
{kind=link}

Introduction
Giant Language Fashions or LLMs, have been all the fashion for the reason that introduction of ChatGPT in 2022. That is largely because of the success of the transformer structure and availability of terabytes value of textual content information over the web. Regardless of their fame, LLMs are basically restricted to working solely with texts.
A VLM is value 1000 LLMs
Imaginative and prescient Language Fashions or VLMs are AI fashions that use each pictures and textual information to carry out duties that basically want each of them. With how good LLMs have turn out to be, constructing high quality VLMs has turn out to be the following logical step in direction of Synthetic Normal Intelligence.
On this article, let’s perceive the basics of VLMs with a concentrate on tips on how to construct one. All through this text, we’ll cowl the most recent papers within the analysis and can present with related hyperlinks to the papers.
To provide an outline, within the following sections, we’ll cowl following matters:
- The functions of VLMs
- The historic background of VLMs, together with their origins and components contributing to their rise.
- A taxonomy of various VLM architectures, with examples for every class.
- An outline of key parts concerned in coaching VLMs, together with notable papers that utilized these parts.
- A evaluation of datasets used to coach numerous VLMs, highlighting what made them distinctive.
- Analysis benchmarks used to match mannequin efficiency, explaining why sure evaluations are essential for particular functions.
- State-of-the-art VLMs in relation to those benchmarks.
- A bit specializing in VLMs for doc understanding and main fashions for extracting data from paperwork.
- Lastly, we’ll conclude with key issues to contemplate for choosing up a VLM in your use case.
A few disclaimers:
VLMs work with texts and pictures, and there are a category of fashions known as Picture Turbines that do the next:
- Picture Era from textual content/immediate: Generate pictures from scratch that observe an outline
- Picture Era from textual content and picture: Generate pictures that resemble a given picture however are modified as per the outline
Whereas these are nonetheless thought-about VLMs on a technicality, we is not going to be speaking about them because the analysis concerned is basically completely different. Our protection can be unique to VLMs that generate textual content as output.
There exists one other class of fashions, often known as Multimodal-LLMs (MLLMs). Though they sound just like VLMs, MLLMs are a broader class that may work with numerous combos of picture, video, audio, and textual content modalities. In different phrases, VLMs are only a subset of MLLMs.
Lastly, the figures for mannequin architectures and benchmarks have been taken from the respective papers previous the figures.
Purposes of VLMs
Listed here are some easy functions that solely VLMs can remedy –
Picture Captioning: Routinely generate textual content describing the photographs️

Dense Captioning: Producing a number of captions with a concentrate on describing all of the salient options/objects within the picture

Occasion Detection: Detection of objects with bounding packing containers in a picture

Visible Query Answering (VQA): Questioning (textual content) and answering (textual content) about a picture️

Picture Retrieval or Textual content to Picture discovery: Discovering pictures that match a given textual content description (Kind of the other of Picture Captioning)

Zero Shot Picture classification: The important thing distinction of this process from common picture classification is that it goals to categorize new courses with out requiring extra coaching.

Artificial information era: Given the capabilities of LLMs and VLMs, we have developed quite a few methods to generate high-quality artificial information by leveraging variations in picture and textual content outputs from these fashions. Exploring these strategies alone may very well be sufficient for a complete thesis! That is normally accomplished to coach extra succesful VLMs for different duties
Variations of above talked about functions can be utilized in medical, industrial, academic, finance, e-commerce and plenty of different domains the place there are massive volumes of pictures and texts to work with. We have now listed some examples beneath
- Automating Radiology Report Era by way of Dense Picture Captioning in Medical Diagnostics.
- Defect detection in manufacturing and automotive industries utilizing zeroshot/fewshot picture classification.
- Doc retrieval in monetary/authorized domains
- Picture Search in e-commerce might be turbo charged with VLMs by permitting the search queries to be as nuanced as attainable.
- Summarizing and answering questions based mostly on diagrams in training, analysis, authorized and monetary domains.
- Creating detailed descriptions of merchandise and its specs in e-commerce,
- Generic Chatbots that may reply person’s questions based mostly on a pictures.
- Aiding Visually Impaired by describing their present scene and textual content within the scene. VLMs can present related contextual details about the person’s surroundings, considerably enhancing their navigation and interplay with the world.
- Fraud detection in journalism, and finance industries by flagging suspicious articles.
Historical past
Earliest VLMs have been in mid 2010s. Two of essentially the most profitable makes an attempt have been Present and Inform and Visible Query Answering. The explanation for the success of those two papers can be the elemental idea what makes a VLM work – Facilitate efficient communication between visible and textual representations, by adjusting picture embeddings from a visible spine to make them appropriate with a textual content spine. The sector as such by no means actually took off on account of lack of enormous quantity of knowledge or good architectures.
The primary promising mannequin in 2020s was CLIP. It addressed the shortage of coaching information by leveraging the huge variety of pictures on the web accompanied by captions and alt-text. Not like conventional supervised fashions, which deal with every image-caption pair as a single information level, CLIP utilized contrastive studying to rework the issue right into a one-image-to-many-text comparability process. This method successfully multiplied the variety of information factors to coach on, enabling for a more practical coaching.
When CLIP was launched, the transformer structure had already demonstrated its versatility and reliability throughout numerous domains, solidifying its standing as a go-to alternative for researchers. Nevertheless they have been largely focussed solely on textual content associated duties.️ ViT was the landmark paper that proved transformers might be additionally used for picture duties. The discharge of LLMs together with the promise of ViT has successfully paved approach for the fashionable VLMs that we all know.
