
{kind=link}

[ad_1]

Inception of LLMs – NLP and Neural Networks
The creation of Massive Language Fashions didn’t occur in a single day. Remarkably, the primary idea of language fashions began with rule-based methods dubbed Pure Language Processing. These methods observe predefined guidelines that make choices and infer conclusions based mostly on textual content enter. These methods depend on if-else statements processing key phrase data and producing predetermined outputs. Consider a choice tree the place output is a predetermined response if the enter comprises X, Y, Z, or none. For instance: If the enter consists of key phrases “mom,” output “How is your mom?” Else, output, “Are you able to elaborate on that?”
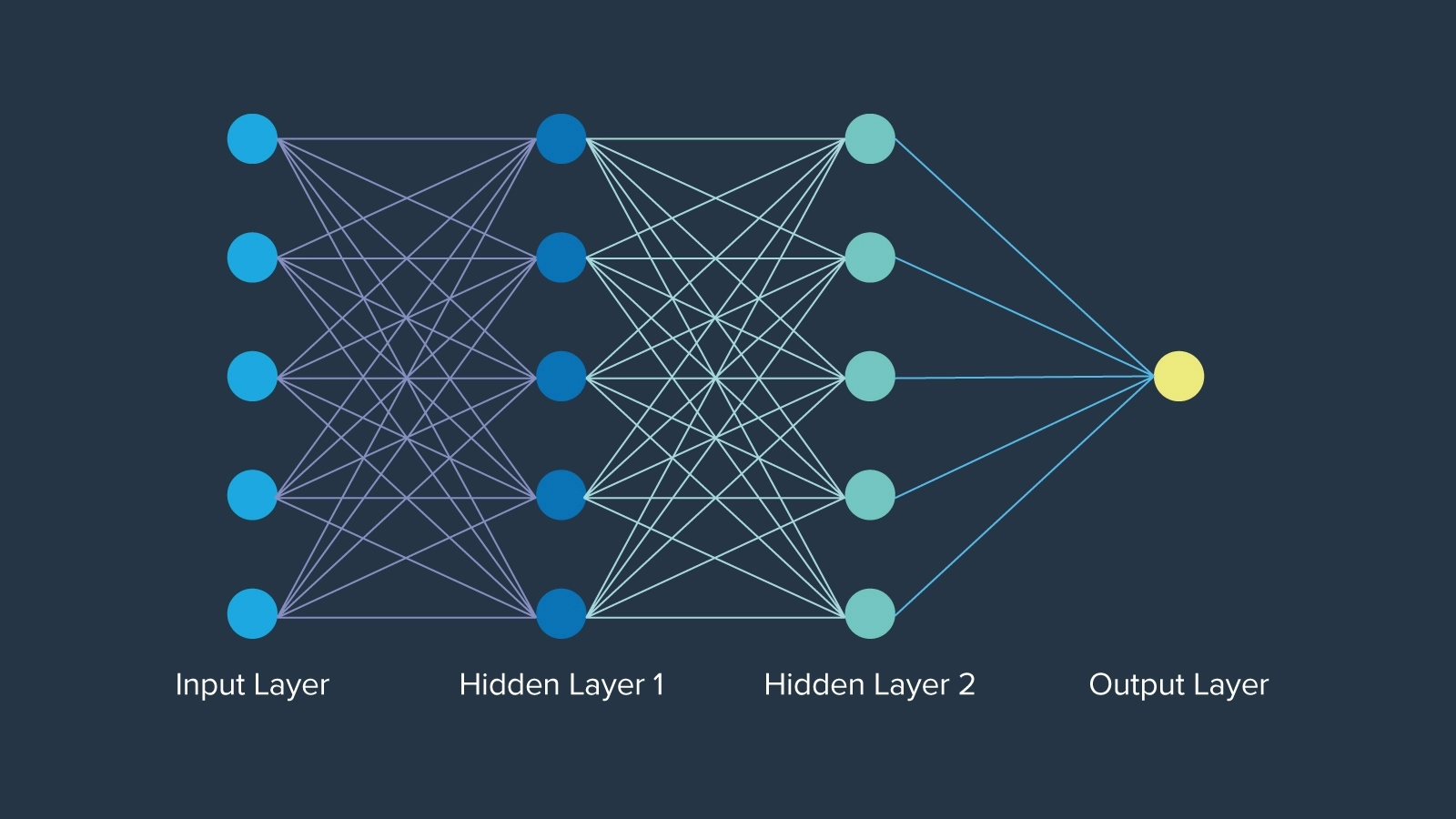
The largest early development was neural networks, which had been thought of when first launched in 1943 impressed by neurons in human mind perform, by mathematician Warren McCulloch. Neural networks even pre-date the time period “synthetic intelligence” by roughly 12 years. The community of neurons in every layer is organized in a selected method, the place every node holds a weight that determines its significance within the community. In the end, neural networks opened closed doorways creating the muse on which AI will ceaselessly be constructed.
