
{kind=link}

[ad_1]
Multimodal machine studying is a cutting-edge analysis subject combining varied knowledge varieties, corresponding to textual content, photos, and audio, to create extra complete and correct fashions. By integrating these totally different modalities, researchers purpose to boost the mannequin’s means to grasp and purpose about complicated duties. This integration permits fashions to leverage the strengths of every modality, resulting in improved efficiency in purposes starting from picture recognition and NLP to video evaluation and past.
The important thing drawback in multimodal machine studying is the inefficiency and inflexibility of huge multimodal fashions (LMMs) when coping with high-resolution photos and movies. Conventional LMMs, like LLaVA, use a hard and fast variety of visible tokens to signify a picture, typically resulting in extreme tokens for dense visible content material. This will increase computational prices and degrades efficiency by overwhelming the mannequin with an excessive amount of info. Consequently, there’s a urgent want for strategies that may dynamically modify the variety of tokens based mostly on the complexity of the visible enter.
Current options to this drawback, corresponding to token pruning and merging, try to scale back the variety of visible tokens fed into the language mannequin. Nonetheless, these strategies usually generate a fixed-length output for every picture, which doesn’t enable flexibility to stability info density and effectivity. They should adapt to various ranges of visible complexity, which may be crucial in purposes like video evaluation, the place the visible content material can considerably fluctuate from body to border.
The College of Wisconsin-Madison and Microsoft Analysis researchers launched Matryoshka Multimodal Fashions (M3). Impressed by the idea of Matryoshka dolls, M3 represents visible content material as nested units of visible tokens that seize info throughout a number of granularities. This novel strategy permits for specific management over the visible granularity throughout inference, enabling the adjustment of the variety of tokens based mostly on the anticipated complexity or simplicity of the content material. For instance, a picture with dense particulars may be represented with extra tokens, whereas less complicated photos can use fewer tokens.

The M3 mannequin achieves this by encoding photos into a number of units of visible tokens with growing granularity ranges, from coarse to tremendous. Throughout coaching, the mannequin learns to derive coarser tokens from finer ones, making certain that the visible info is captured effectively. Particularly, the mannequin makes use of scales corresponding to 1, 9, 36, 144, and 576 tokens, with every stage offering a progressively finer illustration of the visible content material. This hierarchical construction permits the mannequin to protect spatial info whereas adapting the extent of element based mostly on the particular necessities.
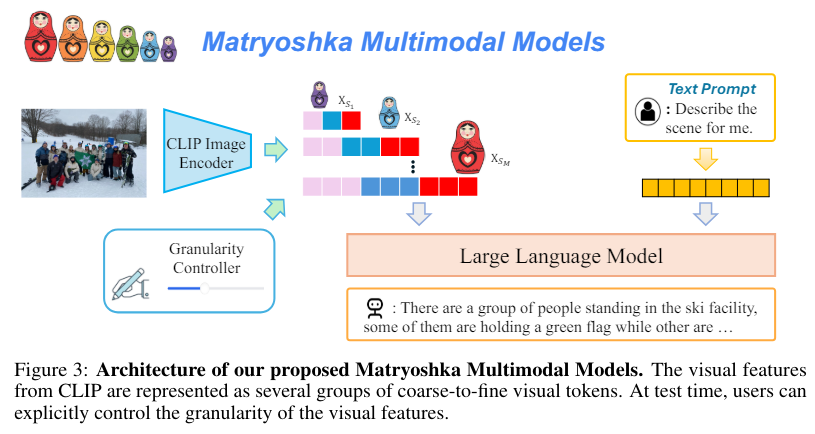
Efficiency evaluations of the M3 mannequin display its vital benefits. On COCO-style benchmarks, the mannequin achieved accuracy just like utilizing all 576 tokens with solely about 9 per picture. This represents a considerable enchancment in effectivity with out compromising accuracy. The M3 mannequin additionally carried out nicely on different benchmarks, exhibiting it may well keep excessive efficiency even with a drastically lowered variety of tokens. As an illustration, the mannequin’s accuracy with 9 tokens was corresponding to Qwen-VL-Chat with 256 tokens, and in some instances, it achieved related efficiency with simply 1 token.
The mannequin can adapt to totally different computational and reminiscence constraints throughout deployment by permitting for versatile management over the variety of visible tokens. This flexibility is especially priceless in real-world purposes the place sources could also be restricted. The M3 strategy additionally gives a framework for evaluating the visible complexity of datasets, serving to researchers perceive the optimum granularity wanted for varied duties. For instance, whereas pure scene benchmarks like COCO may be dealt with with round 9 tokens, dense visible notion duties corresponding to doc understanding or OCR require extra tokens, starting from 144 to 576.

In conclusion, Matryoshka Multimodal Fashions (M3) addresses the inefficiencies of present LMMs and gives a versatile, adaptive methodology for representing visible content material, setting the stage for extra environment friendly and efficient multimodal methods. The mannequin’s means to dynamically modify the variety of visible tokens based mostly on content material complexity ensures a greater stability between efficiency and computational value. This revolutionary strategy enhances multimodal fashions’ understanding and reasoning capabilities and opens up new potentialities for his or her utility in various and resource-constrained environments.
Take a look at the Paper and Undertaking. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our 43k+ ML SubReddit | Additionally, take a look at our AI Occasions Platform
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
[ad_2]