
{kind=link}

The demand for customizable, open fashions that may run effectively on varied {hardware} platforms has grown, and Meta is on the forefront of catering to this demand. Meta open-sourced the discharge of Llama 3.2, that includes small and medium-sized imaginative and prescient LLMs (11B and 90B), together with light-weight, text-only fashions (1B and 3B) designed for edge and cellular gadgets, out there in each pre-trained and instruction-tuned variations. Llama 3.2 addresses these wants with a set of each light-weight and sturdy fashions, which have been optimized for varied duties, together with text-only and vision-based purposes. These fashions are specifically designed for edge gadgets, making AI extra accessible to builders and enterprises.
Mannequin Variants Launched
The Llama 3.2 launched two classes of fashions on this iteration of the Llama Sequence:
- Imaginative and prescient LLMs (11B and 90B): These are the biggest fashions for advanced picture reasoning duties similar to document-level understanding, visible grounding, and picture captioning. They’re aggressive with different closed fashions available in the market and surpass them in varied picture understanding benchmarks.
- Light-weight Textual content-only LLMs (1B and 3B): These smaller fashions are designed for edge AI purposes. They supply sturdy efficiency for summarization, instruction following, and immediate rewriting duties whereas sustaining a low computational footprint. The fashions even have a token context size of 128,000, considerably bettering over earlier variations.
Each pre-trained and instruction-tuned variations of those fashions can be found, with help from Qualcomm, MediaTek, and Arm, making certain that builders can deploy these fashions straight on cellular and edge gadgets. The fashions have been made out there for instant obtain and use by way of llama.com, Hugging Face, and accomplice platforms like AMD, AWS, Google Cloud, and Dell.
Technical Developments and Ecosystem Assist
