
{kind=link}


Picture by Creator | DALLE-3
It has at all times been tedious to coach Massive Language Fashions. Even with intensive help from public platforms like HuggingFace, the method contains establishing totally different scripts for every pipeline stage. From establishing information for pretraining, fine-tuning, or RLHF to configuring the mannequin from quantization and LORAs, coaching an LLM requires laborious handbook efforts and tweaking.
The latest launch of LLama-Manufacturing unit in 2024 goals to resolve the precise drawback. The GitHub repository makes establishing mannequin coaching for all levels in an LLM lifecycle extraordinarily handy. From pretraining to SFT and even RLHF, the repository gives built-in help for the setup and coaching of all the most recent out there LLMs.
Supported Fashions and Information Codecs
The repository helps all of the latest fashions together with LLama, LLava, Mixtral Combination-of-Specialists, Qwen, Phi, and Gemma amongst others. The total checklist may be discovered right here. It helps pretraining, SFT, and main RL strategies together with DPO, PPO, and, ORPO permits all the most recent methodologies from full-finetuning to freeze-tuning, LORAs, QLoras, and Agent Tuning.
Furthermore, additionally they present pattern datasets for every coaching step. The pattern datasets typically comply with the alpaca template though the sharegpt format can be supported. We spotlight the Alpaca information formatting under for a greater understanding of arrange your proprietary information.
Word that when utilizing your information, you need to edit and add details about your information file within the dataset_info.json file within the Llama-Manufacturing unit/information folder.
Pre-training Information
The information supplied is saved in a JSON file and solely the textual content column is used for coaching the LLM. The information must be within the format given under to arrange pre-training.
[
{"text": "document"},
{"text": "document"}
]
Supervised Wonderful-Tuning Information
In SFT information, there are three required parameters; instruction, enter, and output. Nevertheless, system and historical past may be handed optionally and can be used to coach the mannequin accordingly if supplied within the dataset.
The final alpaca format for SFT information is as given:
[
{
"instruction": "human instruction (required)",
"input": "human input (optional)",
"output": "model response (required)",
"system": "system prompt (optional)",
"history": [
["human instruction in the first round (optional)", "model response in the first round (optional)"],
["human instruction in the second round (optional)", "model response in the second round (optional)"]
]
}
]
Reward Modeling Information
Llama-Manufacturing unit gives help to coach an LLM for desire alignment utilizing RLHF. The information format should present two totally different responses for a similar instruction, which should spotlight the desire of the alignment.
The higher aligned response is handed to the chosen key and the more severe response is handed to the rejected parameter. The information format is as follows:
[
{
"instruction": "human instruction (required)",
"input": "human input (optional)",
"chosen": "chosen answer (required)",
"rejected": "rejected answer (required)"
}
]
Setup and Set up
The GitHub repository gives help for straightforward set up utilizing a setup.py and necessities file. Nevertheless, it’s suggested to make use of a clear Python setting when establishing the repository to keep away from dependency and bundle clashes.
Despite the fact that Python 3.8 is a minimal requirement, it is suggested to put in Python 3.11 or above. Clone the repository from GitHub utilizing the command under:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Manufacturing unit.git
cd LLaMA-Manufacturing unit
We will now create a recent Python setting utilizing the instructions under:
python3.11 -m venv venv
supply venv/bin/activate
Now, we have to set up the required packages and dependencies utilizing the setup.py file. We will set up them utilizing the command under:
pip set up -e ".[torch,metrics]"
It will set up all required dependencies together with torch, trl, speed up, and different packages. To make sure appropriate set up, we must always now be capable to use the command line interface for Llama-Manufacturing unit. Working the command under ought to output the utilization assist info on the terminal as proven within the picture.

This must be printed on the command line if the set up was profitable.
Finetuning LLMs
We will now begin coaching an LLM! That is as simple as writing a configuration file and invoking a bash command.
Word {that a} GPU is a should to coach an LLM utilizing Llama-factory.
We select a smaller mannequin to save lots of on GPU reminiscence and coaching sources. On this instance, we’ll carry out LORA-based SFT for Phi3-mini-Instruct. We select to create a yaml configuration file however you should use a JSON file as effectively.
Create a brand new config.yaml file as follows. This configuration file is for SFT coaching, and yow will discover extra examples of assorted strategies within the examples listing.
### mannequin
model_name_or_path: microsoft/Phi-3.5-mini-instruct
### methodology
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### dataset
dataset: alpaca_en_demo
template: llama3
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/phi-3/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### prepare
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
Though it’s self-explanatory, we have to give attention to two vital components of the configuration file.
Configuring Dataset for Coaching
The given title of the dataset is a key parameter. Additional particulars for the dataset should be added to the dataset_info.json file within the information listing earlier than coaching. This info contains crucial details about the precise information file path, the info format adopted, and the columns for use from the info.