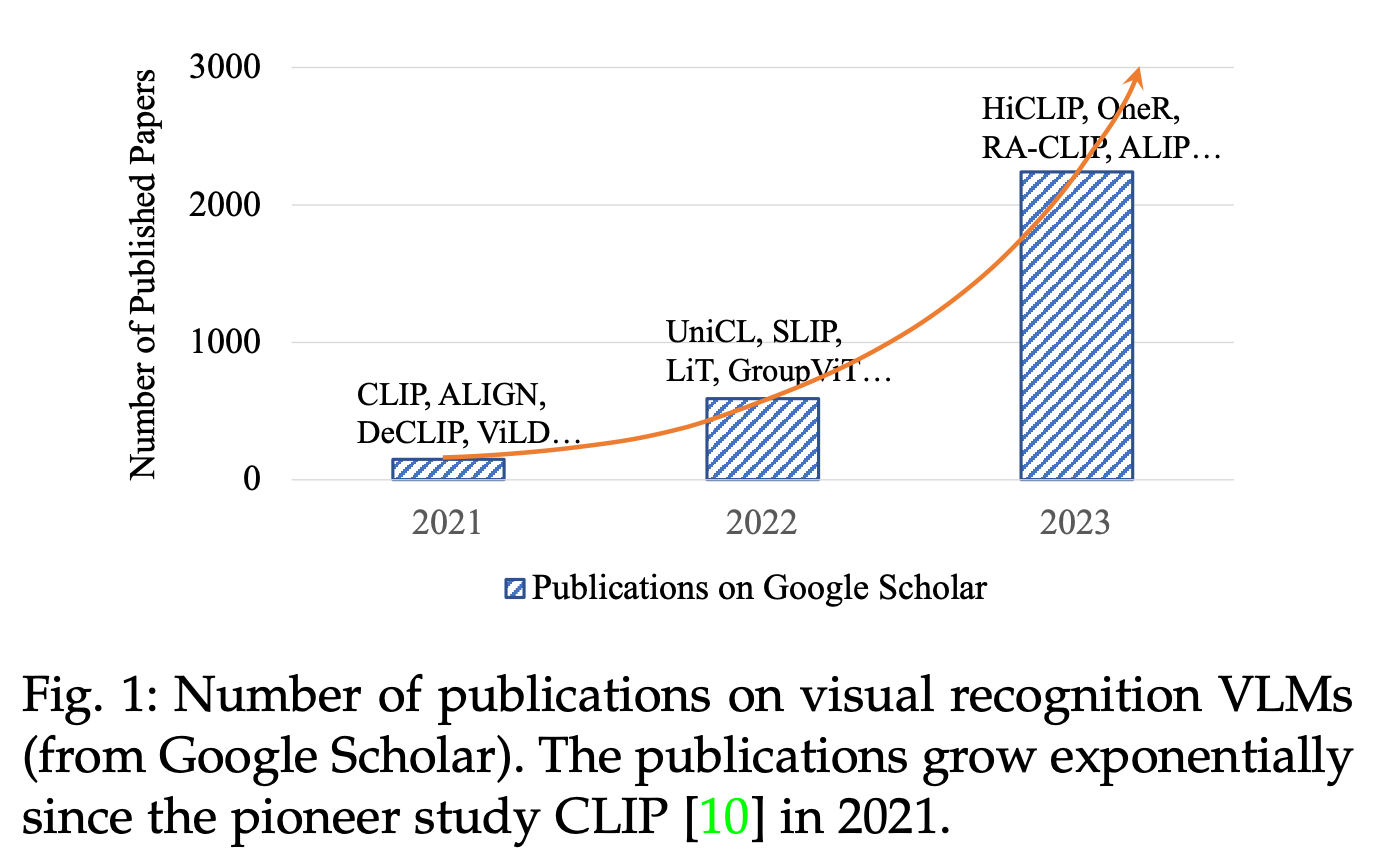
Here is a picture giving the variety of VLM publications over the previous few years
VLM Architectures
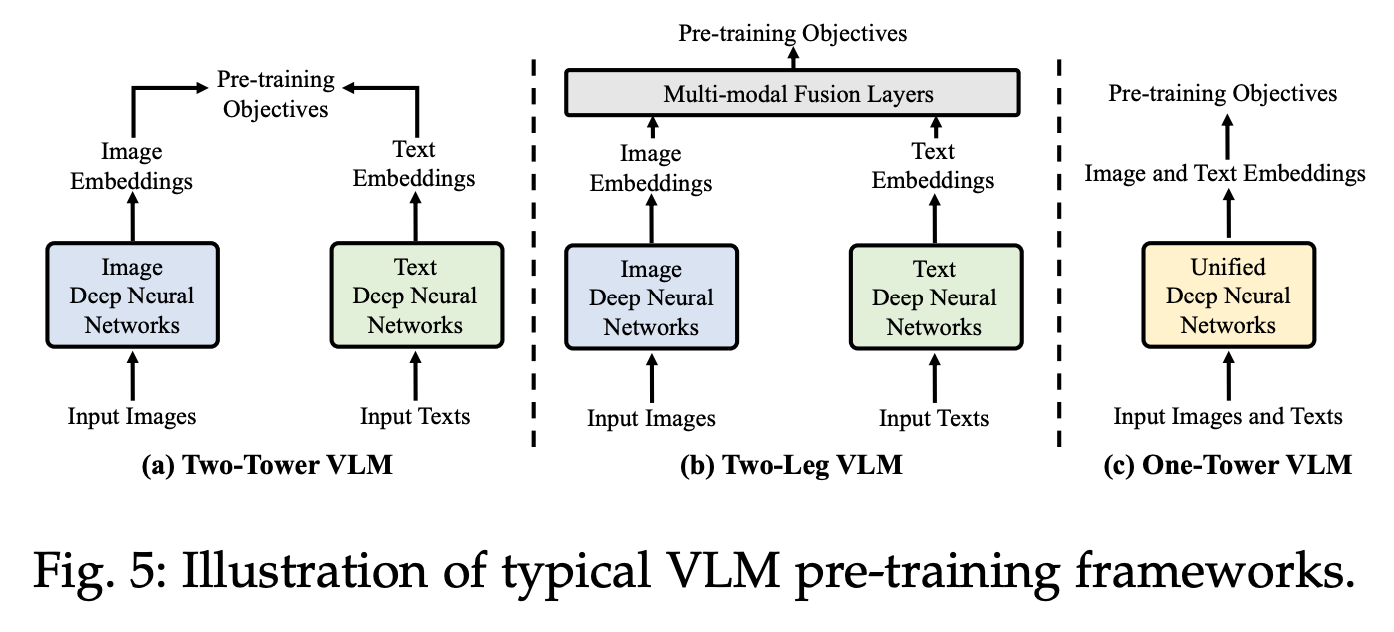
As mentioned within the above part, one of many essential side of VLM is tips on how to convey picture embeddings into the textual content embedding area. The architectures are usually of the three
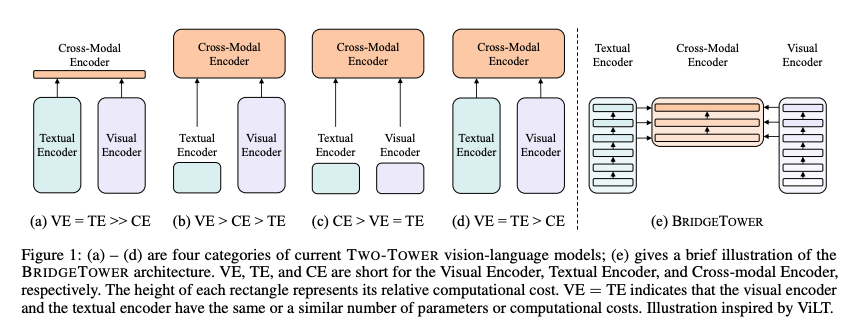
- Two-Tower VLM the place the one connection between imaginative and prescient and textual content networks is on the remaining layer. CLIP is the basic instance for this
- Two-Leg VLM the place a single LLM takes textual content tokens together with tokens from imaginative and prescient encoder.