One of the crucial notable enhancements in Llama 3.2 is the introduction of adapter-based structure for imaginative and prescient fashions, the place picture encoders are built-in with pre-trained textual content fashions. This structure permits for deep picture and textual content information reasoning, considerably increasing the use instances for these fashions. The pre-trained fashions underwent in depth fine-tuning, together with coaching on large-scale noisy image-text pair information and post-training on high-quality, in-domain datasets.
Llama 3.2’s sturdy ecosystem help is one other important consider its revolutionary potential. With partnerships throughout main tech firms, AWS, Databricks, Dell, Microsoft Azure, NVIDIA, and others, Llama 3.2 has been optimized for each on-premise and cloud environments. Additionally, Llama Stack distributions simplify deployment for builders, providing turnkey options for edge, cloud, and on-device environments. The distributions, similar to PyTorch ExecuTorch for on-device deployments and Ollama for single-node setups, additional solidify the flexibility of those fashions.
Efficiency Metrics
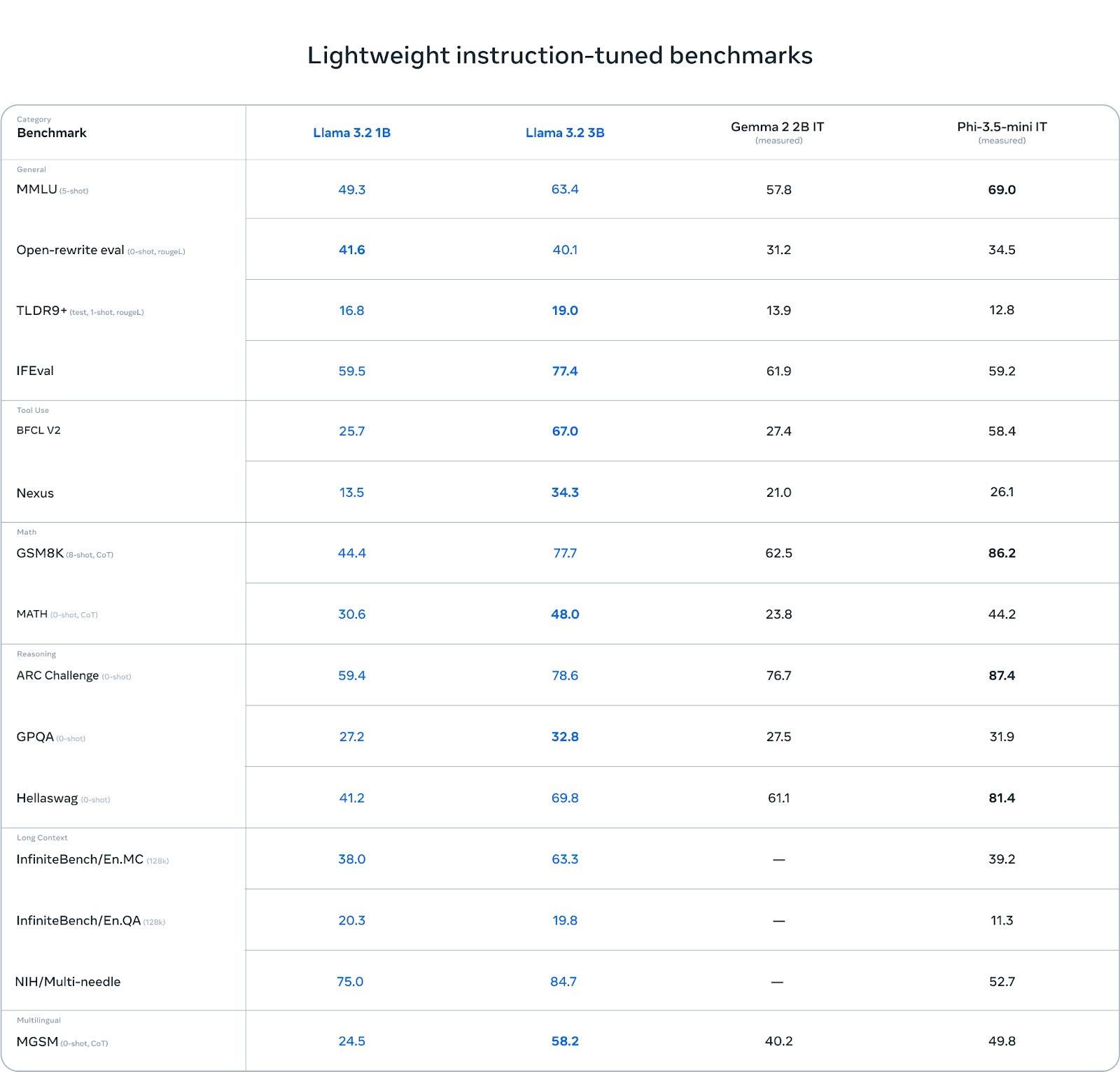
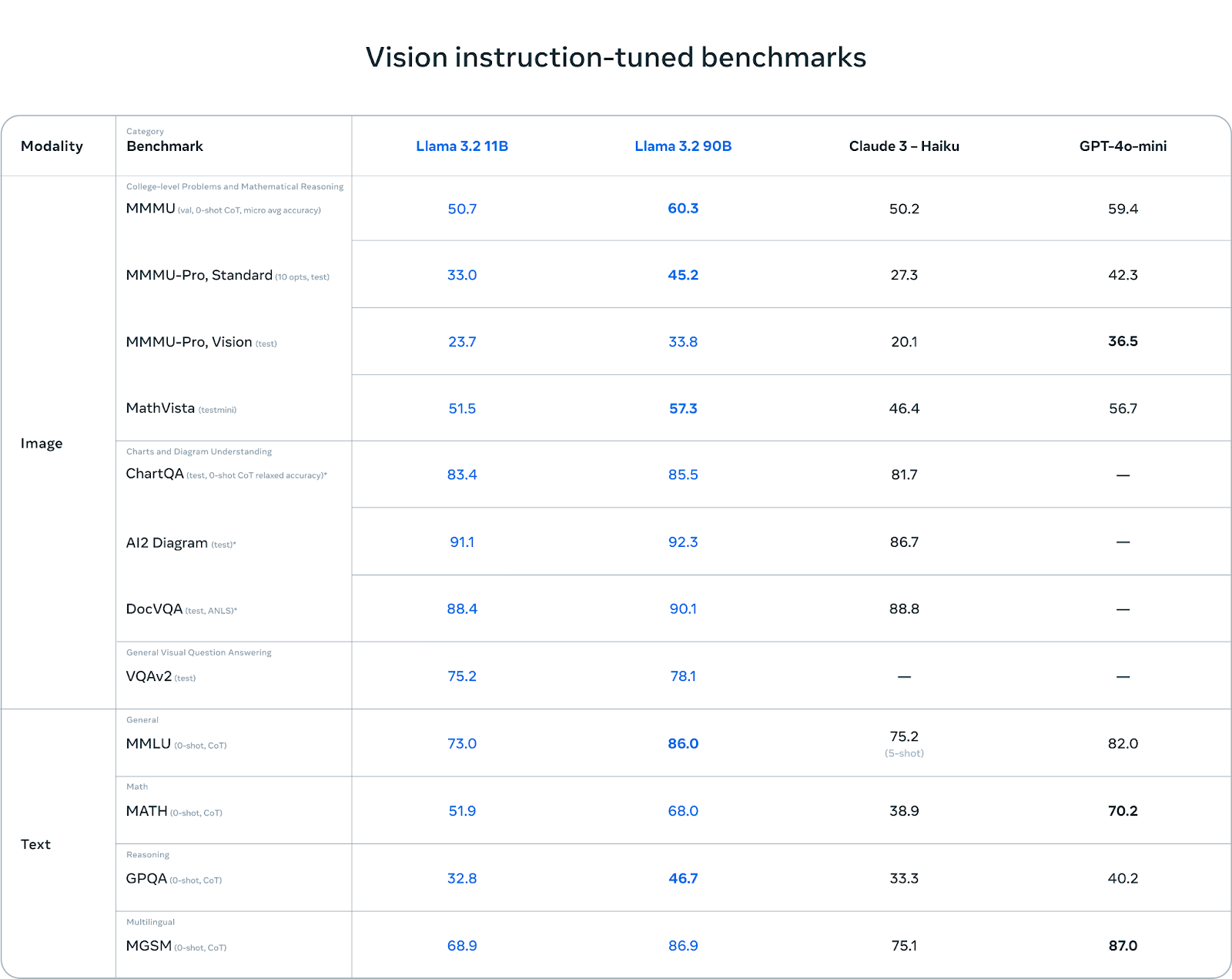
Llama 3.2’s variants ship spectacular efficiency throughout each textual content and imaginative and prescient duties. The light-weight 1B and 3B text-only fashions, optimized for edge and cellular gadgets, excel in summarization, instruction following, and immediate rewriting whereas sustaining a token context size of 128K. These fashions outperform rivals like Gemma 2.6B and Phi 3.5-mini in a number of benchmarks. On the imaginative and prescient aspect, the 11B and 90B fashions show superior capabilities in picture understanding, reasoning, and visible grounding duties, outperforming closed fashions like Claude 3 Haiku and GPT4o-mini on key benchmarks. These fashions effectively bridge textual content and picture reasoning, making them preferrred for multimodal purposes.
The Energy of Light-weight Fashions
