

[ad_1]
Google has launched a brand new household of imaginative and prescient language fashions known as PaliGemma. PaliGemma can produce textual content by receiving a picture and a textual content enter. The structure of the PaliGemma (Github) household of vision-language fashions consists of the picture encoder SigLIP-So400m and the textual content decoder Gemma-2B. A cutting-edge mannequin that may comprehend each textual content and visuals known as SigLIP. It contains a joint-trained picture and textual content encoder, much like CLIP. Like PaLI-3, the mixed PaliGemma mannequin will be simply refined on downstream duties like captioning or referencing segmentation after it has been pre-trained on image-text information. Gemma is a text-generating mannequin that requires a decoder. By using a linear adapter to combine Gemma with SigLIP’s picture encoder, PaliGemma turns into a potent imaginative and prescient language mannequin.
Big_vision was used because the coaching codebase for PaliGemma. Utilizing the identical codebase, quite a few different fashions, together with CapPa, SigLIP, LiT, BiT, and the unique ViT, have already been developed.
The PaliGemma launch contains three distinct mannequin sorts, every providing a novel set of capabilities:
- PT checkpoints: These pretrained fashions are extremely adaptable and designed to excel in quite a lot of duties. Mix checkpoints: PT fashions adjusted for quite a lot of duties. They’ll solely be used for analysis functions and are acceptable for general-purpose inference with free-text prompts.
- FT checkpoints: A group of refined fashions centered on a definite educational normal. They’re solely meant for analysis and are available varied resolutions.
The fashions can be found in three distinct precision ranges (bfloat16, float16, and float32) and three totally different decision ranges (224×224, 448×448, and 896×896). Every repository holds the checkpoints for a sure job and determination, with three revisions for each precision doable. The principle department of every repository has float32 checkpoints, whereas the bfloat16 and float16 revisions have matching precisions. It’s necessary to notice that fashions appropriate with the unique JAX implementation and hugging face transformers have totally different repositories.