- Unified VLM the place the spine is attending to visible and textual inputs on the identical time
Remember that there isn’t any exhausting taxonomy and there can be exceptions. With that, following are the widespread ways in which have VLMs have proven promise.
- Shallow/Early Fusion
- Late Fusion
- Deep Fusion
Let’s focus on every one in every of them beneath.
Shallow/Early fusion
A standard function of the architectures on this part is that the connection between imaginative and prescient inputs and language happens early within the course of. Usually, this implies the imaginative and prescient inputs are minimally remodeled earlier than getting into the textual content area, therefore the time period “shallow”. When a well-aligned imaginative and prescient encoder is established, it will probably successfully deal with a number of picture inputs, a functionality that even refined fashions typically battle to achieve!
Let’s cowl the 2 kinds of early fusion strategies beneath.
Imaginative and prescient Encoder
This is among the easiest. Guarantee your imaginative and prescient encoder outputs are appropriate with an LLMs inputs and simply practice the imaginative and prescient encoder whereas preserving the LLM frozen.
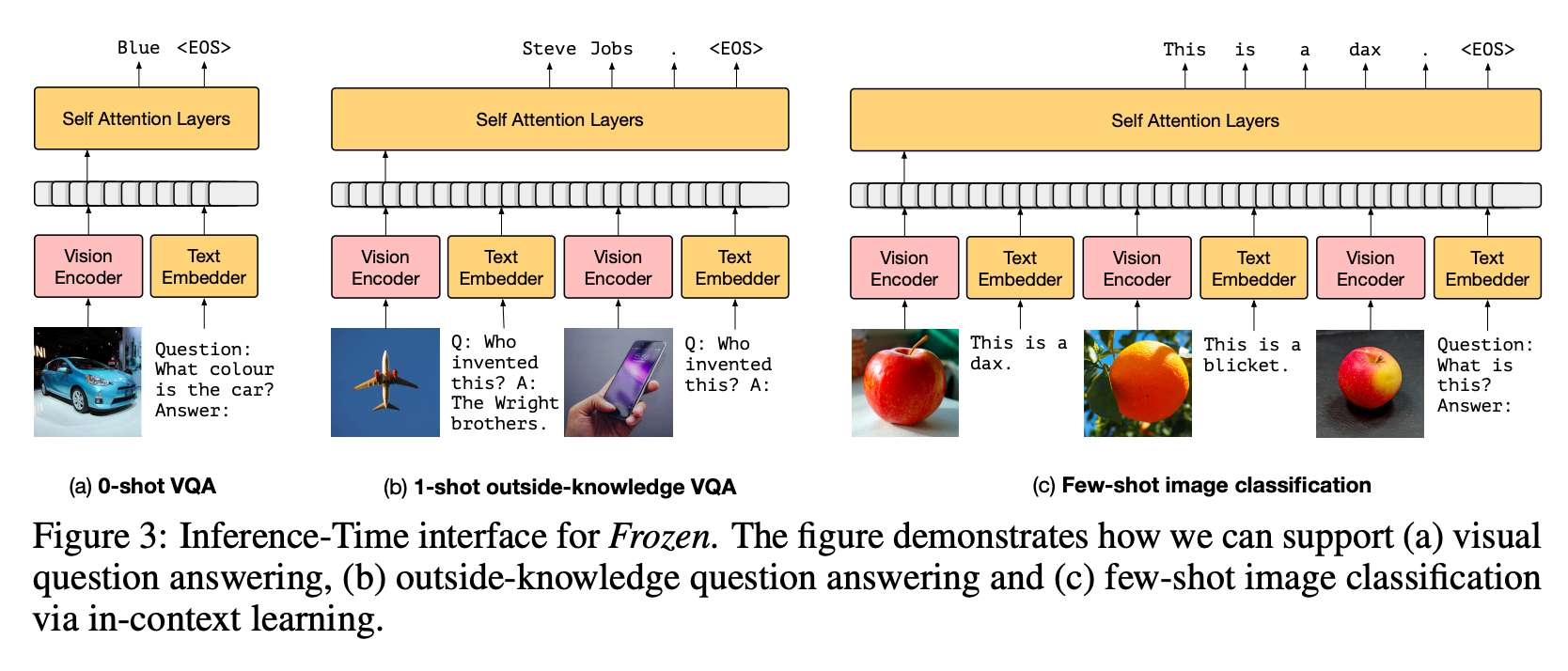
The structure is actually an LLM (particularly a decoder solely transformer) with a department for a picture encoder. It is quick to code, straightforward to grasp and normally doesn’t want writing any new layers.
These architectures have the identical loss as LLMs (i.e., the standard of subsequent token prediction)
Frozen is an instance of such implementation. Along with coaching the imaginative and prescient encoder, the tactic employs prefix-tuning, which includes attaching a static token to all visible inputs. This setup permits the imaginative and prescient encoder to regulate itself based mostly on the LLM’s response to the prefix.
Imaginative and prescient Projector/Adapter
Concern with utilizing only a Imaginative and prescient Encoder is that it is troublesome to make sure the imaginative and prescient encoder’s outputs are appropriate with the LLM, limiting the variety of decisions for Imaginative and prescient,LLM pairs. What is simpler is to have an intermediate layer between Imaginative and prescient and LLM networks that makes this output from Imaginative and prescient appropriate with LLM. With the projector inserted between them, any imaginative and prescient embeddings might be aligned for any LLM’s comprehension. This structure presents elevated/related flexibility in comparison with coaching a imaginative and prescient encoder. One now has a option to freeze each imaginative and prescient and LLM networks. additionally accelerating coaching as a result of usually compact dimension of adapters.️
The projectors may very well be so simple as MLP, i.e, a number of linear layers interleaved with non-linear activation features. Some such fashions are –
- LLaVa household of fashions – A deceptively easy structure that gained prominence for its emphasis on coaching with high-quality artificial information.
