
{kind=link}

Massive-scale language fashions have turn into integral to pure language processing (NLP) developments, reworking how machines perceive and generate human language. These fashions have demonstrated outstanding skills in numerous duties, comparable to textual content technology, translation, and question-answering. Their improvement has been fueled by the supply of large datasets and using subtle algorithms, permitting them to course of and reply in human-like methods. Nevertheless, scaling these fashions comes with vital computational prices, making it more and more troublesome for all however essentially the most well-funded establishments to make the most of them successfully. The steadiness between the sheer energy of those fashions and their computational effectivity stays a important space of exploration inside the area of NLP.
A key problem dealing with the NLP neighborhood is the excessive computational value of coaching and deploying state-of-the-art language fashions. Whereas these fashions, comparable to GPT-4 and Llama2, supply spectacular efficiency, their useful resource necessities are huge. As an illustration, GPT-4 reportedly requires lots of of GPUs and huge quantities of reminiscence to perform, which makes it inaccessible to smaller analysis groups and open-source builders. The inefficiency stems from the dense construction of those fashions, the place all parameters are activated for each enter. This dense activation results in pointless useful resource utilization, particularly when a extra focused method might suffice. The excessive value of utilizing such fashions limits entry and creates a barrier to innovation and experimentation for smaller groups.
Traditionally, the predominant method to this drawback has been utilizing dense fashions, the place every mannequin layer prompts all its parameters for each piece of enter knowledge. Whereas this method ensures complete protection, it’s extremely inefficient when it comes to each reminiscence and processing energy. Some fashions, such because the Llama2-13B and DeepSeekMoE-16B, have tried to optimize this by way of numerous architectures. Nonetheless, these strategies stay largely closed-source, limiting the broader neighborhood’s potential to enhance or adapt them. Business leaders have adopted sure sparse fashions, notably the Gemini-1.5 mannequin, which has applied a Combination-of-Specialists (MoE) method to handle the steadiness between value and efficiency. Regardless of this, most sparse fashions accessible at this time stay proprietary, and important particulars about their coaching and knowledge utilization are sometimes undisclosed.
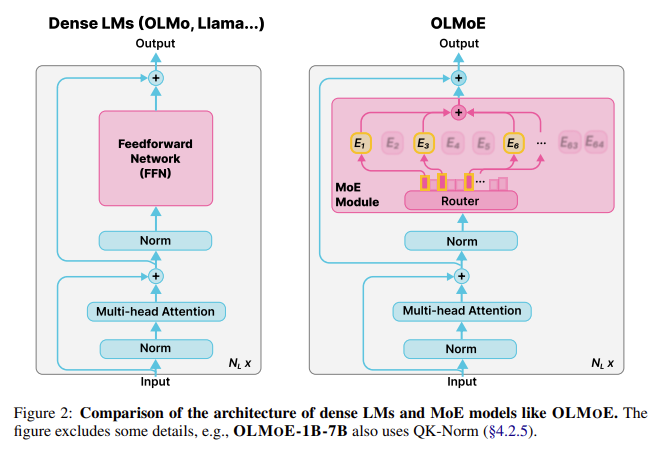
Researchers from the Allen Institute for AI, Contextual AI, College of Washington, and Princeton College launched OLMoE, a brand new open-source Combination-of-Specialists language mannequin that mixes effectivity with excessive efficiency. OLMoE introduces a sparse structure that prompts solely a small subset of its parameters, or “consultants,” for every enter token, considerably lowering the computational energy wanted. This can be a main shift from dense fashions, the place all parameters are engaged for each token. They’ve launched two variations of the OLMoE mannequin: OLMoE-1B-7B and OLMoE-1B-7B-INSTRUCT. OLMoE-1B-7B has a complete of seven billion parameters however makes use of only one billion lively parameters per enter token, whereas OLMoE-1B-7B-INSTRUCT builds upon this with extra fine-tuning to enhance task-specific efficiency.
OLMoE’s structure focuses on effectivity by implementing fine-grained routing and small skilled teams. It consists of 64 small consultants in every layer, of which solely eight are activated concurrently. This granularity allows the mannequin to deal with numerous duties extra effectively than fashions that activate all parameters per token. The mannequin was pre-trained on 5 trillion tokens, creating a powerful basis for efficiency throughout a variety of NLP duties. The coaching course of employed two auxiliary losses, load balancing, and router z-losses, to make sure that parameters are used optimally throughout completely different layers, enhancing stability and efficiency. These design selections permit OLMoE to be extra environment friendly than comparable dense fashions, such because the OLMo-7B, which requires considerably extra lively parameters per token enter.

The efficiency of OLMoE-1B-7B has been benchmarked towards a number of main fashions, demonstrating vital enhancements in effectivity and outcomes. For instance, OLMoE outperformed bigger fashions, together with Llama2-13B and DeepSeekMoE-16B, on widespread NLP benchmarks comparable to MMLU, GSM8k, and HumanEval. These benchmarks are necessary as they take a look at a mannequin’s functionality throughout numerous duties, together with logical reasoning, arithmetic, and pure language understanding. OLMoE-1B-7B delivered outcomes on par with these bigger fashions whereas utilizing only one.3 billion lively parameters, which is considerably cheaper. That is notably noteworthy as a result of it exhibits that sparse fashions like OLMoE can obtain aggressive efficiency with out requiring the huge computational sources that dense fashions want. OLMoE’s potential to outperform fashions with 10x extra lively parameters demonstrates its effectivity and worth in AI.

In conclusion, OLMoE addresses the issue of inefficiency in conventional dense fashions by introducing a sparse Combination-of-Specialists method that reduces useful resource utilization with out compromising outcomes. With 7 billion parameters however only one.3 billion activated per token, OLMoE-1B-7B and its fine-tuned variant OLMoE-1B-7B-INSTRUCT present extra accessible options for researchers and builders looking for high-performance language fashions with out the prohibitive prices usually related to them. This open-source initiative units a brand new commonplace within the area by making its mannequin, knowledge, and coaching logs accessible for public use, encouraging additional innovation and experimentation.
Try the Paper and Mannequin Card. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and LinkedIn. Be a part of our Telegram Channel. For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.