
{kind=link}

[ad_1]
VLMs like LLaVA-Med have superior considerably, providing multi-modal capabilities for biomedical picture and knowledge evaluation, which may help radiologists. Nonetheless, these fashions face challenges, similar to hallucinations and imprecision in responses, resulting in potential misdiagnoses. With radiology departments experiencing elevated workloads and radiologists going through burnout, the necessity for instruments to mitigate these points is urgent. VLMs can help in decoding medical imaging and supply pure language solutions, however their generalization and user-friendliness points hinder their scientific adoption. A specialised “Radiology Assistant” instrument may handle these wants by enhancing report writing and facilitating communication about imaging and analysis.
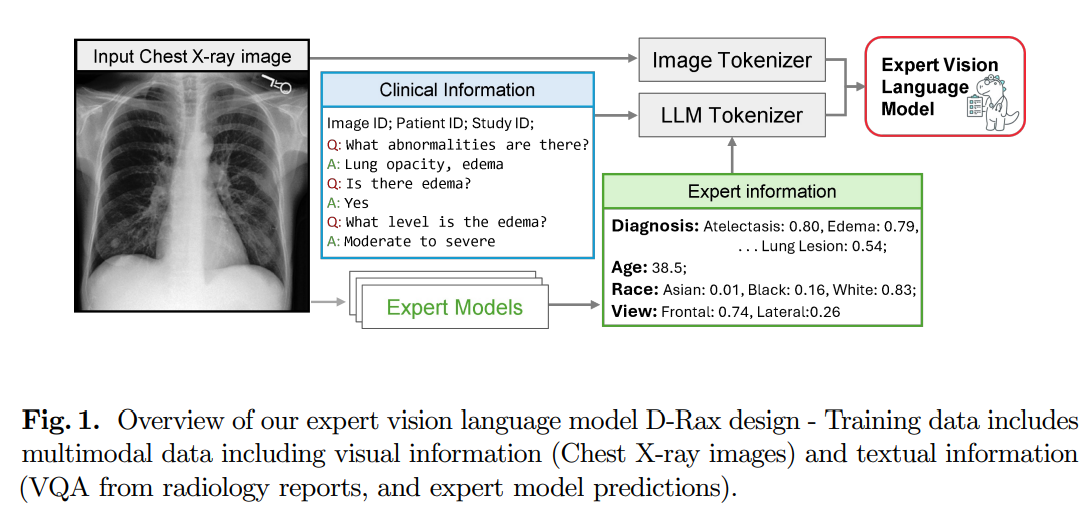
Researchers from the Sheikh Zayed Institute for Pediatric Surgical Innovation, George Washington College, and NVIDIA have developed D-Rax, a specialised instrument for radiological help. D-Rax enhances the evaluation of chest X-rays by integrating superior AI with visible question-answering capabilities. It’s designed to facilitate pure language interactions with medical photos, bettering radiologists’ potential to establish and diagnose circumstances precisely. This mannequin leverages professional AI predictions to coach on a wealthy dataset, together with MIMIC-CXR imaging knowledge and diagnostic outcomes. D-Rax goals to streamline decision-making, cut back diagnostic errors, and assist radiologists of their day by day duties.
The appearance of VLMs has considerably superior the event of multi-modal AI instruments. Flamingo is an early instance that integrates picture and textual content processing by way of prompts and multi-line reasoning. Equally, LLaVA combines visible and textual knowledge utilizing a multi-modal structure impressed by CLIP, which hyperlinks photos to textual content. BioMedClip is a foundational VLM in biomedicine for duties like picture classification and visible question-answering. LLaVA-Med, a model of LLaVA tailored for biomedical functions, helps clinicians work together with medical photos utilizing conversational language. Nonetheless, many of those fashions face challenges similar to hallucinations and inaccuracies, highlighting the necessity for specialised instruments in radiology.
The strategies for this research contain using and enhancing datasets to coach a domain-specific VLM referred to as D-Rax, designed for radiology. The baseline dataset includes MIMIC-CXR photos and Medical-Diff-VQA’s question-answer pairs derived from chest X-rays. Enhanced knowledge embody predictions from professional AI fashions for circumstances like illnesses, affected person demographics, and X-ray views. D-Rax’s coaching employs a multimodal structure with the Llama2 language mannequin and a pre-trained CLIP visible encoder. The fine-tuning course of integrates professional predictions and instruction-following knowledge to enhance the mannequin’s precision and cut back hallucinations in decoding radiologic photos.
The outcomes show that integrating expert-enhanced instruction considerably improves D-Rax’s efficiency on sure radiological questions. For abnormality and presence questions, each open and closed-ended, fashions educated with enhanced knowledge present notable positive factors. Nonetheless, the efficiency stays related throughout fundamental and enhanced knowledge for questions on location, stage, and sort. Qualitative evaluations spotlight D-Rax’s potential to establish points like pleural effusion and cardiomegaly appropriately. The improved fashions additionally deal with complicated queries higher than easy professional fashions, that are restricted to simple questions. Prolonged testing on a bigger dataset reinforces these findings, exhibiting robustness in D-Rax’s capabilities.
D-Rax goals to reinforce precision and cut back errors in responses from VLMs by way of a specialised coaching method that integrates professional predictions. The mannequin achieves extra correct and human-like outputs by embedding professional data on illness, age, race, and look at into CXR evaluation directions. Utilizing datasets like MIMIC-CXR and Medical-Diff-VQA ensures domain-specific insights, lowering hallucinations and bettering response accuracy for open and close-ended questions. This method facilitates higher diagnostic reasoning, improves clinician communication, gives clearer affected person data, and has the potential to raise the standard of scientific care considerably.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 46k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.
[ad_2]