
{kind=link}

[ad_1]
Autoregressive picture technology fashions have historically relied on vector-quantized representations, which introduce a number of vital challenges. The method of vector quantization is computationally intensive and infrequently leads to suboptimal picture reconstruction high quality. This reliance limits the fashions’ flexibility and effectivity, making it troublesome to precisely seize the complicated distributions of steady picture knowledge. Overcoming these challenges is essential for enhancing the efficiency and applicability of autoregressive fashions in picture technology.
Present strategies for tackling this problem contain changing steady picture knowledge into discrete tokens utilizing vector quantization. Strategies corresponding to Vector Quantized Variational Autoencoders (VQ-VAE) encode pictures right into a discrete latent house after which mannequin this house autoregressively. Nevertheless, these strategies face appreciable limitations. The method of vector quantization is just not solely computationally intensive but additionally introduces reconstruction errors, leading to a lack of picture high quality. Moreover, the discrete nature of those tokenizers limits the fashions’ potential to precisely seize the complicated distributions of picture knowledge, which impacts the constancy of the generated pictures.
A workforce of researchers from MIT CSAIL, Google DeepMind, and Tsinghua College have developed a novel approach that eliminates the necessity for vector quantization. This methodology leverages a diffusion course of to mannequin the per-token likelihood distribution inside a continuous-valued house. By using a Diffusion Loss operate, the mannequin predicts tokens with out changing knowledge into discrete tokens, thus sustaining the integrity of the continual knowledge. This revolutionary technique addresses the shortcomings of present strategies by enhancing the technology high quality and effectivity of autoregressive fashions. The core contribution lies within the software of diffusion fashions to foretell tokens autoregressively in a steady house, which considerably improves the pliability and efficiency of picture technology fashions.

The newly launched approach makes use of a diffusion course of to foretell continuous-valued vectors for every token. Beginning with a loud model of the goal token, the method iteratively refines it utilizing a small denoising community conditioned on earlier tokens. This denoising community, carried out as a Multi-Layer Perceptron (MLP), is educated alongside the autoregressive mannequin by backpropagation utilizing the Diffusion Loss operate. This operate measures the discrepancy between the expected noise and the precise noise added to the tokens. The strategy has been evaluated on giant datasets like ImageNet, showcasing its effectiveness in enhancing the efficiency of autoregressive and masked autoregressive mannequin variants.
The outcomes reveal vital enhancements in picture technology high quality, as evidenced by key efficiency metrics such because the Fréchet Inception Distance (FID) and Inception Rating (IS). Fashions utilizing Diffusion Loss persistently obtain decrease FID and better IS in comparison with these utilizing conventional cross-entropy loss. Particularly, the masked autoregressive fashions (MAR) with Diffusion Loss obtain an FID of 1.55 and an IS of 303.7, indicating a considerable enhancement over earlier strategies. This enchancment is noticed throughout varied mannequin variants, confirming the efficacy of this new strategy in boosting each the standard and velocity of picture technology, reaching technology charges of lower than 0.3 seconds per picture.
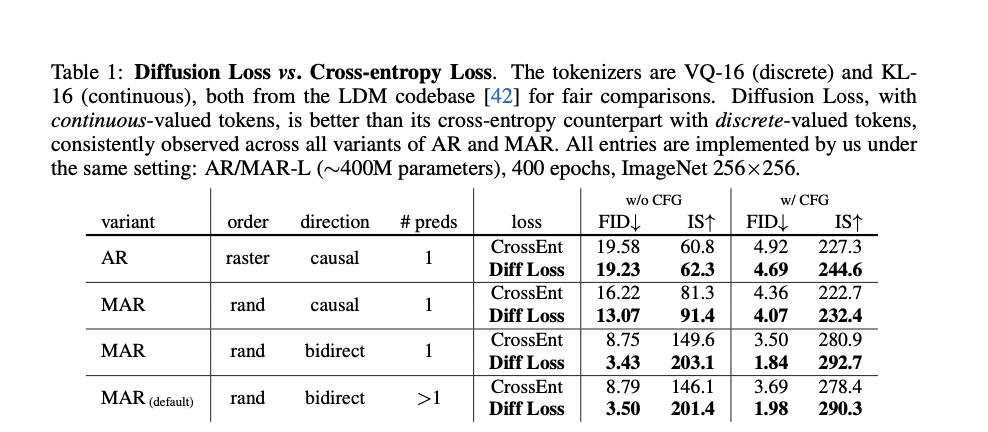

In conclusion, the revolutionary diffusion-based approach gives a groundbreaking resolution to the problem of dependency on vector quantization in autoregressive picture technology. By introducing a technique to mannequin continuous-valued tokens, the researchers considerably improve the effectivity and high quality of autoregressive fashions. This novel technique has the potential to revolutionize picture technology and different continuous-valued domains, offering a sturdy resolution to a essential problem in AI analysis.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 45k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s captivated with knowledge science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.
[ad_2]