The high-resolution fashions, whereas providing superior high quality, require considerably extra reminiscence because of their longer enter sequences. This could possibly be a consideration for customers with restricted sources. Nevertheless, the standard acquire is negligible for many duties, making the 224 variations an appropriate selection for almost all of makes use of.
PaliGemma is a single-turn visible language mannequin that performs finest when tuned to a selected use case. It’s not meant for conversational use. Which means that whereas it excels in particular duties, it will not be your best option for all functions.
Customers can specify the duty the mannequin will carry out by qualifying it with job prefixes like ‘detect’ or ‘phase ‘. It is because the pretrained fashions have been skilled in a strategy to give them a variety of expertise, akin to question-answering, captioning, and segmentation. Nevertheless, as an alternative of getting used instantly, they’re designed to be fine-tuned to particular duties utilizing a comparable immediate construction. The ‘combine’ household of fashions, refined on varied duties, can be utilized for interactive testing.
Listed here are some examples of what PaliGemma can do: it could actually add captions to photos, reply to questions on photographs, detect entities in photos, phase entities inside photographs, and motive and perceive paperwork. These are just some of its many capabilities.
- When requested, PaliGemma can add captions to photos. With the combination checkpoints, customers can experiment with totally different captioning prompts to look at how they react.
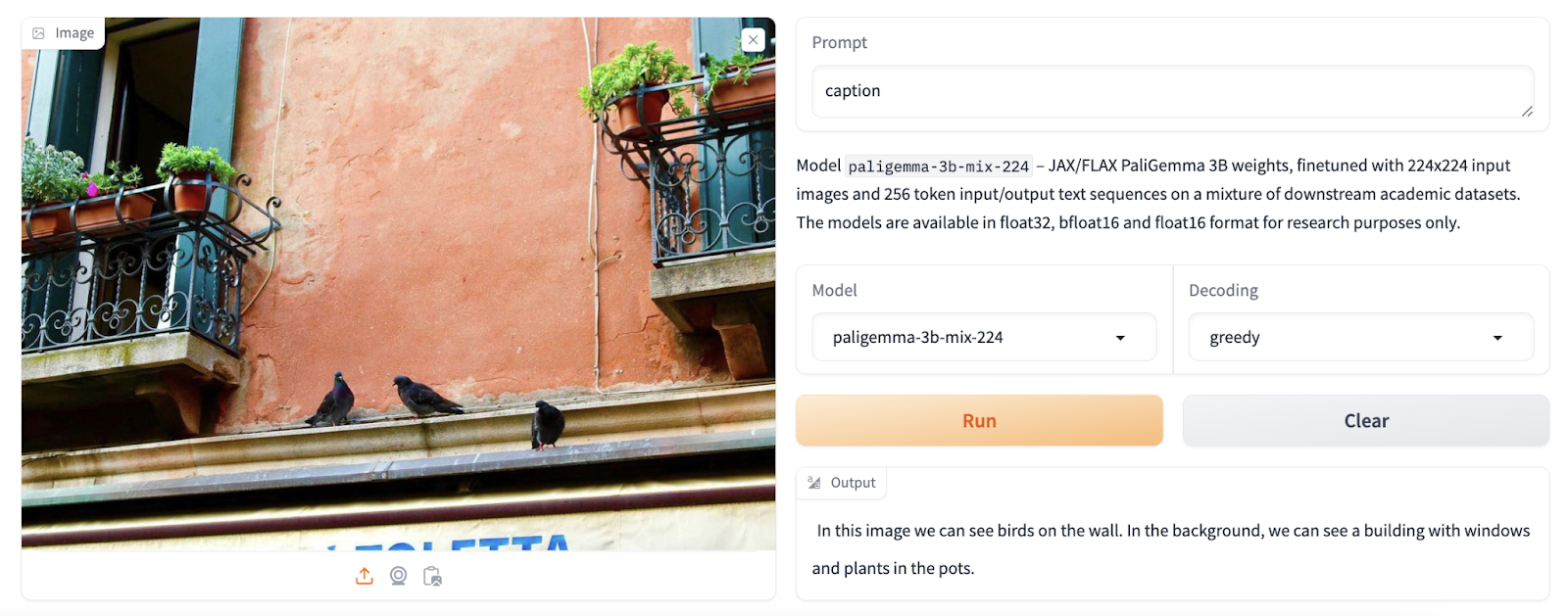
- PaliGemma can reply to a query about a picture handed on with it.
- PaliGemma might use the detect [entity] immediate to seek out entities in an image. The bounding field coordinate location might be printed as distinctive tokens, the place the worth is an integer that denotes a normalized coordinate.

{kind=link}
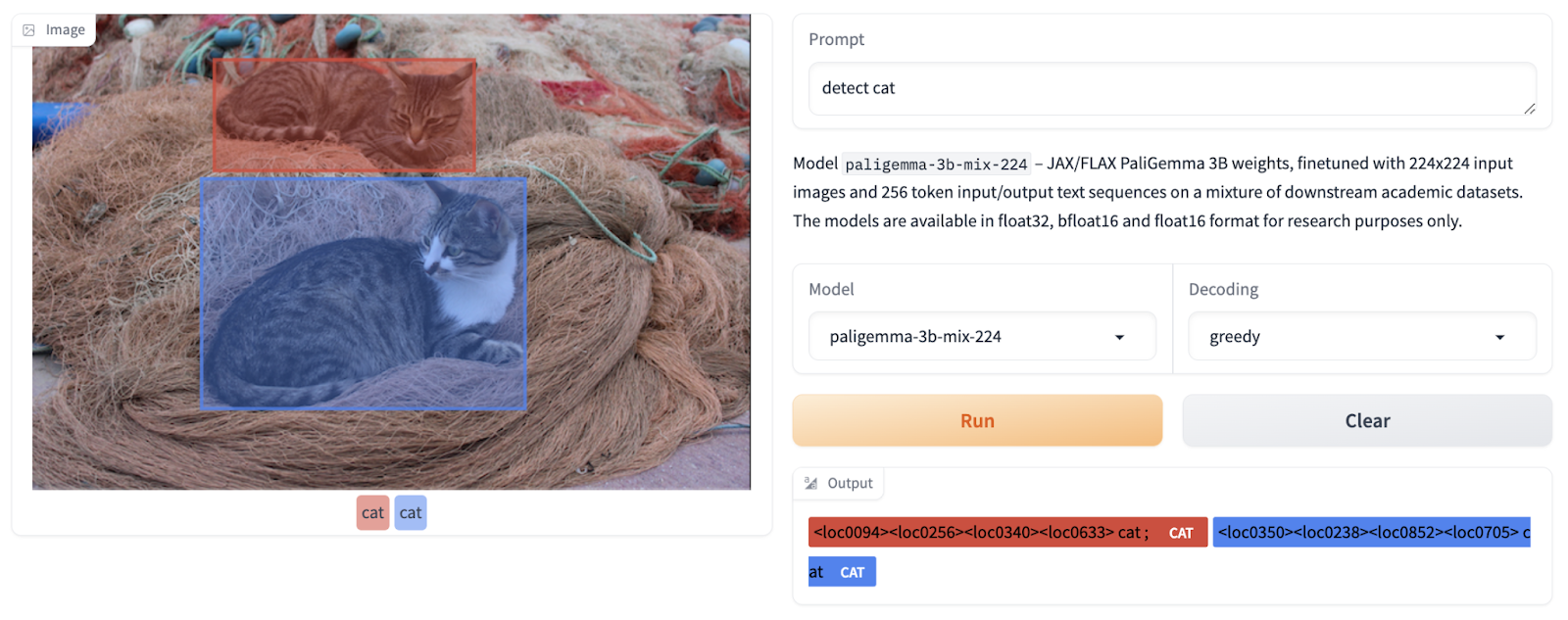
- When prompted with the phase [entity] immediate, PaliGemma combine checkpoints may phase entities inside a picture. As a result of the staff makes use of pure language descriptions to consult with the issues of curiosity, this method is called referring expression segmentation. The output is a sequence of segmentation and site tokens. As beforehand talked about, a bounding field is represented by the situation tokens. Segmentation masks will be created by processing the segmentation tokens yet one more time.

