
{kind=link}

Transformer structure has enabled massive language fashions (LLMs) to carry out advanced pure language understanding and era duties. On the core of the Transformer is an consideration mechanism designed to assign significance to numerous tokens inside a sequence. Nonetheless, this mechanism distributes consideration inconsistently, usually allocating focus to irrelevant contexts. This phenomenon, often known as “consideration noise,” hinders the mannequin’s means to establish and make the most of key info from prolonged sequences precisely. It turns into particularly problematic in functions corresponding to query answering, summarization, and in-context studying, the place a transparent and exact understanding of the context is crucial.
One of many major challenges researchers face is guaranteeing that these fashions can appropriately establish and give attention to essentially the most related segments of the textual content with out being distracted by the encircling context. This drawback turns into extra pronounced when scaling up the fashions concerning dimension and coaching tokens. The eye noise hampers the retrieval of key info and results in points corresponding to hallucination, the place fashions generate factually incorrect info or fail to comply with logical coherence. As fashions develop bigger, these issues change into more difficult to handle, making it essential to develop new strategies to get rid of or reduce consideration noise.
Earlier strategies to deal with consideration noise have included modifications to the structure, coaching routine, or normalization methods. Nonetheless, these options usually have trade-offs concerning elevated complexity or decreased mannequin effectivity. As an illustration, some methods depend on dynamic consideration mechanisms that modify focus based mostly on context however battle with sustaining constant efficiency in long-context eventualities. Others incorporate superior normalization methods, however they add computational overhead and complexity. In consequence, researchers have been in search of less complicated but efficient methods to boost the efficiency of LLMs with out compromising on scalability or effectivity.
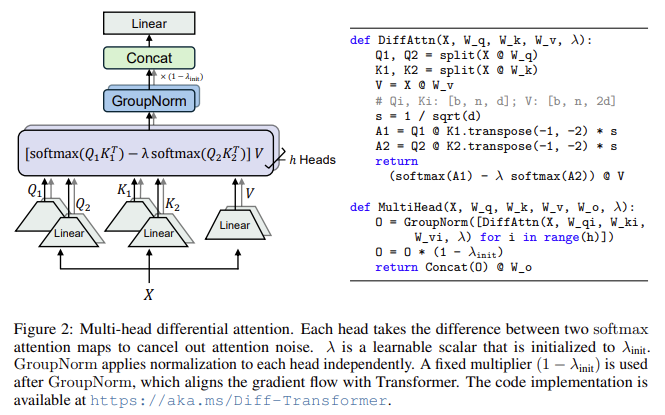
Microsoft Analysis and Tsinghua College researchers have launched a brand new structure referred to as the Differential Transformer (DIFF Transformer). This novel structure addresses the issue of consideration noise by introducing a differential consideration mechanism that successfully filters out irrelevant context whereas amplifying consideration to significant segments. The differential consideration mechanism operates by splitting the question and key vectors into two teams and computing two separate softmax consideration maps. The distinction between these maps serves as the ultimate consideration rating, canceling common-mode noise and enabling the mannequin to pivot extra precisely on the meant info. This method is impressed by ideas from electrical engineering, corresponding to differential amplifiers, the place widespread noise is canceled by taking the distinction between two alerts.
The DIFF Transformer consists of a number of layers containing a differential consideration module and a feed-forward community. It retains the macrostructure of the unique Transformer, guaranteeing compatibility with current architectures whereas introducing improvements on the micro stage. The mannequin incorporates enhancements like pre-RMSNorm and SwiGLU, borrowed from the LLaMA structure, contributing to enhanced stability and effectivity throughout coaching.
The DIFF Transformer outperforms conventional Transformers in a number of key areas. As an illustration, it achieves comparable language modeling efficiency utilizing solely 65% of the mannequin dimension and coaching tokens required by standard Transformers. This interprets right into a 38% discount within the variety of parameters and a 36% lower within the variety of coaching tokens wanted, straight leading to a extra resource-efficient mannequin. When scaled up, a DIFF Transformer with 7.8 billion parameters achieves a language modeling loss much like a 13.1 billion parameter Transformer, thereby matching efficiency whereas utilizing 59.5% fewer parameters. This demonstrates the scalability of the DIFF Transformer, permitting for efficient dealing with of large-scale NLP duties with considerably decrease computational prices.

In a sequence of checks, the DIFF Transformer demonstrated a exceptional functionality for key info retrieval, outperforming the standard Transformer by as much as 76% in duties the place key info was embedded inside the first half of an extended context. In a “Needle-In-A-Haystack” experiment, the place related solutions had been positioned at various positions inside contexts of as much as 64,000 tokens, the DIFF Transformer constantly maintained excessive accuracy, even when distractors had been current. The standard Transformer, compared, noticed a gradual decline in accuracy because the context size elevated, highlighting the superior means of the DIFF Transformer to keep up give attention to related content material.
The DIFF Transformer considerably decreased hallucination charges in comparison with standard fashions. In an in depth analysis utilizing question-answering datasets corresponding to Qasper, HotpotQA, and 2WikiMultihopQA, the DIFF Transformer achieved a 13% greater accuracy in single-document query answering and a 21% enchancment in multi-document query answering. It achieved a mean accuracy acquire of 19% on textual content summarization duties, successfully lowering the era of factually incorrect or deceptive summaries. These outcomes underscore the robustness of the DIFF Transformer in numerous NLP functions.
The differential consideration mechanism additionally improves the steadiness of the DIFF Transformer when coping with context order permutations. On the similar time, conventional Transformers exhibit excessive variance in efficiency when the order of context adjustments. The DIFF Transformer confirmed minimal efficiency fluctuation, indicating higher robustness to order sensitivity. In a comparative analysis, the usual deviation of the DIFF Transformer’s accuracy throughout multiple-order permutations was lower than 2%, whereas the standard Transformer’s variance was over 10%. This stability makes the DIFF Transformer significantly appropriate for functions involving in-context studying, the place the mannequin’s means to make the most of info from a altering context is essential.


In conclusion, the DIFF Transformer introduces a groundbreaking method to addressing consideration noise in massive language fashions. By implementing a differential consideration mechanism, the mannequin can obtain superior accuracy and robustness with fewer sources, positioning it as a promising answer for educational analysis and real-world functions.
Take a look at the Paper and Code Implementation. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication.. Don’t Neglect to hitch our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Information Retrieval Convention (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.