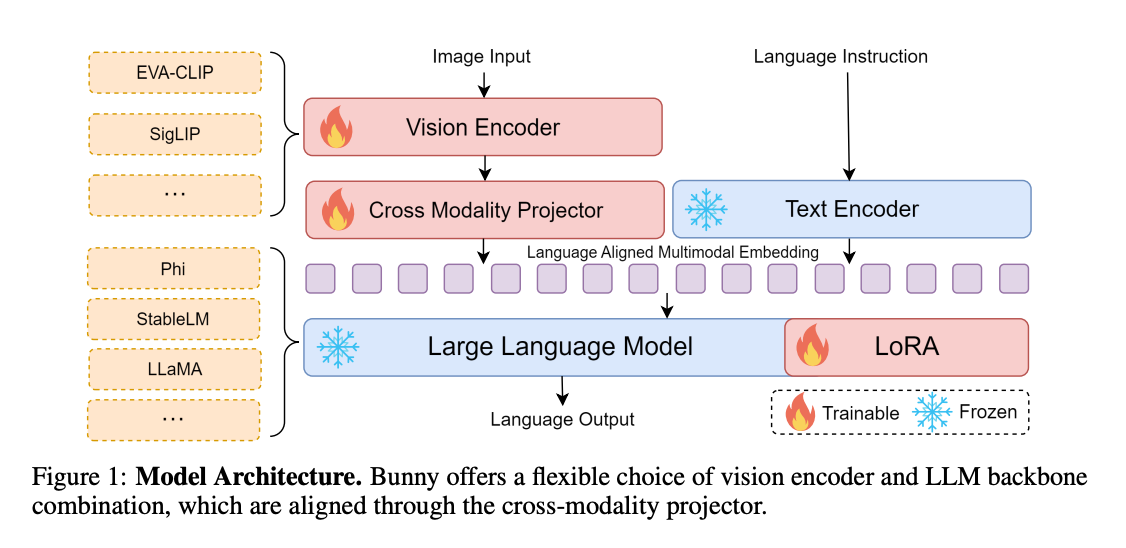
- Bunny – An structure which helps a number of imaginative and prescient and language backbones. It makes use of LoRA to coach LLMs part as properly.
- MM1 makes use of combination of specialists fashions, a 3B-MoE utilizing 64 specialists that replaces a dense layer with a sparse layer in every-2 layers and a 7B-MoE utilizing 32 specialists that replaces a dense layer with a sparse layer in every-4 layers. By leveraging MoEs and curating the datasets, MM1 creates a robust household of fashions which can be very environment friendly and correct.
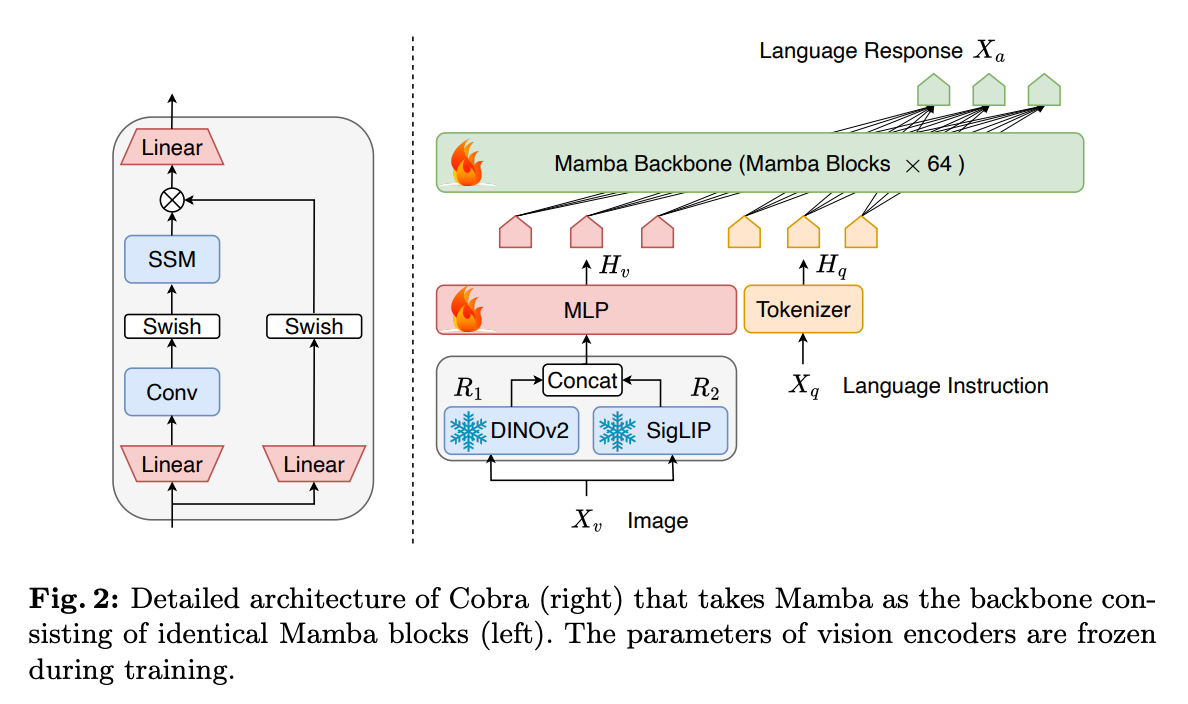
- Cobra – Makes use of the mamba structure as an alternative of the standard transformers
Projectors may also be specialised/complicated as exemplified by the next architectures
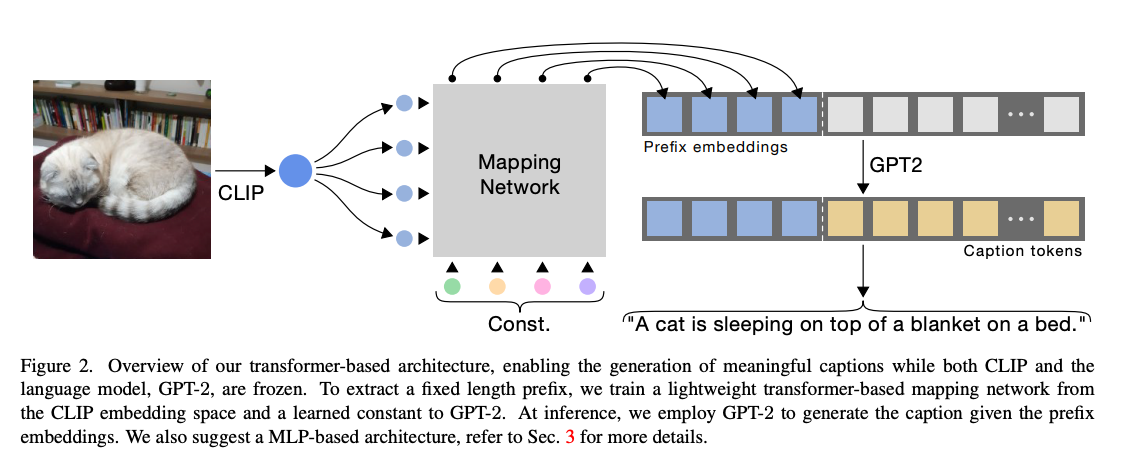
- CLIP Cap – Right here the “imaginative and prescient encoder” is actually a mixture of CLIP’s imaginative and prescient encoder + a transformer encoder
- BLIP-2 makes use of a Q-Former as its adapter for stronger grounding of content material with respect to photographs
- MobileVLMv2 makes use of a light-weight point-wise convolution based mostly structure as VLM with MobileLLama as (Small Language Mannequin) SLM as an alternative of an LLM, focussing on the pace of predictions.
