
{kind=link}

[ad_1]
Information annotation is the method of labeling information obtainable in video, textual content, or photographs. Labeled datasets are required for supervised machine studying in order that machines can clearly perceive the enter patterns. In autonomous mobility, annotated datasets are important for coaching self-driving automobiles to acknowledge and reply to highway situations, site visitors indicators, and potential hazards. Within the medical subject, it helps enhance diagnostic accuracy, with labeled medical imaging information enabling AI methods to determine potential well being points extra successfully.
This rising demand underscores the significance of high-quality information annotation in advancing AI and ML purposes throughout numerous sectors.
On this complete information, we’ll talk about every part you want to find out about information annotation. We’ll begin by analyzing the several types of information annotation, from textual content and picture to video and audio, and even cutting-edge strategies like LiDAR annotation. Subsequent, we’ll examine handbook vs. automated annotation and enable you to navigate the construct vs. purchase choice for annotation instruments.
Moreover, we’ll delve into information annotation for giant language fashions (LLMs) and its function in enterprise AI adoption. We’ll additionally stroll you thru the crucial steps within the annotation course of and share knowledgeable ideas and finest practices that can assist you keep away from frequent pitfalls.
What’s information annotation?
Information annotation is the method of labeling and categorizing information to make it usable for machine studying fashions. It entails including significant metadata, tags, or labels to uncooked information, corresponding to textual content, photographs, movies, or audio, to assist machines perceive and interpret the data precisely.
The first aim of knowledge annotation is to create high-quality, labeled datasets that can be utilized to coach and validate machine studying algorithms. By offering machines with annotated information, information scientists and builders can construct extra correct and environment friendly AI fashions that may study from patterns and examples within the information.
With out correctly annotated information, machines would wrestle to grasp and make sense of the huge quantities of unstructured information generated each day.
Forms of information annotation
Information annotation is a flexible course of that may be utilized to numerous information sorts, every with its personal strategies and purposes. The info annotation market is primarily segmented into two essential classes: Pc Imaginative and prescient Sort and Pure Language Processing Sort.
Pc Imaginative and prescient annotation focuses on labeling visible information, whereas Pure Language Processing annotation offers with textual and audio information.
On this part, we’ll discover the most typical kinds of information annotation and their particular use circumstances.
1. Textual content annotation: It entails labeling and categorizing textual information to assist machines perceive and interpret human language. On a regular basis textual content annotation duties embody:
- Sentiment annotation: Figuring out and categorizing the feelings and opinions expressed in a textual content.
- Intent annotation: Figuring out the aim or aim behind a consumer’s message or question.
- Semantic annotation: Linking phrases or phrases to their corresponding meanings or ideas.
- Named entity annotation: Figuring out and classifying named entities corresponding to folks, organizations, and areas inside a textual content.
- Relation annotation: Establishing the relationships between totally different entities or ideas talked about in a textual content.
2. Picture annotation: It entails including significant labels, tags, or bounding packing containers to digital photographs to assist machines interpret and perceive visible content material. This annotation sort is essential for growing laptop imaginative and prescient purposes like facial recognition, object detection, and picture classification.
3. Video annotation: It extends the ideas of picture annotation to video information, permitting machines to grasp and analyze transferring visible content material. This annotation sort is important for autonomous automobiles, video surveillance, and gesture recognition purposes.
4. Audio annotation: It focuses on labeling and transcribing audio information, corresponding to speech, music, and environmental sounds. This annotation sort is important for growing speech recognition methods, voice assistants, and audio classification fashions.
5. LiDAR annotation: Mild Detection and Ranging annotation entails labeling and categorizing 3D level cloud information generated by LiDAR sensors. This annotation sort is more and more important for autonomous driving, robotics, and 3D mapping purposes.
When evaluating the several types of information annotation, it is clear that every has its personal distinctive challenges and necessities. Textual content annotation depends on linguistic experience and context understanding, whereas picture and video annotation requires visible notion expertise. Audio annotation depends upon correct transcription and sound recognition, and LiDAR annotation calls for spatial reasoning and 3D understanding.
