
{kind=link}

[ad_1]

Picture by writer
Machine studying is a kind of laptop algorithm that helps machines study with out the necessity for specific programming.
Immediately, we see purposes of machine studying all over the place — in navigation methods, film streaming platforms, and ecommerce purposes.
In actual fact, from the time you get up within the morning till you go to mattress, you might be more likely to have interacted with dozens of machine studying fashions with out even realizing it.
The machine studying {industry} is projected to develop by over 36% between 2024 to 2030.
Given that nearly each massive group is actively investing in AI, you solely stand to learn from honing your machine studying expertise.
Whether or not you’re a information science fanatic, developer, or an on a regular basis one that desires to enhance your data within the topic, listed here are 5 commonly-used machine studying fashions you need to find out about:
1. Linear Regression
Linear regression is the preferred machine studying mannequin used to carry out quantitative duties.
This algorithm is used to foretell a steady consequence (y) utilizing a number of unbiased variables (X).
For instance, you’d use linear regression if given the duty to foretell home costs based mostly on their measurement.
On this case, the home measurement is your unbiased variable X which will probably be used to foretell the home worth, which is the unbiased variable.
That is finished by becoming a linear equation that fashions the connection between X and y, represented by y=mX+c.
Here’s a diagram representing a linear regression that fashions the connection between home worth and measurement:
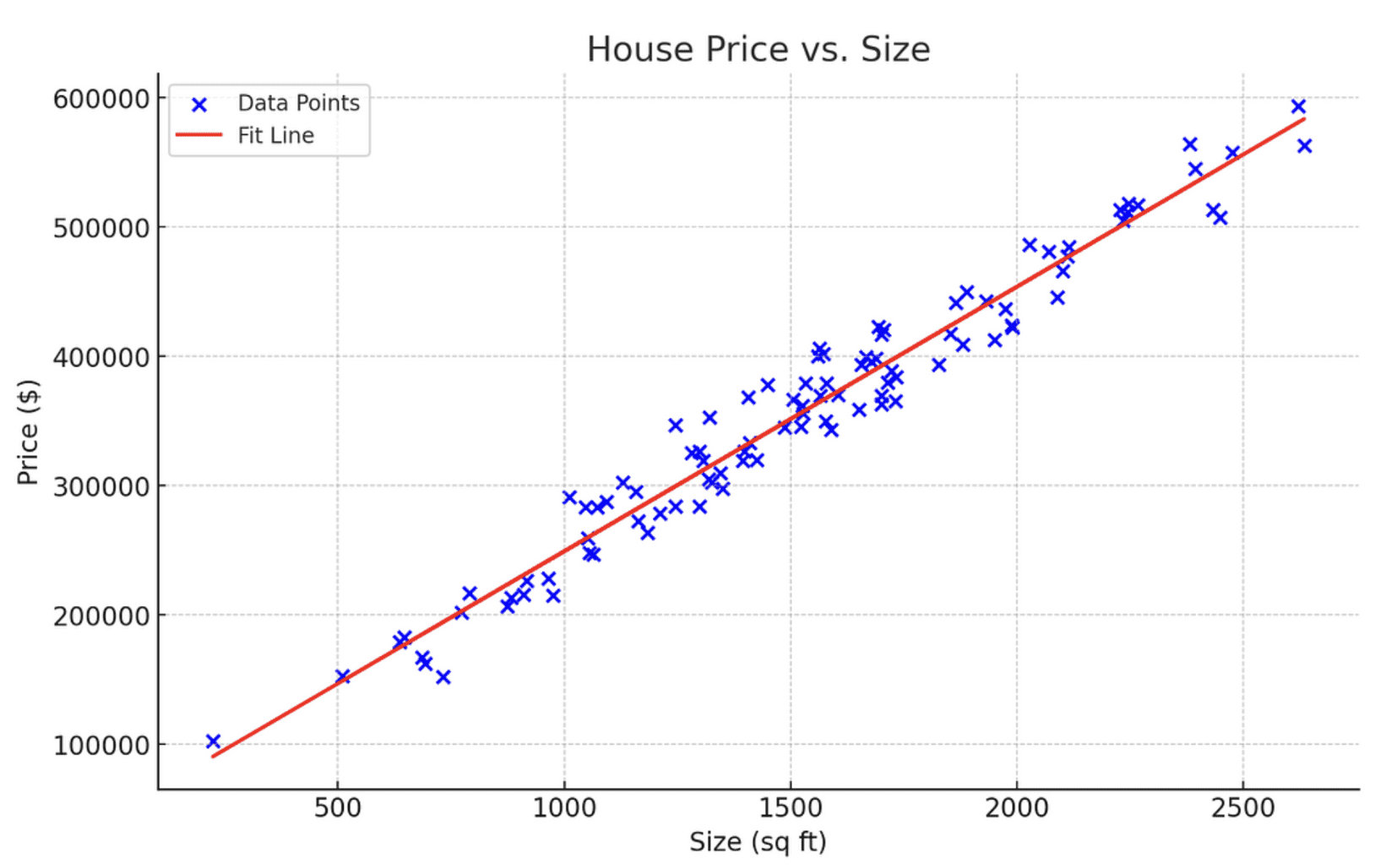
Picture by writer
To study extra in regards to the instinct behind linear regression and the way it works mathematically, I like to recommend watching Krish Naik’s YouTube tutorial on the topic.
2. Logistic Regression
Logistic regression is a classification mannequin used to foretell a discrete consequence given a number of unbiased variables.
For instance, given the variety of unfavorable key phrases in a sentence, logistic regression can be utilized to foretell whether or not a given message needs to be categorized as reputable or spam.
Here’s a chart displaying how logistic regression works:

Picture by writer
As indicated within the curve above, because the variety of unfavorable key phrases will increase, so does the chance of the message being categorized as spam.
The x-axis of this curve represents the variety of unfavorable key phrases, and the y-axis exhibits the chance of the e-mail being spam.
Usually, in logistic regression, a chance of 0.5 or better signifies a optimistic consequence — on this context, it signifies that the message is spam.
Conversely, a chance of lower than 0.5 signifies a unfavorable consequence, which means the message shouldn’t be spam.
Studying Useful resource
In the event you’d prefer to study extra about logistic regression, StatQuest’s logistic regression tutorial is a good place to begin.
3. Choice Bushes
Choice timber are a well-liked machine studying mannequin used for each classification and regression duties.
They work by breaking the dataset down based mostly on its options, making a tree-like construction to mannequin this information.
In easy phrases, resolution timber enable us to repeatedly break up information based mostly on particular parameters till a last resolution is made.
Right here is an instance of a easy resolution tree figuring out whether or not an individual ought to eat ice-cream on a given day:

Picture by writer
- The tree begins with the climate, figuring out whether or not it’s conducive to eat ice-cream.
- If the climate is heat, you then proceed to the subsequent node, well being. In any other case, the choice is not any and there are not any extra splits.
- On the subsequent node, if the particular person is wholesome, they will eat the ice-cream. In any other case, they need to chorus from doing so.
Discover how the information splits on every node within the resolution tree, breaking the classification course of down into easy, manageable questions.
You possibly can draw an analogous resolution tree for regression duties with a quantitative consequence, and the instinct behind the method would stay the identical.
Studying Useful resource
To study extra about resolution timber, I recommend watching StatsQuest’s video tutorial on the subject.
4. Random Forests
The random forest mannequin combines the predictions made by a number of resolution timber and returns a single output.
Intuitively, this mannequin ought to carry out higher than a single resolution tree as a result of it leverages the capabilities of a number of predictive fashions.
That is finished with the assistance of a way often known as bagging, or bootstrap aggregation.
Right here’s how bagging works:
A statistical method known as bootstrap is used to pattern the dataset a number of occasions with alternative.
Then, a choice tree is educated on every pattern dataset. The output of all of the timber are lastly mixed to render a single prediction.
Within the case of a regression drawback, the ultimate output is generated by averaging the predictions made by every resolution tree. For classification issues, a majority class prediction is made.
Studying Useful resource
You possibly can watch Krish Naik’s tutorial on random forests to study extra in regards to the concept and instinct behind the mannequin.
5. Ok-Means Clustering
