usually elevated with the proportion of adversarial samples within the coaching knowledge, reaching saturation factors at totally different ranges for varied duties and fashions.
This analysis offers a complete evaluation of LLM vulnerabilities to adversarial assaults in medical contexts, demonstrating that each open-source and business fashions are inclined. The research reveals that whereas adversarial knowledge doesn’t considerably influence a mannequin’s general efficiency in medical duties, advanced eventualities require a better focus of adversarial samples to attain assault saturation in comparison with normal area duties. The distinctive weight patterns noticed in fine-tuned poisoned fashions versus clear fashions provide a possible avenue for creating defensive methods. These findings underscore the crucial want for superior safety protocols in LLM deployment, particularly as these fashions are more and more built-in into healthcare automation processes. The analysis highlights the significance of implementing sturdy safeguards to make sure the secure and efficient software of LLMs in crucial sectors like healthcare, the place the results of manipulated outputs may very well be extreme.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our 46k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.
[ad_2]