The speedy progress of the Information Annotation and Labeling Market displays the rising significance of knowledge annotation in AI and ML improvement. In response to current market analysis, the worldwide market is projected to develop from USD 0.8 billion in 2022 to USD 3.6 billion by 2027 at a compound annual progress fee (CAGR) of 33.2%. This substantial progress underscores information annotation’s crucial function in coaching and bettering AI and ML fashions throughout varied industries.
Information annotation strategies will be broadly categorized into handbook and automatic approaches. Every has its strengths and weaknesses, and the selection typically depends upon the challenge’s particular necessities.
Guide annotation: Guide annotation entails human annotators reviewing and labeling information by hand. This strategy is usually extra correct and might deal with advanced or ambiguous circumstances, however it’s also time-consuming and costly. Guide annotation is especially helpful for duties that require human judgment, corresponding to sentiment evaluation or figuring out refined nuances in photographs or textual content.
Automated annotation: Automated annotation depends on machine studying algorithms to mechanically label information based mostly on predefined guidelines or patterns. This methodology is quicker and less expensive than handbook annotation, but it surely will not be as correct, notably for edge circumstances or subjective duties. Automated annotation is well-suited for large-scale tasks with comparatively easy labeling necessities.
Human-in-the-Loop (HITL) strategy combines the effectivity of automated methods with human experience and judgment. This strategy is essential for growing dependable, correct, moral AI and ML methods.
HITL strategies embody:
- Iterative annotation: People annotate a small subset of knowledge, which is then used to coach an automatic system. The system’s output is reviewed and corrected by people, and the method repeats, regularly bettering the mannequin’s accuracy.
- Energetic studying: An clever system selects essentially the most informative or difficult information samples for human annotation, optimizing the usage of human effort.
- Professional steerage: Area specialists present clarifications and guarantee annotations meet trade requirements.
- High quality management and suggestions: Common human assessment and suggestions assist refine the automated annotation course of and handle rising challenges.
Information annotation instruments
There are many information annotation instruments obtainable out there. When choosing one, make sure that you take into account options intuitive consumer interface, multi-format assist, collaborative annotation, high quality management mechanisms, AI-assisted annotation, scalability and efficiency, information safety and privateness, and integration and API assist.
Prioritizing these options permits for the collection of an information annotation device that meets present wants and scales with future AI and ML tasks.
Among the main business instruments embody:
- Amazon SageMaker Floor Fact: A totally managed information labeling service that makes use of machine studying to label information mechanically.
- Google Cloud Information Labeling Service: Provides a spread of annotation instruments for picture, video, and textual content information.
- Labelbox: A collaborative platform supporting varied information sorts and annotation duties.
- Appen: Supplies each handbook and automatic annotation providers throughout a number of information sorts.
- SuperAnnotate: A complete platform providing AI-assisted annotation, collaboration options, and high quality management for varied information sorts.
- Encord: Finish-to-end answer for growing AI methods with superior annotation instruments and mannequin coaching capabilities.
- Dataloop: AI-powered platform streamlining information administration, annotation, and mannequin coaching with customizable workflows.
- V7: Automated annotation platform combining dataset administration, picture/video annotation, and autoML mannequin coaching.
- Kili: Versatile labeling device with customizable interfaces, highly effective workflows, and high quality management options for numerous information sorts.
- Nanonets: AI-based doc processing platform specializing in automating information extraction with customized OCR fashions and pre-built options.
Open-source options are additionally obtainable, corresponding to:
- CVAT (Pc Imaginative and prescient Annotation Software): An internet-based device for annotating photographs and movies.
- Doccano: A textual content annotation device supporting classification, sequence labeling, and named entity recognition.
- LabelMe: A picture annotation device permitting customers to stipulate and label objects in photographs.
When selecting an information annotation device, take into account elements corresponding to the kind of information you are working with, the dimensions of your challenge, your price range, and any particular necessities for integration along with your present methods.