One can use a number of projectors as properly
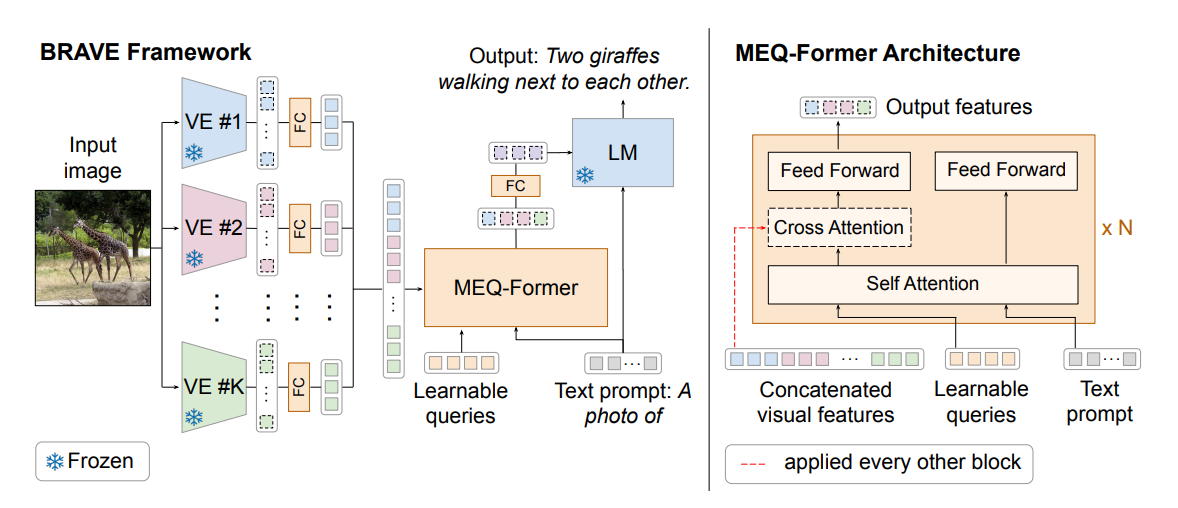
- BRAVE makes use of as much as 5 imaginative and prescient encoders and an adapter known as MEQ-Former that concatenates all of the imaginative and prescient inputs into one earlier than sending to the VLM
- Honeybee – makes use of two specialised imaginative and prescient encoders known as C-Abstractor and D-Abstractor that concentrate on locality preservation and talent to output a versatile variety of output tokens respectively
- DeepSeek VL additionally makes use of a number of encoders to protect each high-level and low-level particulars within the picture. Nevertheless on this case LLM can be educated resulting in deep fusion which we’ll cowl in a subsequent part.
Late Fusion
These architectures have imaginative and prescient and textual content fashions absolutely disjoint. The one place the place textual content and imaginative and prescient embeddings come collectively are throughout loss computation and this loss is often contrastive loss.
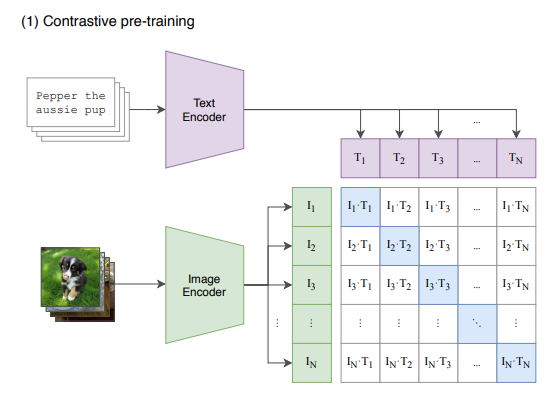
- CLIP is the basic instance the place textual content and picture are encoded individually and are in contrast by way of contrastive loss to regulate the encoders.
- JINA CLIP places a twist on CLIP structure by collectively optimizing CLIP Loss (i.e., image-text distinction) together with text-text distinction the place textual content pairs are deemed related if and provided that they’ve related semantic which means. There is a lesson to be taught right here, use extra goal features to make the alignment extra correct.
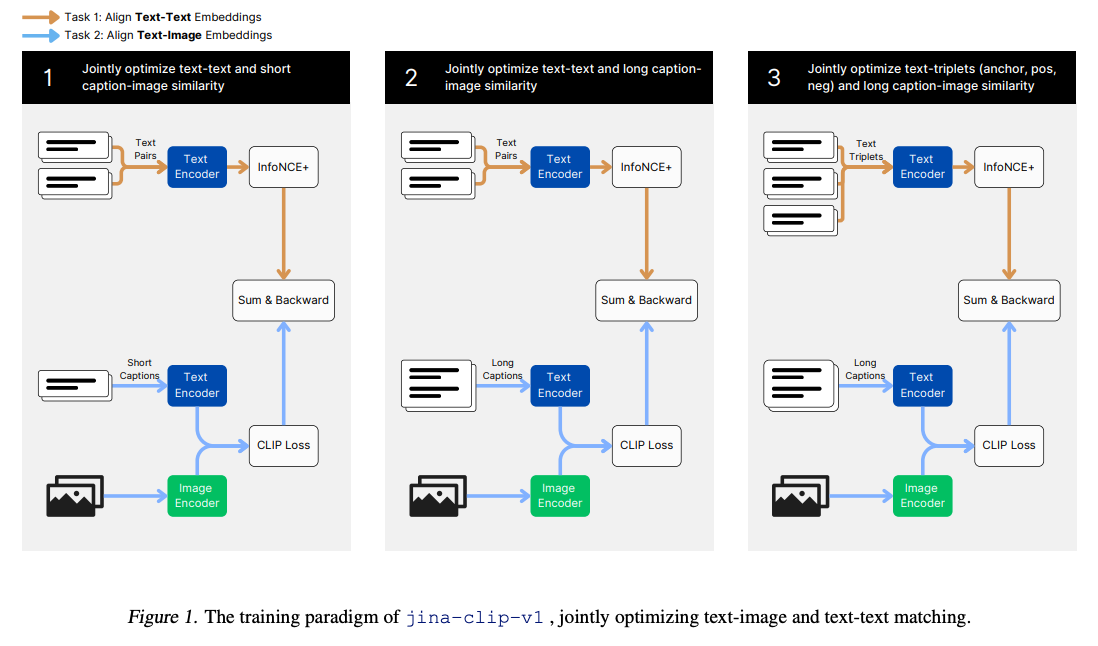
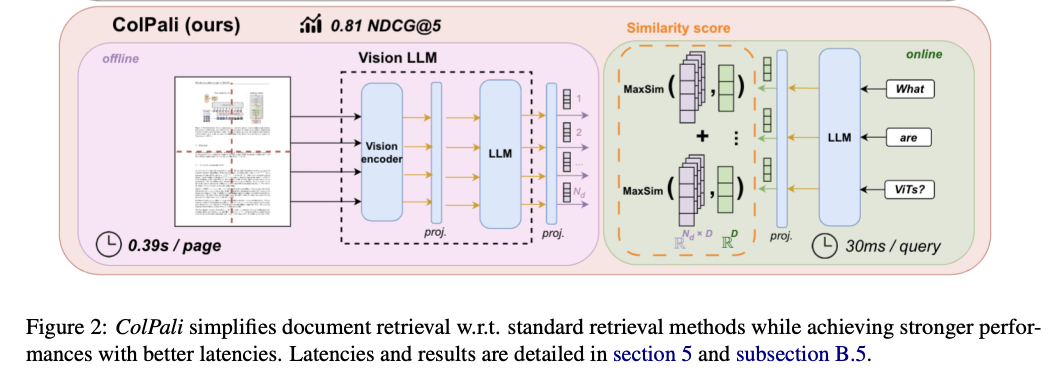
- ColPali is one other instance of late fusion, particularly educated for doc retrieval. Nevertheless, it differs barely from CLIP in that it makes use of a imaginative and prescient encoder mixed with a big language mannequin (LLM) for imaginative and prescient embeddings, whereas relying solely on the LLM for textual content embeddings.