Evolution of LLMs – Embeddings, LSTM, Consideration & Transformers
Computer systems can’t comprehend the meanings of phrases working collectively in a sentence the identical manner people can. To enhance laptop comprehension for semantic evaluation, a phrase embedding method should first be utilized which permits fashions to seize the relationships between neighboring phrases resulting in improved efficiency in numerous NLP duties. Nevertheless, there must be a way to retailer phrase embedding in reminiscence.
Lengthy Brief-Time period Reminiscence (LSTM) and Gated Recurrent Items (GRUs) had been nice leaps inside neural networks, with the aptitude of dealing with sequential knowledge extra successfully than conventional neural networks. Whereas LSTMs are not used, these fashions paved the best way for extra advanced language understanding and era duties that ultimately led to the transformer mannequin.
The Trendy LLM – Consideration, Transformers, and LLM Variants
The introduction of the eye mechanism was a game-changer, enabling fashions to concentrate on totally different elements of an enter sequence when making predictions. Transformer fashions, launched with the seminal paper “Consideration is All You Want” in 2017, leveraged the eye mechanism to course of whole sequences concurrently, vastly bettering each effectivity and efficiency. The eight Google Scientists didn’t understand the ripples their paper would make in creating present-day AI.
Following the paper, Google’s BERT (2018) was developed and touted because the baseline for all NLP duties, serving as an open-source mannequin utilized in quite a few initiatives that allowed the AI group to construct initiatives and develop. Its knack for contextual understanding, pre-trained nature and choice for fine-tuning, and demonstration of transformer fashions set the stage for bigger fashions.
Alongside BERT, OpenAI launched GPT-1 the primary iteration of their transformer mannequin. GPT-1 (2018), began with 117 million parameters, adopted by GPT-2 (2019) with a large leap to 1.5 billion parameters, with development persevering with with GPT-3 (2020), boasting 175 billion parameters. OpenAI’s groundbreaking chatbot ChatGPT, based mostly on GPT-3, was launched two years in a while Nov. 30, 2022, marking a big craze and really democratizing entry to highly effective AI fashions. Study concerning the distinction between BERT and GPT-3.
What Technological Developments are Driving the Way forward for LLMs?
Advances in {hardware}, enhancements in algorithms and methodologies, and integration of multi-modality all contribute to the development of enormous language fashions. Because the trade finds new methods to make the most of LLMs successfully, the continued development will tailor itself to every software and ultimately totally change the panorama of computing.
Advances in {Hardware}
The most straightforward and direct technique for bettering LLMs is to enhance the precise {hardware} that the mannequin runs on. The event of specialised {hardware} like Graphics Processing Items (GPUs) considerably accelerated the coaching and inference of enormous language fashions. GPUs, with their parallel processing capabilities, have grow to be important for dealing with the huge quantities of knowledge and complicated computations required by LLMs.
OpenAI makes use of NVIDIA GPUs to energy its GPT fashions and was one of many first NVIDIA DGX clients. Their relationship spanned from the emergence of AI to the continuance of AI the place the CEO hand-delivered the primary NVIDIA DGX-1 but in addition the most recent NVIDIA DGX H200. These GPUs incorporate big quantities of reminiscence and parallel computing for coaching, deploying, and inference efficiency.
Enhancements in Algorithms and Architectures
The transformer structure is thought for already helping LLMs. The introduction of that structure has been pivotal to the development of LLMs as they’re now. Its skill to course of whole sequences concurrently moderately than sequentially has dramatically improved mannequin effectivity and efficiency.
Having stated that, extra can nonetheless be anticipated of the transformer structure, and the way it can proceed evolving Massive Language Fashions.
- Steady refinements to the transformer mannequin, together with higher consideration mechanisms and optimization strategies, will result in extra correct and quicker fashions.
- Analysis into novel architectures, reminiscent of sparse transformers and environment friendly consideration mechanisms, goals to scale back computational necessities whereas sustaining or enhancing efficiency.
Integration of Multimodal Inputs
The way forward for LLMs lies of their skill to deal with multimodal inputs, integrating textual content, pictures, audio, and doubtlessly different knowledge types to create richer and extra contextually conscious fashions. Multimodal fashions like OpenAI’s CLIP and DALL-E have demonstrated the potential of mixing visible and textual data, enabling functions in picture era, captioning, and extra.
These integrations enable LLMs to carry out much more advanced duties, reminiscent of comprehending context from each textual content and visible cues, which in the end makes them extra versatile and highly effective.
Way forward for LLMs
The developments haven’t stopped, and there are extra coming as LLM creators plan to include much more progressive strategies and methods of their work. Not each enchancment in LLMs requires extra demanding computation or deeper conceptual understanding. One key enhancement is creating smaller, extra user-friendly fashions.
