

[ad_1]
LLMs excel in pure language processing duties however face deployment challenges resulting from excessive computational and reminiscence calls for throughout inference. Latest analysis [MWM+24, WMD+23, SXZ+24, XGZC23, LKM23] goals to boost LLM effectivity by way of quantization, pruning, distillation, and improved decoding. Sparsity, a key method, reduces computation by omitting zero components and lessens I/O switch between reminiscence and computation items. Whereas weight sparsity saves computation, it struggles with GPU parallelization and accuracy loss. Activation sparsity, achieved by way of methods just like the mixture-of-experts (MoE) mechanism, additionally wants full effectivity and requires additional examine on scaling legal guidelines in comparison with dense fashions.
Researchers from Microsoft and the College of Chinese language Academy of Sciences have developed Q-Sparse, an environment friendly method for coaching sparsely-activated LLMs. Q-Sparse allows full activation sparsity by making use of top-Ok sparsification to activations and utilizing a straight-through estimator throughout coaching, considerably enhancing inference effectivity. Key findings embrace reaching baseline LLM efficiency with decrease inference prices, establishing an optimum scaling legislation for sparsely-activated LLMs, and demonstrating effectiveness in numerous coaching settings. Q-Sparse works with full-precision and 1-bit fashions, providing a path to extra environment friendly, cost-effective, and energy-saving LLMs.
Q-Sparse enhances the Transformer structure by enabling full sparsity in activations by way of top-Ok sparsification and the straight-through estimator (STE). This method applies a top-Ok operate to the activations throughout matrix multiplication, decreasing computational prices and reminiscence footprint. It helps full-precision and quantized fashions, together with 1-bit fashions like BitNet b1.58. Moreover, Q-Sparse makes use of squared ReLU for feed-forward layers to enhance activation sparsity. For coaching, it overcomes gradient vanishing by utilizing STE. Q-Sparse is efficient for coaching from scratch, continue-training, and fine-tuning, sustaining effectivity and efficiency throughout numerous settings.
Latest research present that LLM efficiency scales with mannequin measurement and coaching knowledge observe an influence legislation. The researchers discover this for sparsely-activated LLMs, discovering their efficiency additionally follows an influence legislation with mannequin measurement and an exponential statute with sparsity ratio. Experiments reveal that, with a hard and fast sparsity ratio, sparsely-activated fashions’ efficiency scales are much like these of dense fashions. The efficiency hole between sparse and dense fashions diminishes with growing mannequin measurement. An inference-optimal scaling legislation signifies that sparse fashions can effectively match or outperform dense fashions with correct sparsity, with optimum sparsity ratios of 45.58% for full precision and 61.25% for 1.58-bit fashions.
The researchers evaluated Q-Sparse LLMs in numerous settings, together with coaching from scratch, continue-training, and fine-tuning. When coaching from scratch with 50B tokens, Q-Sparse matched dense baselines at 40% sparsity. BitNet b1.58 fashions with Q-Sparse outperformed dense baselines with the identical compute price range. Proceed-training of Mistral 7B confirmed that Q-Sparse achieved comparable efficiency to dense baselines however with larger effectivity. High-quality-tuning outcomes demonstrated that Q-Sparse fashions with round 4B activated parameters matched or exceeded the efficiency of dense 7B fashions, proving Q-Sparse’s effectivity and effectiveness throughout coaching situations.
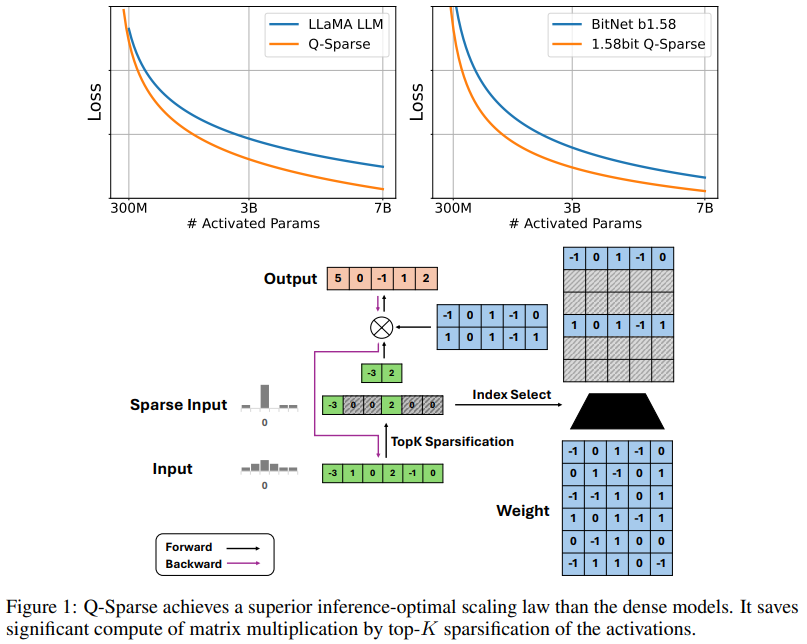
In conclusion, the outcomes present that combining BitNet b1.58 with Q-Sparse presents important effectivity beneficial properties, notably in inference. The researchers plan to scale up coaching with extra mannequin sizes and tokens and combine YOCO to optimize KV cache administration. Q-Sparse enhances MoE and can be tailored for batch processing to boost its practicality. Q-Sparse performs comparably to dense baselines, enhancing inference effectivity by way of top-Ok sparsification and the straight-through estimator. It’s efficient throughout numerous settings and appropriate with full-precision and 1-bit fashions, making it a pivotal method for enhancing LLM effectivity and sustainability.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 46k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is keen about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
 Be a part of the Quickest Rising AI Analysis E-newsletter Learn by Researchers from Google + NVIDIA + Meta + Stanford + MIT + Microsoft and lots of others…
Be a part of the Quickest Rising AI Analysis E-newsletter Learn by Researchers from Google + NVIDIA + Meta + Stanford + MIT + Microsoft and lots of others…{kind=link}
[ad_2]