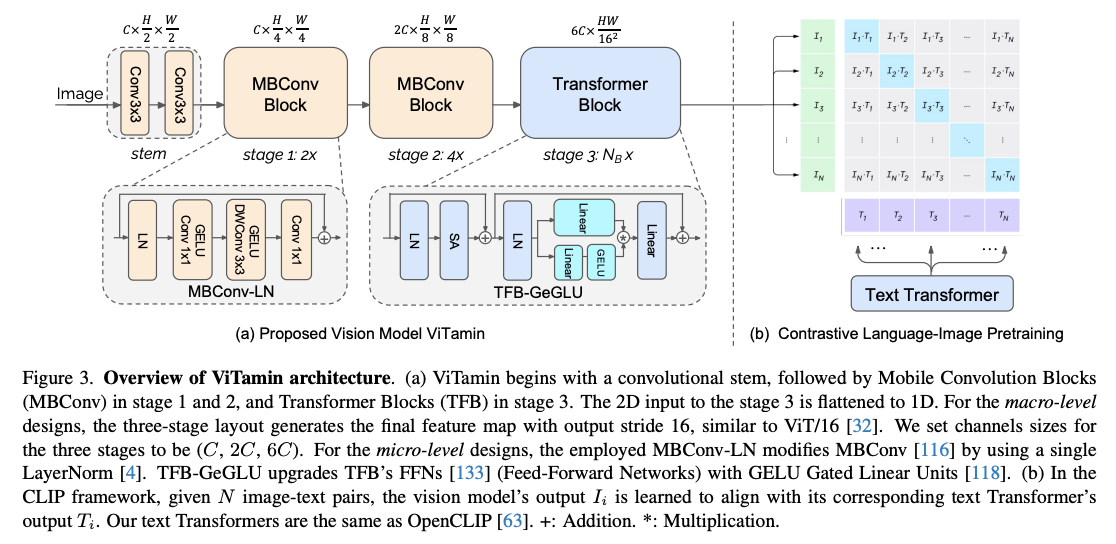
- ViTamin trains a imaginative and prescient tower that may be a concatenation of Convolution and Transformer blocks to get one of the best of each worlds.
Deep Fusion
These architectures usually attend to picture options within the deeper layers of the community permitting for richer cross modal data switch. Usually the coaching spans throughout all of the modalities. These usually take extra time to coach however could provide higher effectivity and accuracies. Typically the architectures are just like Two-Leg VLMs with LLMs unfrozen
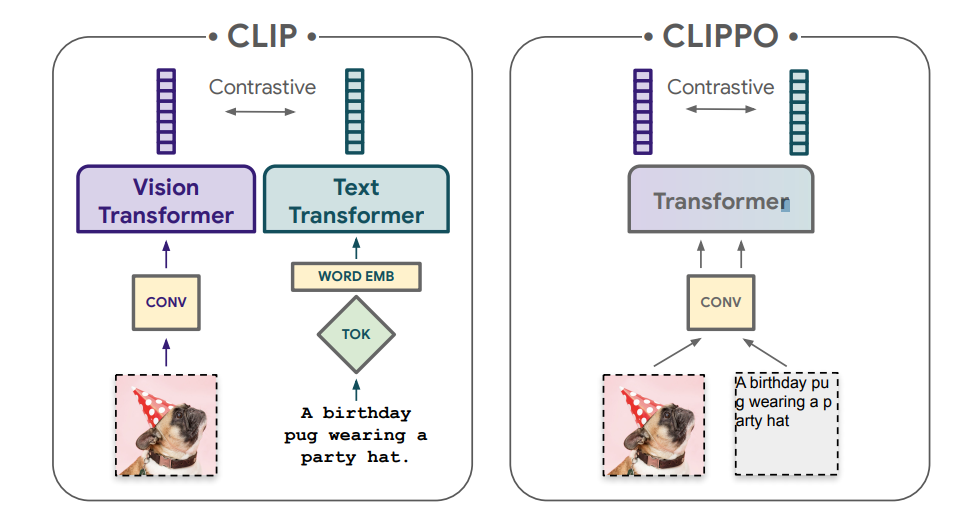
- CLIPPO is a variation of CLIP that makes use of a single encoder for each textual content and pictures.
- Single-tower Transformer trains a single transformer from scratch enabling a number of VLM functions directly.
- DINO makes use of localization loss along with cross-modality transformer to carry out zero-shot object detection, i.e, predict courses that weren’t current in coaching
- KOSMOS-2 treats bounding packing containers as inputs/outputs together with textual content and picture tokens baking object detection into the language mannequin itself.