To date, all of the machine studying fashions we’ve mentioned fall underneath the umbrella of a way known as supervised studying.
Supervised studying is a way that makes use of a labeled dataset to coach algorithms to foretell an consequence.
In distinction, unsupervised studying is a way that doesn’t cope with labeled information. As an alternative, it identifies patterns in information with out being educated on what particular outcomes to search for.
Ok-Means clustering is an unsupervised studying mannequin that primarily ingests unlabeled information and assigns every information level to a cluster.
The observations belong to the cluster with the closest imply.
Here’s a visible illustration of the Ok-Means clustering mannequin:
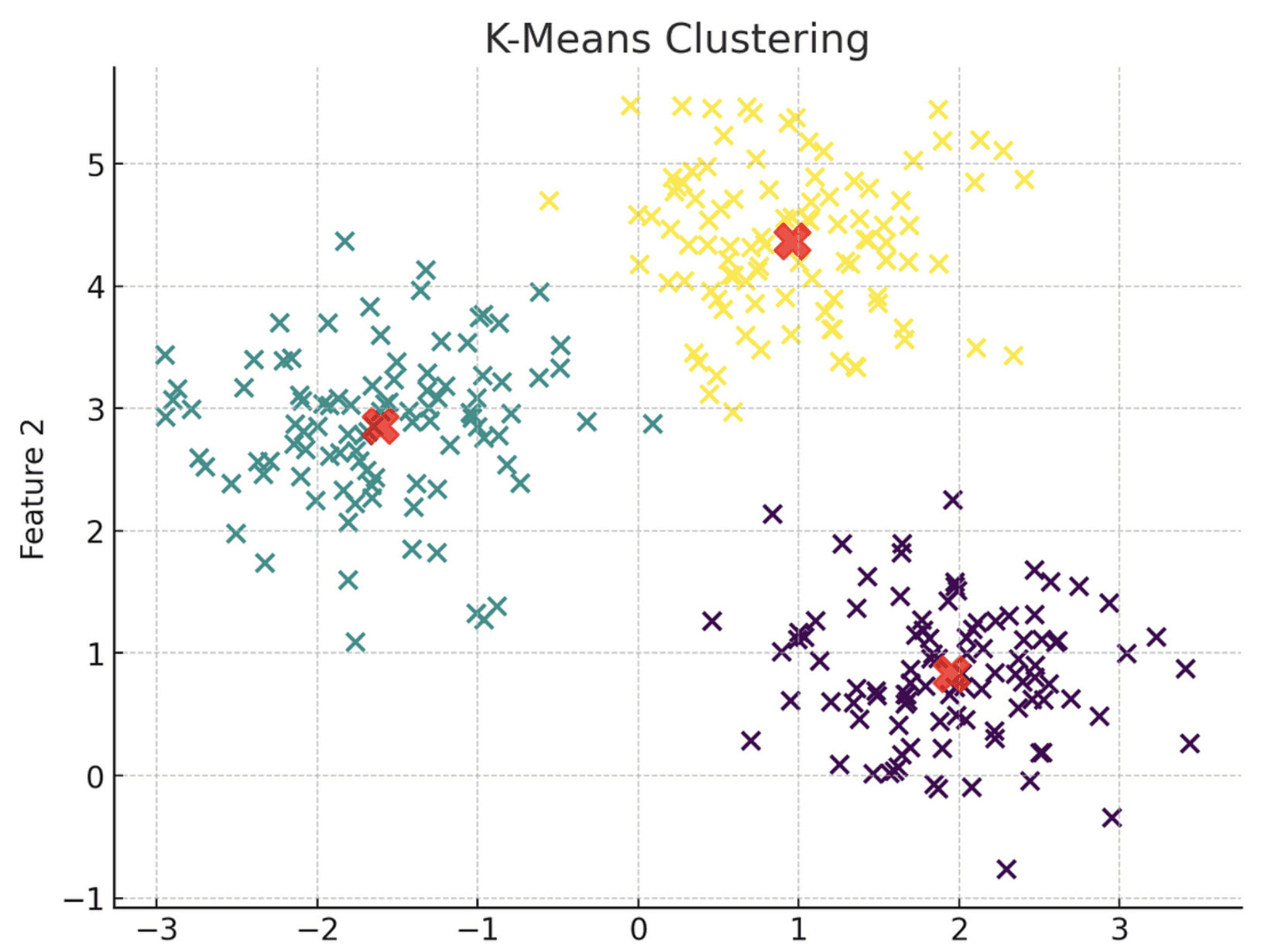
Picture by writer
Merely put, all information factors inside Cluster 1 share related traits, which is why they’re grouped collectively. The identical precept applies to Clusters 2 and three.
When constructing a Ok-Means clustering mannequin, you have to explicitly specify the variety of clusters you’d prefer to generate.
This may be completed utilizing a way known as the elbow methodology, which merely plots the mannequin’s error scores with varied cluster values on a line chart. Then, you select the inflection level of the curve, or its “elbow” because the optimum variety of clusters.
Here’s a visible illustration of the elbow methodology:

Picture by writer
Studying Useful resource
In the event you’d prefer to study extra in regards to the matter, StatQuest has an
8-minute video that clearly explains the workings behind Ok-Means clustering.
Subsequent Steps
The machine studying algorithms defined on this article are generally utilized in industry-wide purposes equivalent to forecasting, spam detection, mortgage approval, and buyer segmentation.
In the event you’ve managed to observe alongside until right here, congratulations! You now have a strong grasp of essentially the most broadly used predictive algorithms, and have taken step one to enterprise into the sector of machine studying.
However the journey doesn’t finish right here.
To cement your understanding of machine studying fashions and have the ability to apply them to real-world purposes, I recommend studying a programming language like Python or R.
Freecodecamp’s Python for Inexperienced persons course
course is a good place to begin. If you end up caught in your programming journey, I’ve a YouTube video that explains how one can study to code from scratch.
When you study to code, it is possible for you to to implement these fashions in apply utilizing libraries like Scikit-Be taught and Keras.
To boost your information science and machine studying expertise, I recommend making a tailor-made studying path for your self utilizing generative AI fashions like ChatGPT. Here’s a extra detailed roadmap that can assist you get began with using ChatGPT to study information science.
Natassha Selvaraj is a self-taught information scientist with a ardour for writing. Natassha writes on all the pieces information science-related, a real grasp of all information subjects. You possibly can join along with her on LinkedIn or take a look at her YouTube channel.
[ad_2]