For this tutorial, we use the alpaca_demo dataset which incorporates questions and solutions associated to English. You may view the entire dataset right here.
The information will then be mechanically loaded from the supplied info. Furthermore, the dataset key accepts an inventory of comma-separated values. Given an inventory, all of the datasets can be loaded and used to coach the LLM.
Configuring Mannequin Coaching
Altering the coaching kind in Llama-Manufacturing unit is as simple as altering a configuration parameter. As proven under, we solely want the under parameters to arrange LORA-based SFT for the LLM.
### methodology
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
We will change SFT with pre-training and reward modeling with precise configuration information out there within the examples listing. You may simply change the SFT to reward modeling by altering the given parameters.
Begin Coaching an LLM
Now, we have now the whole lot arrange. All that’s left is invoking a bash command passing the configuration file as a command line enter.
Invoke the command under:
llamafactory-cli prepare config.yaml
This system will mechanically arrange all required datasets, fashions, and pipelines for the coaching. It took me 10 minutes to coach one epoch on a TESLA T4 GPU. The output mannequin is saved within the output_dir supplied within the config.yaml.
Inference
The inference is even less complicated than coaching a mannequin. We want a configuration file much like coaching offering the bottom mannequin and the trail to the educated LORA adapter.
Create a brand new infer_config.yaml file and supply values for the given keys:
model_name_or_path: microsoft/Phi-3.5-mini-instruct
adapter_name_or_path: saves/phi3-8b/lora/sft/ # Path to educated mannequin
template: llama3
finetuning_type: lora
We will chat with the educated mannequin immediately on the command line with this command:
llamafactory-cli chat infer_config.yaml
It will load the mannequin with the educated adaptor and you may simply chat utilizing the command line, much like different packages like Ollama.
A pattern response on the terminal is proven within the picture under:
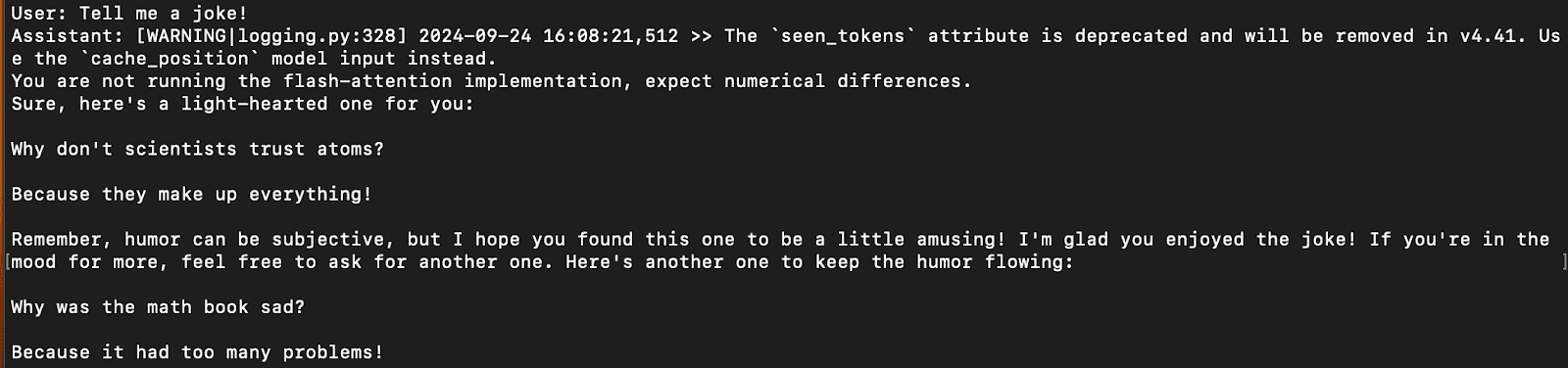
Results of Inference
WebUI
If that was not easy sufficient, Llama-factory gives a no-code coaching and inference possibility with the LlamaBoard.
You can begin the GUI utilizing the bash command:
This begins a web-based GUI on localhost as proven within the picture. We will select the mannequin, and coaching parameters, load and preview the dataset, set hyperparameters, prepare and infer all on the GUI.