Construct vs. purchase choice
Organizations should additionally determine whether or not to construct their very own annotation instruments or buy present options. Constructing customized instruments affords full management over options and workflow however requires vital time and sources. Shopping for present instruments is usually less expensive and permits for faster implementation however might require compromises on customization.
Information annotation for giant language fashions (LLMs)
Massive Language Fashions (LLMs) have revolutionized pure language processing, enabling extra subtle and human-like interactions with AI methods. Growing and fine-tuning these fashions require huge quantities of high-quality, annotated information. On this part, we’ll discover the distinctive challenges and strategies concerned in information annotation for LLMs.
Function of RLHF (Reinforcement Studying from Human Suggestions)
RLHF has emerged as an important approach in bettering LLMs. This strategy goals to align the mannequin’s outputs with human preferences and values, making the AI system extra helpful and ethically aligned.
The RLHF course of entails:
- Pre-training a language mannequin on a big corpus of textual content information.
- Coaching a reward mannequin based mostly on human preferences.
- Tremendous-tuning the language mannequin utilizing reinforcement studying with the reward mannequin.
Information annotation performs a significant function within the second step, the place human annotators rank the language mannequin’s outcomes, offering suggestions within the type of sure/no approval or extra nuanced rankings. This course of helps quantify human preferences, permitting the mannequin to study and align with human values and expectations.
Methods and finest practices for annotating LLM information
If the information will not be annotated accurately or constantly, it might trigger vital points in mannequin efficiency and reliability. To make sure high-quality annotations for LLMs, take into account the next finest practices:
- Numerous annotation groups: Guarantee annotators come from diversified backgrounds to scale back bias and enhance the mannequin’s capacity to grasp totally different views and cultural contexts.
- Clear pointers: Develop complete annotation pointers that cowl a variety of eventualities and edge circumstances to make sure consistency throughout annotators.
- Iterative refinement: Repeatedly assessment and replace annotation pointers based mostly on rising patterns and challenges recognized in the course of the annotation course of.
- High quality management: Implement rigorous high quality assurance processes, together with cross-checking annotations and common efficiency evaluations of annotators.
- Moral issues: Be conscious of the potential biases and moral implications of annotated information, and try to create datasets that promote equity and inclusivity.
- Contextual understanding: Encourage annotators to contemplate the broader context when evaluating responses, guaranteeing that annotations mirror nuanced understanding fairly than surface-level judgments. This strategy helps LLMs develop a extra subtle grasp of language and context.
These practices are serving to LLMs present vital enhancements. These fashions are actually being utilized throughout varied fields, together with chatbots, digital assistants, content material technology, sentiment evaluation, and language translation. As LLMs progress, it turns into more and more essential to make sure high-quality information annotation, which presents a problem in balancing large-scale annotation with nuanced, context-aware human judgment.
Information annotation in an enterprise context
For giant organizations, information annotation is not only a activity however a strategic crucial that underpins AI and machine studying initiatives. Enterprises face distinctive challenges and necessities when implementing information annotation at scale, necessitating a considerate strategy to device choice and course of implementation.
Scale and complexity: Enterprises face distinctive challenges with information annotation resulting from their large, numerous datasets. They want sturdy instruments that may deal with excessive volumes throughout varied information sorts with out compromising efficiency. Options like energetic studying, model-assisted labeling, and AI mannequin integration have gotten essential for managing advanced enterprise information successfully.
Customization and workflow integration: One-size-fits-all options not often meet enterprise wants. Organizations require extremely customizable annotation instruments that may adapt to particular workflows, ontologies, and information buildings. Seamless integration with present methods by means of well-documented APIs is essential, permitting enterprises to include annotation processes into their broader information and AI pipelines.
High quality management and consistency: To fulfill enterpise-level wants, you want superior high quality assurance options, together with automated checks, inter-annotator settlement metrics, and customizable assessment workflows. These options guarantee consistency and reliability within the annotated information, which is crucial for coaching high-performance AI fashions.
