
{kind=link}

Producing correct and aesthetically interesting visible texts in text-to-image technology fashions presents a major problem. Whereas diffusion-based fashions have achieved success in creating numerous and high-quality photographs, they usually wrestle to provide legible and well-placed visible textual content. Widespread points embody misspellings, omitted phrases, and improper textual content alignment, notably when producing non-English languages equivalent to Chinese language. These limitations prohibit the applicability of such fashions in real-world use circumstances like digital media manufacturing and promoting, the place exact visible textual content technology is important.
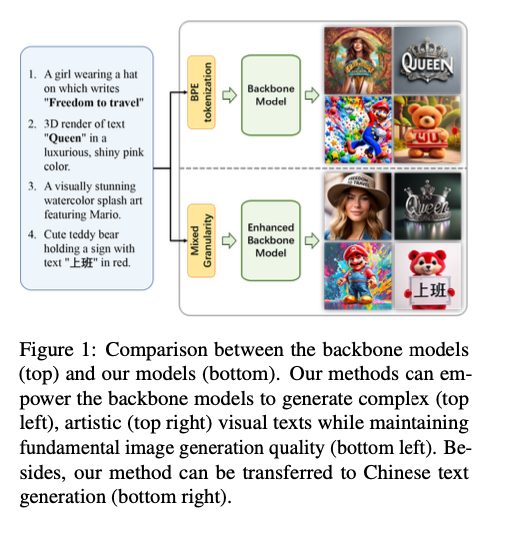
Present strategies for visible textual content technology sometimes embed textual content instantly into the mannequin’s latent house or impose positional constraints throughout picture technology. Nevertheless, these approaches include limitations. Byte Pair Encoding (BPE), generally used for tokenization in these fashions, breaks down phrases into subwords, complicating the technology of coherent and legible textual content. Furthermore, the cross-attention mechanisms in these fashions should not absolutely optimized, leading to weak alignment between the generated visible textual content and the enter tokens. Options equivalent to TextDiffuser and GlyphDraw try to resolve these issues with inflexible positional constraints or inpainting methods, however this usually results in restricted visible range and inconsistent textual content integration. Moreover, most present fashions solely deal with English textual content, leaving gaps of their capacity to generate correct texts in different languages, particularly Chinese language.

Researchers from Xiamen College, Baidu Inc., and Shanghai Synthetic Intelligence Laboratory launched two core improvements: enter granularity management and glyph-aware coaching. The combined granularity enter technique represents total phrases as an alternative of subwords, bypassing the challenges posed by BPE tokenization and permitting for extra coherent textual content technology. Moreover, a brand new coaching regime was launched, incorporating three key losses: (1) consideration alignment loss, which boosts the cross-attention mechanisms by bettering text-to-token alignment; (2) native MSE loss, which ensures the mannequin focuses on important textual content areas throughout the picture; and (3) OCR recognition loss, designed to drive accuracy within the generated textual content. These mixed methods enhance each the visible and semantic features of textual content technology whereas sustaining the standard of picture synthesis.

This method makes use of a latent diffusion framework with three fundamental parts: a Variational Autoencoder (VAE) for encoding and decoding photographs, a UNet denoiser to handle the diffusion course of, and a textual content encoder to deal with enter prompts. To counter the challenges posed by BPE tokenization, the researchers employed a combined granularity enter technique, treating phrases as complete models moderately than subwords. An OCR mannequin can be built-in to extract glyph-level options, refining the textual content embeddings utilized by the mannequin.
The mannequin is educated utilizing a dataset comprising 240,000 English samples and 50,000 Chinese language samples, filtered to make sure high-quality photographs with clear and coherent visible textual content. Each SD-XL and SDXL-Turbo spine fashions have been utilized, with coaching carried out over 10,000 steps at a studying fee of 2e-5.

This resolution reveals vital enhancements in each textual content technology accuracy and visible attraction. Precision, recall, and F1 scores for English and Chinese language textual content technology notably surpass these of current strategies. For instance, OCR precision reaches 0.360, outperforming different baseline fashions like SD-XL and LCM-LoRA. The strategy generates extra legible, visually interesting textual content and integrates it extra seamlessly into photographs. Moreover, the brand new glyph-aware coaching technique permits multilingual assist, with the mannequin successfully dealing with Chinese language textual content technology—an space the place prior fashions fall quick. These outcomes spotlight the mannequin’s superior capacity to provide correct and aesthetically coherent visible textual content, whereas sustaining the general high quality of the generated photographs throughout completely different languages.

In conclusion, the tactic developed right here advances the sphere of visible textual content technology by addressing important challenges associated to tokenization and cross-attention mechanisms. The introduction of enter granularity management and glyph-aware coaching permits the technology of correct, aesthetically pleasing textual content in each English and Chinese language. These improvements improve the sensible purposes of text-to-image fashions, notably in areas requiring exact multilingual textual content technology.

Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Knowledge Retrieval Convention (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s captivated with knowledge science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.