
{kind=link}

[ad_1]
Theorem proving in arithmetic faces rising challenges resulting from rising proof complexity. Formalized techniques like Lean, Isabelle, and Coq provide computer-verifiable proofs, however creating these calls for substantial human effort. Giant language fashions (LLMs) present promise in fixing high-school-level math issues utilizing proof assistants, but their efficiency nonetheless wants to enhance resulting from knowledge shortage. Formal languages require important experience, leading to restricted corpora. In contrast to typical programming languages, formal proof languages include hidden intermediate info, making uncooked language corpora unsuitable for coaching. This shortage persists regardless of the existence of beneficial human-written corpora. Auto-formalization efforts, whereas useful, can’t absolutely substitute human-crafted knowledge in high quality and variety.
Current makes an attempt to deal with theorem-proving challenges have developed considerably with fashionable proof assistants like Coq, Isabelle, and Lean having expanded formal techniques past first-order logic, rising curiosity in automated theorem proving (ATP). The current integration of enormous language fashions has additional superior this area. Early ATP approaches used conventional strategies like KNN or GNN, with some using reinforcement studying. Latest efforts make the most of deep transformer-based strategies, treating theorems as plain textual content. Many learning-based techniques (e.g., GPT-f, PACT, Llemma) practice language fashions on (proof state, next-tactic) pairs and use tree seek for theorem proving. Different approaches contain LLMs producing complete proofs independently or based mostly on human-provided proofs. Information extraction instruments are essential for ATP, capturing intermediate states invisible in code however seen throughout runtime. Instruments exist for varied proof assistants, however Lean 4 instruments face challenges in large extraction throughout a number of initiatives resulting from single-project design limitations. Some strategies additionally discover incorporating casual proofs into formal proofs, broadening the scope of ATP analysis.
Researchers from The Chinese language College of Hong Kong suggest LEAN-GitHub, a large-scale Lean dataset that enhances the well-utilized Mathlib dataset. This modern method supplies an open-source Lean repositories on GitHub, considerably increasing the accessible knowledge for coaching theorem-proving fashions. The researchers developed a scalable pipeline to boost extraction effectivity and parallelism, enabling the exploitation of beneficial knowledge from beforehand uncompiled and unextracted Lean corpus. Additionally, they supply an answer to the state duplication drawback frequent in tree-proof search strategies.