The introduction of light-weight fashions in Llama 3.2, particularly the 1B and 3B variants, is essential for edge computing and privacy-sensitive purposes. Working domestically on cellular gadgets ensures that the information stays on the gadget, enhancing consumer privateness by avoiding cloud-based processing. That is notably useful in situations similar to summarizing private messages or producing motion objects from conferences with out sending delicate data to exterior servers. Meta employed pruning and data distillation strategies to attain small mannequin sizes whereas retaining excessive efficiency. The 1B and 3B fashions had been pruned from bigger Llama 3.1 fashions, utilizing structured pruning to take away much less essential parameters with out sacrificing the general mannequin high quality. Information distillation was used to impart data from bigger fashions, additional bettering the efficiency of those light-weight fashions.
Llama 3.2 Imaginative and prescient: Powering Picture Reasoning with 11B and 90B Fashions
The 11B and 90B imaginative and prescient LLMs in Llama 3.2 are constructed for superior picture reasoning and understanding duties, introducing a wholly new mannequin structure seamlessly integrating picture and textual content capabilities. These fashions can deal with document-level comprehension, picture captioning, and visible grounding duties. As an example, the 11B and 90B fashions can analyze enterprise charts to find out the very best gross sales month or navigate advanced visible information similar to maps to offer insights into terrain or distances. The cross-attention mechanism, developed by integrating a pre-trained picture encoder with the language mannequin, permits these fashions to excel at extracting particulars from photos and creating significant, coherent captions that bridge the hole between textual content and visible information. This structure makes the 11B and 90B fashions aggressive with closed fashions similar to Claude 3 Haiku and GPT4o-mini in visible reasoning benchmarks, surpassing them in duties requiring deep multimodal understanding. They’ve been optimized for fine-tuning and customized utility deployments utilizing open-source instruments like torchtune and torchchat.