Safety and compliance: Information safety is paramount for enterprises, particularly these in regulated industries. Annotation instruments should provide enterprise-grade safety features, together with encryption, entry controls, and audit trails. Compliance with rules like GDPR and HIPAA is non-negotiable, making instruments with built-in compliance options extremely engaging.
Implementing these methods will help enterprises harness the ability of knowledge annotation to drive AI innovation and achieve a aggressive edge of their respective industries. Because the AI panorama evolves, firms that excel in information annotation can be higher positioned to leverage new applied sciences and reply to altering market calls for.
The best way to do information annotation?
The aim of the information annotation course of needs to be not simply to label information, however to create invaluable, correct coaching units that allow AI methods to carry out at their finest. Now every enterprise can have distinctive necessities for information annotation, however there are some basic steps that may information the method:
Step 1: Information assortment
Earlier than annotation begins, you want to collect all related information, together with photographs, movies, audio recordings, or textual content information, in a single place. This step is essential as the standard and variety of your preliminary dataset will considerably affect the efficiency of your AI fashions.
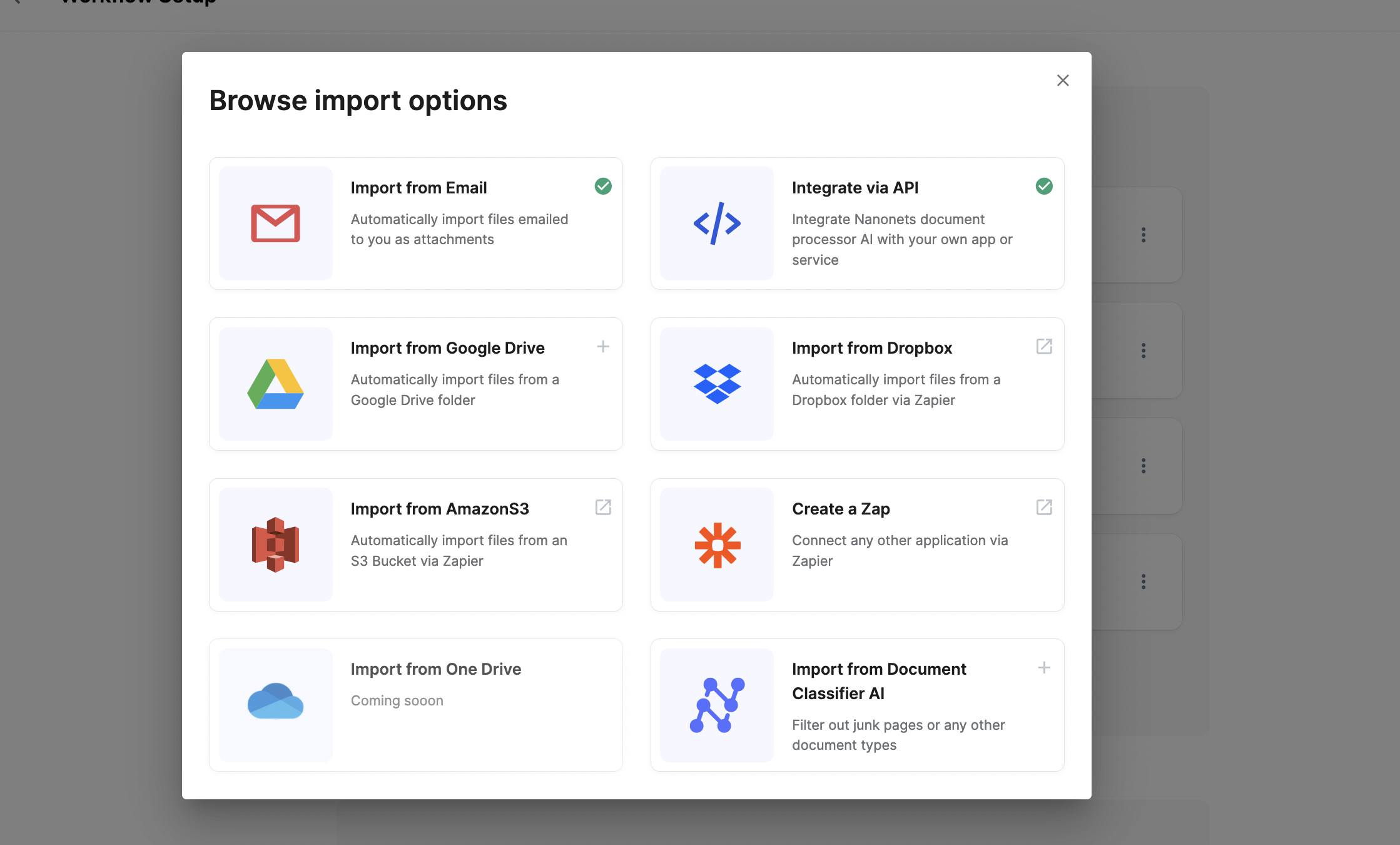
Step 2: Information preprocessing
Preprocessing entails standardizing and enhancing the collected information. This step might embody:
- Deskewing photographs
- Enhancing information high quality
- Formatting textual content
- Transcribing video or audio content material
- Eradicating duplicates or irrelevant information
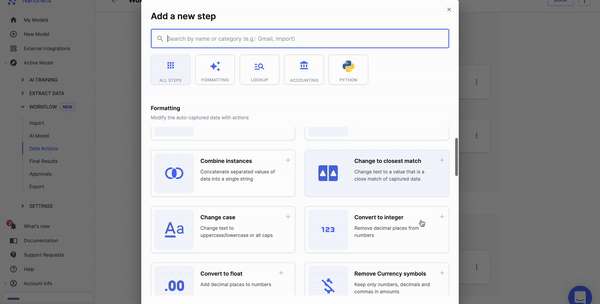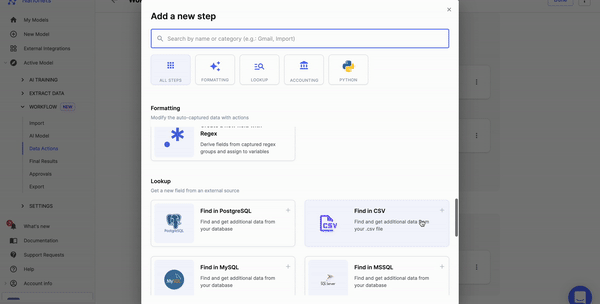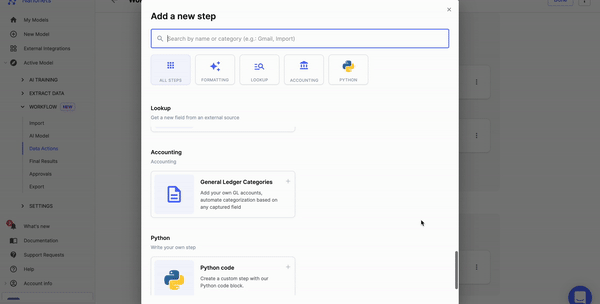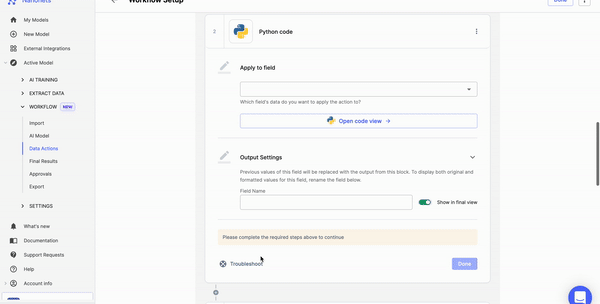
Nanonets can automate information pre-processing with no-code workflows. You’ll be able to select from quite a lot of choices, corresponding to date formatting, information matching, and information verification.
Step 3: Choose the information annotation device
Select an acceptable annotation device based mostly in your particular necessities. Think about elements corresponding to the kind of information you are working with, the dimensions of your challenge, and any particular annotation options you want.