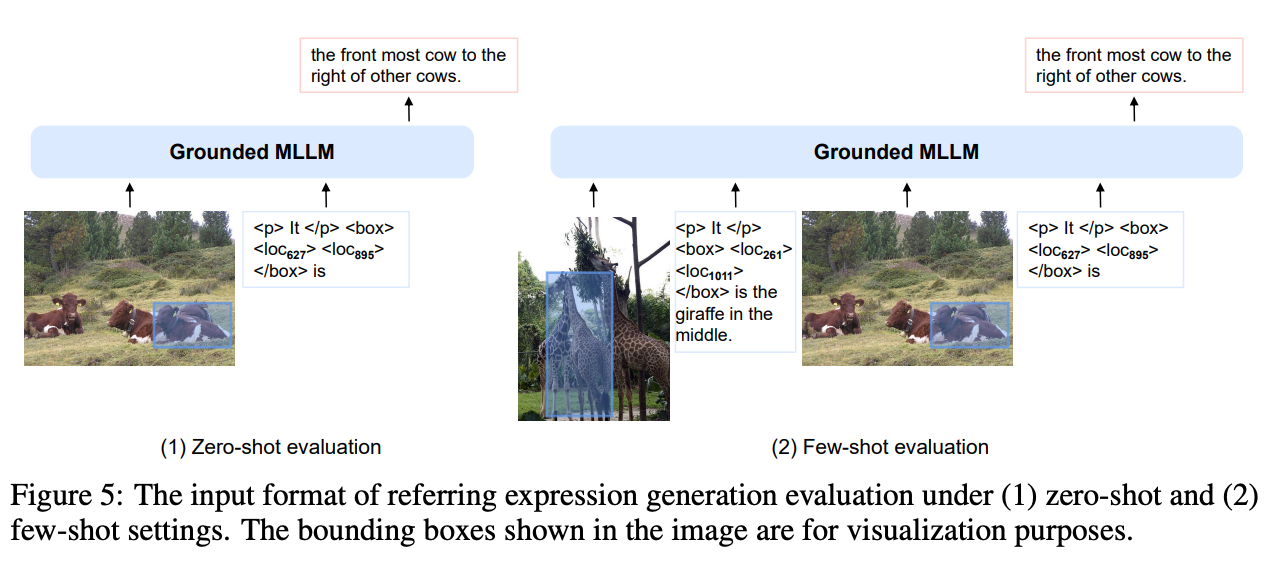
- Chameleon treats pictures natively as tokens by utilizing a quantizer resulting in text-vision agnostic structure
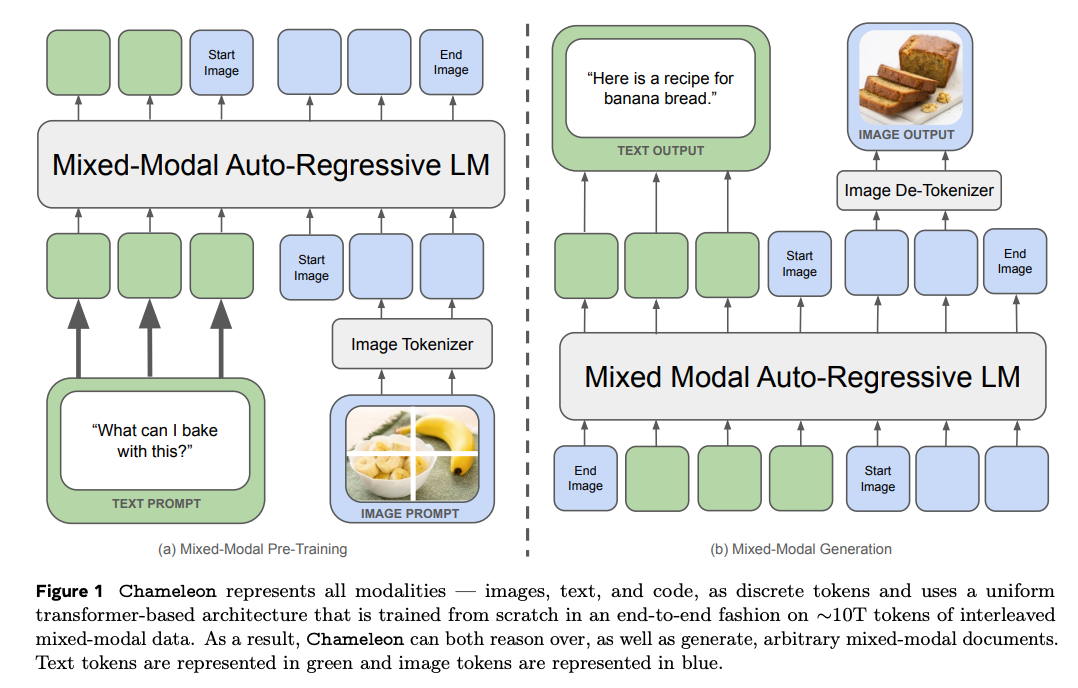
- FIBER makes use of dynamic cross consideration modules by switching them on/off to carry out completely different duties.
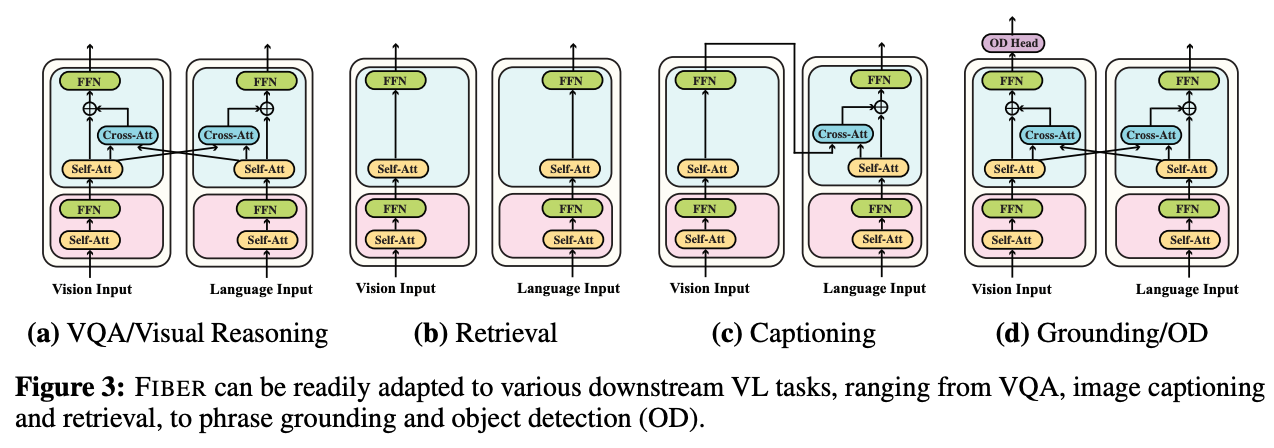
- BridgeTower creates a separate cross-modal encoder with a “bridge-layer” to cross attend to each textual content on imaginative and prescient and imaginative and prescient on textual content tokens to encapsulate a richer interplay.
- Flamingo – The imaginative and prescient tokens are computed with a modified model of Resnet and from from a specialised layer known as the Perceiver Resampler that’s just like DETR. It then makes use of dense fusion of imaginative and prescient with textual content by cross-attending imaginative and prescient tokens with language tokens utilizing a Chinchilla LLM because the frozen spine.