Key Takeaways from the Llama 3.2 launch:
- New Mannequin Introductions: Llama 3.2 introduces two new classes of fashions: the 1B and 3B light-weight, text-only fashions and the 11B and 90B imaginative and prescient multimodal fashions. The 1B and 3B fashions, designed for edge and cellular gadget use, leverage 9 trillion tokens for coaching, offering state-of-the-art efficiency for summarization, instruction following, and rewriting duties. These smaller fashions are perfect for on-device purposes as a result of their decrease computational calls for. In the meantime, the bigger 11B and 90B imaginative and prescient fashions carry multimodal capabilities to the Llama suite, excelling at advanced picture and textual content understanding duties and setting them aside from earlier variations.
- Enhanced Context Size: One of many vital developments in Llama 3.2 is the help for a 128K context size, notably within the 1B and 3B fashions. This prolonged context size permits for extra in depth enter to be processed concurrently, bettering duties requiring lengthy doc evaluation, similar to summarization and document-level reasoning. It additionally permits these fashions to deal with massive quantities of knowledge effectively.
- Information Distillation for Light-weight Fashions: The 1B and 3B fashions in Llama 3.2 profit from a distillation course of from bigger fashions, particularly the 8B and 70B variants from Llama 3.1. This distillation course of transfers data from bigger fashions to the smaller ones, enabling the light-weight fashions to attain aggressive efficiency with considerably lowered computational overhead, making them extremely appropriate for resource-constrained environments.
- Imaginative and prescient Fashions Skilled on Large Knowledge: The imaginative and prescient language fashions (VLMs), the 11B and 90B, had been educated on an enormous dataset of 6 billion image-text pairs, equipping them with sturdy multimodal capabilities. These fashions combine a CLIP-type MLP with GeLU activation for the imaginative and prescient encoder, differing from Llama 3’s MLP structure, which makes use of SwiGLU. This design alternative enhances their skill to deal with advanced visible understanding duties, making them extremely efficient for picture reasoning and multimodal interplay.
- Superior Imaginative and prescient Structure: The imaginative and prescient fashions in Llama 3.2 incorporate superior architectural options similar to regular layer norm for the imaginative and prescient encoder fairly than the RMS Layernorm seen in different fashions and embody a gating multiplier utilized to hidden states. This gating mechanism makes use of a tanh activation perform to scale the vector from -1 to 1, serving to fine-tune the imaginative and prescient fashions’ outputs. These architectural improvements contribute to improved accuracy and effectivity in visible reasoning duties.
- Efficiency Metrics: The evaluations for Llama 3.2’s fashions present promising outcomes. The 1B mannequin achieved a 49.3 rating on the MMLU, whereas the 3B mannequin scored 63.4. The 11B imaginative and prescient multimodal mannequin scored 50.7 on the MMMU, whereas the 90B mannequin scored 60.3 on the imaginative and prescient aspect. These metrics spotlight the aggressive fringe of Llama 3.2’s fashions in text-based and imaginative and prescient duties, particularly in comparison with different main fashions.
- Integration with UnslothAI for Pace and Effectivity: The 1B and 3B fashions are absolutely built-in with UnslothAI, enabling 2x sooner finetuning, 2x sooner inference, and 70% much less VRAM utilization. This integration additional enhances the usability of those fashions in real-time purposes. Work is underway to combine the 11B and 90B VLMs into the UnslothAI framework, extending these pace and effectivity advantages to the bigger multimodal fashions.
These developments make Llama 3.2 a flexible, highly effective suite of fashions suited to a variety of purposes, from light-weight, on-device AI options to extra advanced multimodal duties requiring large-scale picture and textual content understanding.
Conclusion
The discharge of Llama 3.2 represents a major milestone within the evolution of edge AI and imaginative and prescient fashions. Its open and customizable structure, sturdy ecosystem help, and light-weight, privacy-centric fashions provide a compelling answer for builders and enterprises seeking to combine AI into their edge and on-device purposes. The supply of small and enormous fashions ensures that customers can choose the variant greatest suited to their computational assets and use instances.
Try the Fashions on Hugging Face and Particulars. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.