Listed here are some choices:
- Information Annotation – Nanonets
- Picture Annotation – V7
- Video Annotation – Appen
- Doc Annotation – Nanonets
Step 4: Set up annotation pointers
Develop clear, complete pointers for annotators or annotation instruments. These pointers ought to cowl:
- Definitions of labels or classes
- Examples of appropriate and incorrect annotations
- Directions for dealing with edge circumstances or ambiguous information
- Moral issues, particularly when coping with probably delicate content material
Step 5: Annotation
After establishing pointers, the information will be labeled and tagged by human annotators or utilizing information annotation software program. Think about implementing a Human-in-the-Loop (HITL) strategy, which mixes the effectivity of automated methods with human experience and judgment.
Step 6: High quality management
High quality assurance is essential for sustaining excessive requirements. Implement a sturdy high quality management course of, which can embody:
- A number of annotators reviewing the identical information
- Professional assessment of a pattern of annotations
- Automated checks for frequent errors or inconsistencies
- Common updates to annotation pointers based mostly on high quality management findings
You’ll be able to carry out a number of blind annotations to make sure that outcomes are correct.
Step 7: Information export
As soon as information annotation is full and has handed high quality checks, export it within the required format. You should use platforms like Nanonets to seamlessly export information within the format of your option to 5000+ enterprise software program.

The complete information annotation course of can take anyplace from a number of days to a number of weeks, relying on the dimensions and complexity of the information and the sources obtainable. It is essential to notice that information annotation is usually an iterative course of, with steady refinement based mostly on mannequin efficiency and evolving challenge wants.
Actual-world examples and use circumstances
Latest experiences point out that GPT-4, developed by OpenAI, can precisely determine and label cell sorts. This was achieved by analyzing marker gene information in single-cell RNA sequencing. It simply goes to indicate how highly effective AI fashions can turn out to be when educated on precisely annotated information.
In different industries, we see comparable traits of AI augmenting human annotation efforts:
Autonomous Autos: Firms are utilizing annotated video information to coach self-driving automobiles to acknowledge highway components. Annotators label objects like pedestrians, site visitors indicators, and different automobiles in video frames. This course of trains AI methods to acknowledge and reply to highway components.
Healthcare: Medical imaging annotation is rising in recognition for bettering diagnostic accuracy. Annotated datasets are used to coach AI fashions that may detect abnormalities in X-rays, MRIs, and CT scans. This software has the potential to reinforce early illness detection and enhance affected person outcomes.
Pure Language Processing: Annotators label textual content information to assist AI perceive context, intent, and sentiment. This course of enhances the power of chatbots and digital assistants to interact in additional pure and useful conversations.
Monetary providers: The monetary trade makes use of information annotation to reinforce fraud detection capabilities. Specialists label transaction information to determine patterns related to fraudulent exercise. This helps practice AI fashions to detect and forestall monetary fraud extra successfully.
These examples underscore the rising significance of high-quality annotated information throughout varied industries. Nonetheless, as we embrace these technological developments, it is essential to deal with the moral challenges in information annotation practices, guaranteeing honest compensation for annotators and sustaining information privateness and safety.
Ultimate ideas
In the identical method information continues to evolve, information annotation procedures have gotten extra superior. Only a few years in the past, merely labeling a number of factors on a face was sufficient to construct an AI prototype. Now, as many as twenty dots will be positioned on the lips alone.
As we glance to the longer term, we are able to count on much more exact and detailed annotation strategies to emerge. These developments will doubtless result in AI fashions with unprecedented accuracy and capabilities. Nonetheless, this progress additionally brings new challenges, corresponding to the necessity for extra expert annotators and elevated computational sources.
In case you are looking out for a easy and dependable information annotation answer, take into account exploring Nanonets. Schedule a demo to see how Nanonets can streamline your information annotation course of. Find out how the platform automates information extraction from paperwork and annotates paperwork simply to automate any doc duties.
[ad_2]