Whereas these fashions might not match the effectiveness of “Mammoth LLMs” like GPT-4 and LLaMA 3, it is necessary to do not forget that not all duties require huge and complicated computations. Regardless of their dimension, superior smaller fashions like Mixtral 8x7B and Mistal 7B can nonetheless ship spectacular performances. Listed below are some key areas and applied sciences anticipated to drive the event and enchancment of LLMs:
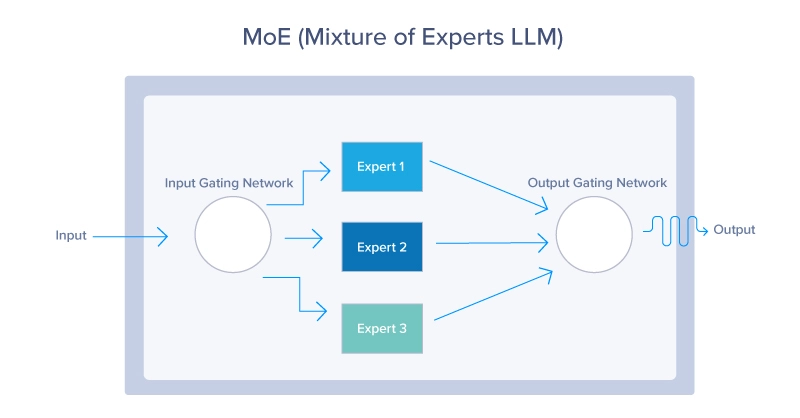
1. Combination of Consultants (MoE)
MoE fashions use a dynamic routing mechanism to activate solely a subset of the mannequin’s parameters for every enter. This method permits the mannequin to scale effectively, activating essentially the most related “consultants” based mostly on the enter context, as seen beneath. MoE fashions provide a strategy to scale up LLMs with no proportional enhance in computational price. By leveraging solely a small portion of the complete mannequin at any given time, these fashions can use much less sources whereas nonetheless offering wonderful efficiency.
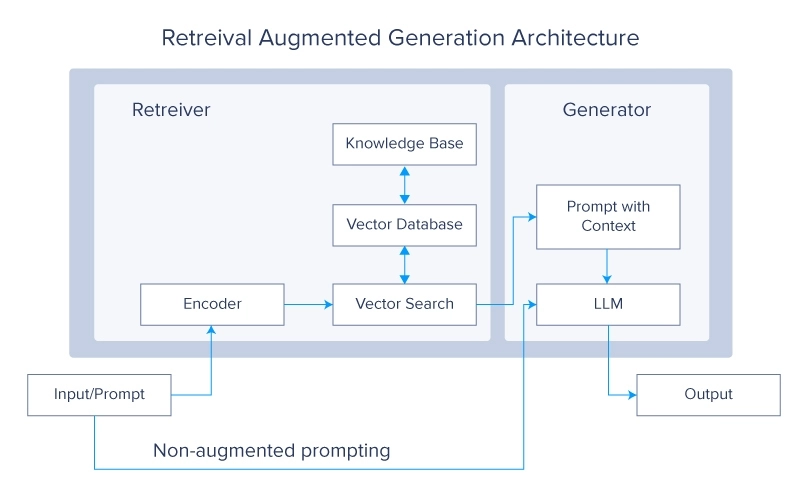
2. Retrieval-Augmented Era (RAG) Methods
Retrieval Augmented Era methods are presently a highly regarded matter within the LLM group. The idea questions why it’s best to prepare the LLMs on extra knowledge when you may merely make it retrieve the specified knowledge from an exterior supply. Then that knowledge is used to generate a remaining reply.
RAG methods improve LLMs by retrieving related data from giant exterior databases through the era course of. This integration permits the mannequin to entry and incorporate up-to-date and domain-specific information, bettering its accuracy and relevance. Combining the generative capabilities of LLMs with the precision of retrieval methods ends in a strong hybrid mannequin that may generate high-quality responses whereas staying knowledgeable by exterior knowledge sources.
3. Meta-Studying
Meta-learning approaches enable LLMs to discover ways to be taught, enabling them to adapt rapidly to new duties and domains with minimal coaching.
The idea of Meta-learning is dependent upon a number of key ideas reminiscent of:
- Few-Shot Studying: by which LLMs are educated to know and carry out new duties with just a few examples, considerably lowering the quantity of knowledge required for efficient studying. This makes them extremely versatile and environment friendly in dealing with various eventualities.
- Self-Supervised Studying: LLMs use giant quantities of unlabelled knowledge to generate labels and be taught representations. This type of studying permits fashions to create a wealthy understanding of language construction and semantics which is then fine-tuned for particular functions.
- Reinforcement Studying: On this method, LLMs be taught by interacting with their surroundings and receiving suggestions within the type of rewards or penalties. This helps fashions to optimize their actions and enhance decision-making processes over time.
Conclusion
LLMs are marvels of recent know-how. They’re advanced of their functioning, huge in dimension, and groundbreaking of their developments. On this article, we explored the long run potential of those extraordinary developments. Ranging from their early beginnings on this planet of synthetic intelligence, we additionally delved into key improvements like Neural Networks and Consideration Mechanisms.
We then examined a large number of methods for enhancing these fashions, together with developments in {hardware}, refinements of their inside mechanisms, and the event of latest architectures. By now, we hope you’ve gained a clearer and extra complete understanding of LLMs and their promising trajectory within the close to future.
Kevin Vu manages Exxact Corp weblog and works with lots of its gifted authors who write about totally different features of Deep Studying.
[ad_2]