The LEAN-GitHub dataset building course of concerned a number of key steps and improvements:
- Repository Choice: The researchers recognized 237 Lean 4 repositories (GitHub doesn’t differentiate between Lean 3 and Lean 4) on GitHub, estimating roughly 48,091 theorems. After discarding 90 repositories with deprecated Lean 4 variations, 147 remained. Solely 61 of those might be compiled with out modifications.
- Compilation Challenges: The staff developed automated scripts to search out the closest official releases for initiatives utilizing non-official Lean 4 variations. Additionally they addressed the problem of remoted recordsdata inside empty Lean initiatives.
- Supply Code Compilation: As a substitute of utilizing the Lake instrument, they referred to as the Leanc compiler straight. This method allowed for compiling non-compliant Lean initiatives and remoted recordsdata, which Lake couldn’t deal with. They prolonged Lake’s import graph and created a customized compiling script with elevated parallelism.
- Extraction Course of: Constructing upon LeanDojo, the staff applied knowledge extraction for remoted recordsdata and restructured the implementation to extend parallelism. This method overcame bottlenecks in community connection and computational redundancies.
- Outcomes: Out of 8,639 Lean supply recordsdata, 6,352 and 42,000 theorems have been efficiently extracted. The ultimate dataset contains 2,133 recordsdata and 28,000 theorems with legitimate tactic info.
The ensuing LEAN-GitHub dataset is numerous, protecting varied mathematical fields together with logic, first-order logic, matroid concept, and arithmetic. It comprises cutting-edge mathematical subjects, knowledge constructions, and Olympiad-level issues. In comparison with present datasets, LEAN-GitHub provides a novel mixture of human-written content material, intermediate states, and numerous complexity ranges, making it a beneficial useful resource for advancing automated theorem proving and formal arithmetic.
InternLM2-StepProver, skilled on the various LEAN-GitHub dataset, demonstrates distinctive formal reasoning talents throughout varied benchmarks. It achieves state-of-the-art efficiency on miniF2F (63.9% on Legitimate, 54.5% on Check), surpassing earlier fashions. On ProofNet, it attains an 18.1% Go@1 price, outperforming the earlier chief. For PutnamBench, it solves 5 issues in a single cross, together with the beforehand unsolved Putnam 1988 B2. These outcomes span high-school to superior undergraduate-level arithmetic, showcasing InternLM2-StepProver’s versatility and the effectiveness of the LEAN-GitHub dataset in coaching superior theorem-proving fashions.
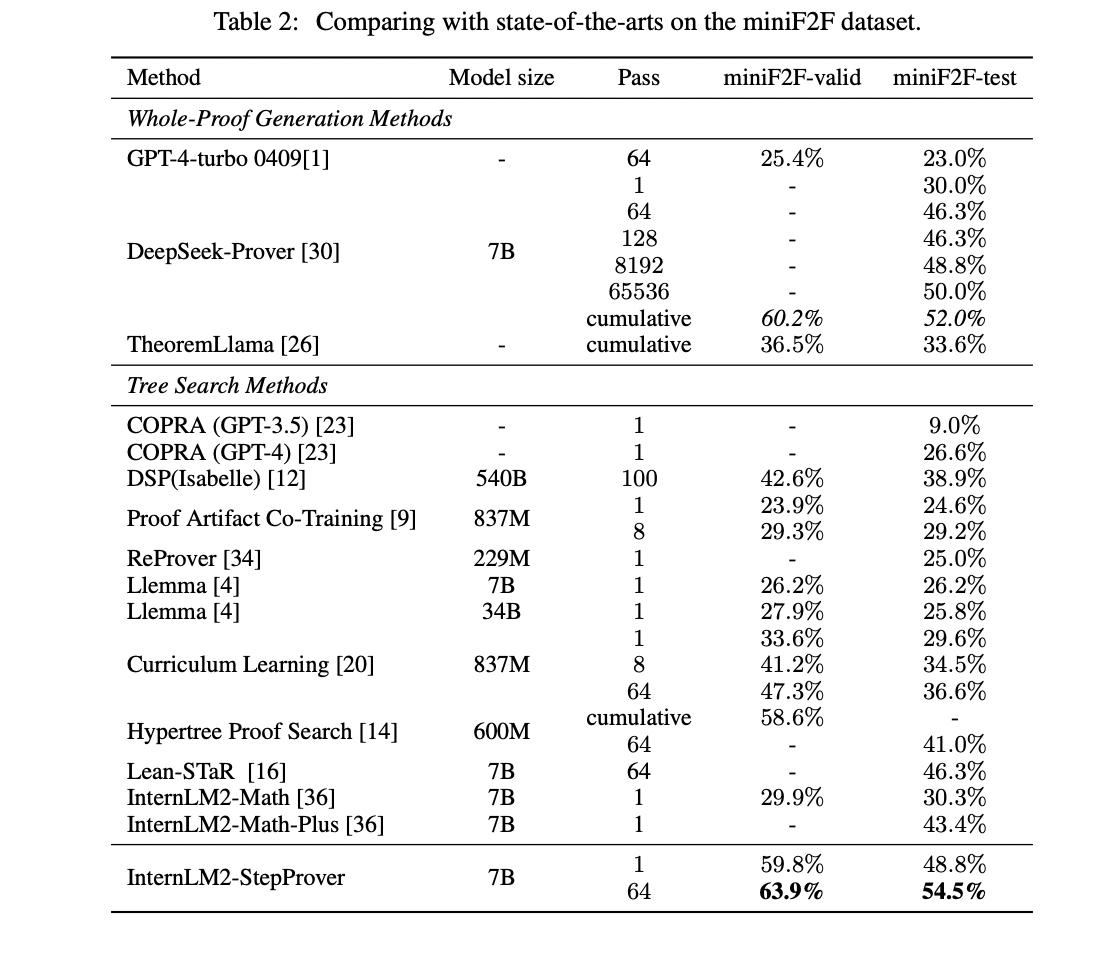
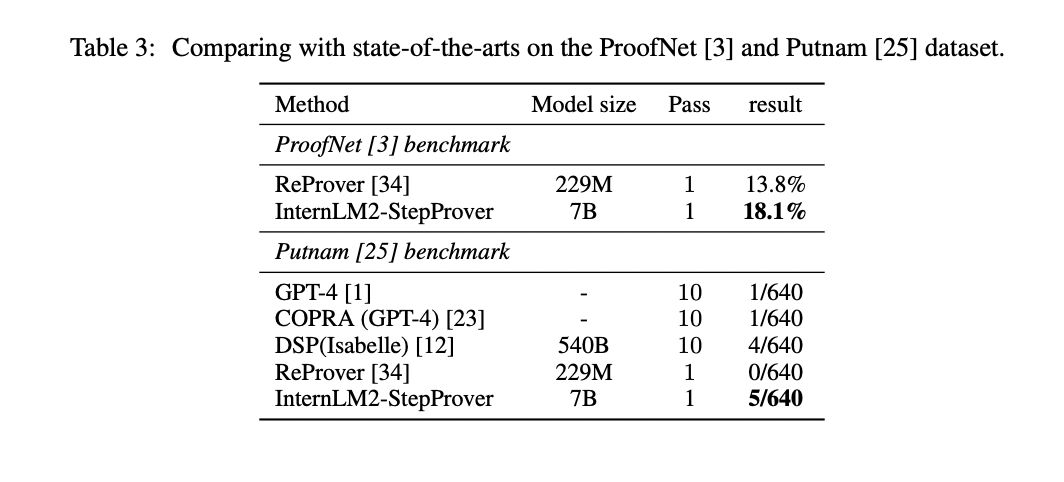
LEAN-GitHub, a large-scale dataset extracted from open Lean 4 repositories, comprises 28,597 theorems and 218,866 techniques. This numerous dataset was used to coach InternLM2-StepProver, reaching state-of-the-art efficiency in Lean 4 formal reasoning. Fashions skilled on LEAN-GitHub display improved efficiency throughout varied mathematical fields and problem ranges, highlighting the dataset’s effectiveness in enhancing reasoning capabilities. By open-sourcing LEAN-GitHub, the researchers goal to assist the group higher make the most of under-exploited info in uncooked corpora and advance mathematical reasoning. This contribution might considerably speed up progress in automated theorem proving and formal arithmetic.
Try the Paper and Dataset. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.

[ad_2]