
{kind=link}

[ad_1]
The vulnerability of AI techniques, significantly giant language fashions (LLMs) and multimodal fashions, to adversarial assaults can result in dangerous outputs. These fashions are designed to help and supply useful responses, however adversaries can manipulate them to supply undesirable and even harmful outputs. The assaults exploit inherent weaknesses within the fashions, elevating issues about their security and reliability. Present defenses, equivalent to refusal coaching and adversarial coaching, have important limitations, usually compromising mannequin efficiency with out successfully stopping dangerous outputs.
Present strategies to enhance AI mannequin alignment and robustness embody refusal coaching and adversarial coaching. Refusal coaching teaches fashions to reject dangerous prompts, however refined adversarial assaults usually bypass these safeguards. Adversarial coaching entails exposing fashions to adversarial examples throughout coaching to enhance robustness, however this methodology tends to fail towards new, unseen assaults and might degrade the mannequin’s efficiency.
To deal with these shortcomings, a staff of researchers from Black Swan AI, Carnegie Mellon College, and Heart for AI Security proposes a novel methodology that entails short-circuiting. Impressed by illustration engineering, this strategy instantly manipulates the inner representations liable for producing dangerous outputs. As a substitute of specializing in particular assaults or outputs, short-circuiting interrupts the dangerous technology course of by rerouting the mannequin’s inner states to impartial or refusal states. This methodology is designed to be attack-agnostic and doesn’t require extra coaching or fine-tuning, making it extra environment friendly and broadly relevant.
The core of the short-circuiting methodology is a way referred to as Illustration Rerouting (RR). This system intervenes within the mannequin’s inner processes, significantly the representations that contribute to dangerous outputs. By modifying these inner representations, the strategy prevents the mannequin from finishing dangerous actions, even below robust adversarial strain.
Experimentally, RR was utilized to a refusal-trained Llama-3-8B-Instruct mannequin. The outcomes confirmed a major discount within the success fee of adversarial assaults throughout varied benchmarks with out sacrificing efficiency on customary duties. As an illustration, the short-circuited mannequin demonstrated decrease assault success charges on HarmBench prompts whereas sustaining excessive scores on functionality benchmarks like MT Bench and MMLU. Moreover, the strategy proved efficient in multimodal settings, bettering robustness towards image-based assaults and making certain the mannequin’s harmlessness with out impacting its utility.
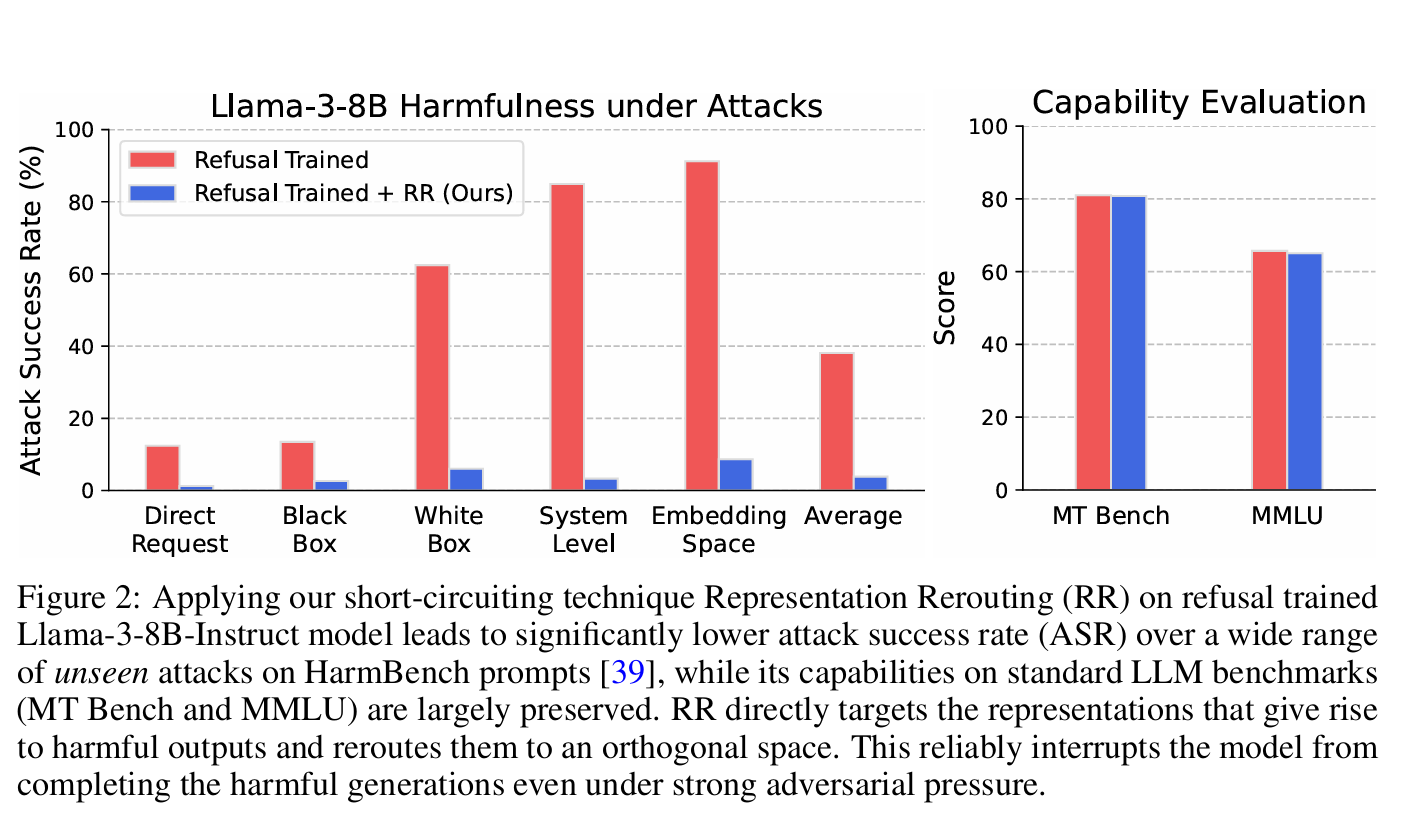
The short-circuiting methodology operates through the use of datasets and loss features tailor-made to the duty. The coaching information is split into two units: the Quick Circuit Set and the Retain Set. The Quick Circuit Set comprises information that triggers dangerous outputs, and the Retain Set contains information that represents protected or desired outputs. The loss features are designed to regulate the mannequin’s representations to redirect dangerous processes to incoherent or refusal states, successfully short-circuiting the dangerous outputs.
The issue of AI techniques producing dangerous outputs resulting from adversarial assaults is a major concern. Present strategies like refusal coaching and adversarial coaching have limitations that the proposed short-circuiting methodology goals to beat. By instantly manipulating inner representations, short-circuiting presents a strong, attack-agnostic answer that maintains mannequin efficiency whereas considerably enhancing security and reliability. This strategy represents a promising development within the improvement of safer AI techniques.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Neglect to hitch our 44k+ ML SubReddit
Shreya Maji is a consulting intern at MarktechPost. She is pursued her B.Tech on the Indian Institute of Expertise (IIT), Bhubaneswar. An AI fanatic, she enjoys staying up to date on the newest developments. Shreya is especially within the real-life functions of cutting-edge expertise, particularly within the subject of knowledge science.
[ad_2]