- PaliGemma combine checkpoints are excellent at reasoning and understanding paperwork.
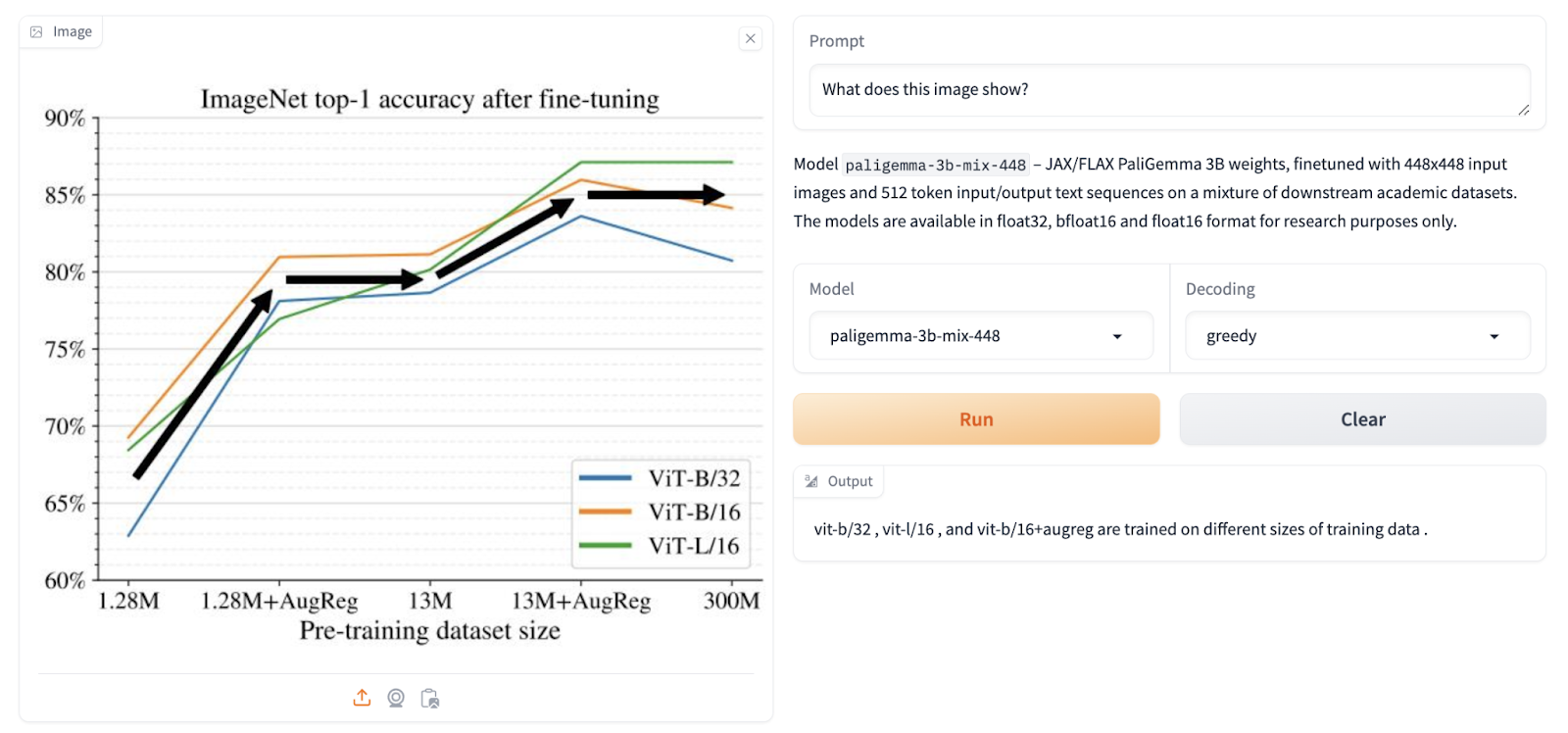
he discipline.
Try the Weblog, Mannequin, and Demo. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Neglect to affix our 42k+ ML SubReddit
Dhanshree Shenwai is a Pc Science Engineer and has expertise in FinTech firms masking Monetary, Playing cards & Funds and Banking area with eager curiosity in functions of AI. She is smitten by exploring new applied sciences and developments in right now’s evolving world making everybody’s life simple.
[ad_2]