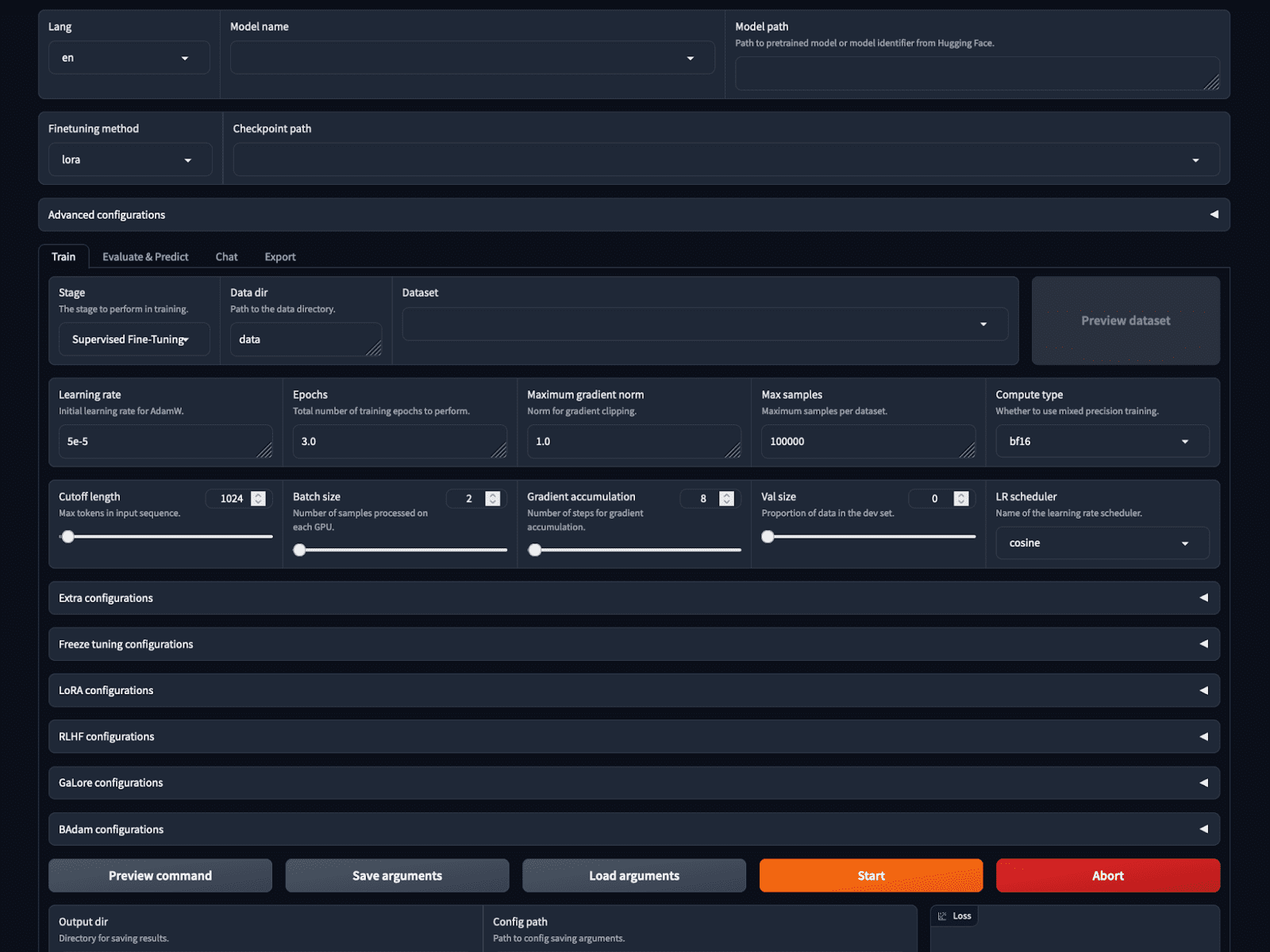
Screenshot of the LlamaBoard WebUI
Conclusion
Llama-factory is quickly changing into common with over 30 thousand stars on GitHub now. It makes it significantly less complicated to configure and prepare an LLM from scratch eradicating the necessity for manually establishing the coaching pipeline for varied strategies.
It helps all the most recent strategies and fashions and nonetheless claims to be 3.7 instances quicker than ChatGLM’s P-Tuning whereas using much less GPU reminiscence. This makes it simpler for regular customers and lovers to coach their LLMs utilizing minimal code.
Kanwal Mehreen Kanwal is a machine studying engineer and a technical author with a profound ardour for information science and the intersection of AI with medication. She co-authored the book “Maximizing Productiveness with ChatGPT”. As a Google Era Scholar 2022 for APAC, she champions variety and educational excellence. She’s additionally acknowledged as a Teradata Variety in Tech Scholar, Mitacs Globalink Analysis Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having based FEMCodes to empower ladies in STEM fields.
Our High 3 Companion Suggestions
![]()
![]() 1. Finest VPN for Engineers – Keep safe & non-public on-line with a free trial
1. Finest VPN for Engineers – Keep safe & non-public on-line with a free trial
![]()
![]() 2. Finest Mission Administration Device for Tech Groups – Increase crew effectivity at the moment
2. Finest Mission Administration Device for Tech Groups – Increase crew effectivity at the moment
![]()
![]() 4. Finest Community Administration Device – Finest for Medium to Massive Firms
4. Finest Community Administration Device – Finest for Medium to Massive Firms