- MoE-LLaVa makes use of the combination of specialists method to deal with each imaginative and prescient and textual content tokens. It trains the mannequin in two levels the place solely the FFNs are educated first and later the LLM
VLM Coaching
Coaching a VLM is a posh course of that may contain a number of aims, every tailor-made to enhance efficiency on quite a lot of duties. Under, we’ll discover
- Goals – the widespread aims used throughout coaching and pre-training of VLMs, and
- Coaching Greatest Practices – among the finest practices reminiscent of pre-training, fine-tuning, and instruction tuning, which assist optimize these fashions for real-world functions
Goals
There’s a wealthy interplay between pictures and texts. Given the number of architectures and duties in VLM, there is not any single technique to practice the fashions. Let’s cowl the widespread aims used for coaching/pre-training of VLMs
- Contrastive Loss: This goals to regulate the embeddings in order that the gap between matching pairs is minimized, whereas the gap between non-matching pairs is maximized. It’s notably helpful as a result of it’s straightforward to acquire matching pairs, and on high of that each exponentially rising the variety of damaging samples out there for coaching.
- CLIP and all it is variations are a basic instance of coaching with contrastive loss the place the match occurs between embeddings of (picture and textual content) pairs. InternVL, BLIP2, SigLIP are additionally some notable examples.
- SLIP demonstrates that pre-training of imaginative and prescient encoder with image-to-image contrastive loss even earlier than pre-training CLIP, will assist a terrific deal in enhancing the general efficiency
- Florence modifies the contrastive loss by together with the picture label and hash of the textual content, calling it Unified-CL
- ColPali makes use of two contrastive losses, one for image-text and one for text-text.
- Generative Loss – This class of losses deal with the VLM as a generator and is normally used for zero-shot and language era duties.
- Language Modeling Loss – That is usually the loss you’ll use when coaching the VLM for subsequent token prediction. Chameleon places a twist on this loss by utilizing it to foretell picture tokens as properly.
- Masked Language Modeling – You practice a textual content language encoder to foretell intermediate token given the encompassing context FIBER are simply a few examples amongst a whole bunch.
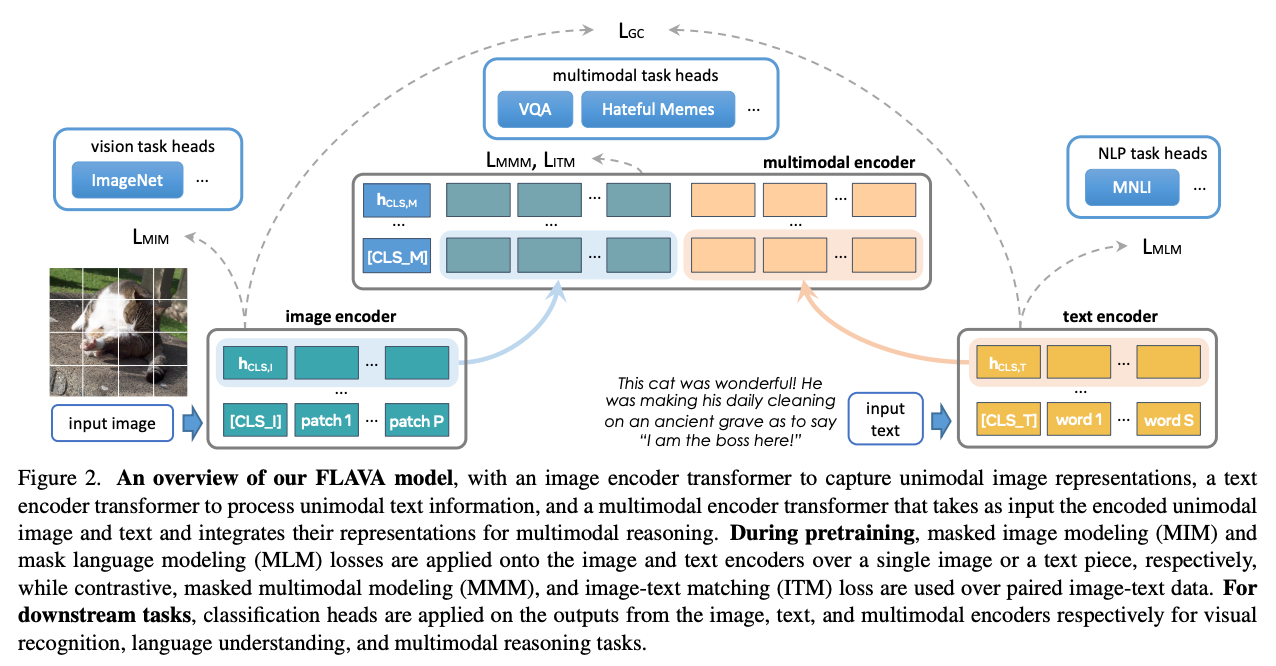
- Masked Picture Modeling – You practice a transformer to foretell picture tokens by masking them through the enter, forcing the mannequin to be taught with restricted information. LayoutLM, and utilization of MAE by SegCLIP, BeiT by FLAVA are examples of this loss
- Masked Picture+Textual content Modelling – Because the title suggests, one can use a two-leg structure to concurrently masks each picture and textual content tokens to make sure the community learns as a lot cross-domain interactions as attainable with restricted information. FLAVA is one such instance.
- Area of interest Cross Modality Alignments – Word that one can at all times give you good goal features given the richness of the panorama. For instance –
- BLIP2 created an Picture-grounded Textual content Era loss,
- LayoutLM makes use of one thing known as Phrase Patch Alignment to roughly determine the place a phrase is current within the doc
Coaching Greatest Practices
Coaching VLMs successfully requires extra than simply selecting the best aims—it additionally includes following established finest practices to make sure optimum efficiency. On this part, we’ll dive into key practices reminiscent of pre-training on massive datasets, fine-tuning for specialised duties, instruction tuning for chatbot capabilities, and utilizing strategies like LoRAs to effectively practice massive language fashions. Moreover, we’ll cowl methods to deal with complicated visible inputs, reminiscent of a number of resolutions and adaptive picture cropping.
Pre-training
Right here, solely the adapter/projector layer is educated with as a lot information as attainable (usually goes into thousands and thousands of image-text pairs). The purpose is to align picture encoder with textual content decoder and the main target may be very a lot on the amount of the information. Usually, this process is unsupervised in nature and makes use of one in every of contrastive loss or the following token prediction loss whereas adjusting the enter textual content immediate to be sure that the picture context is properly understood by the language mannequin.
Tremendous tuning
Relying on the structure some, or the entire adapter, textual content, imaginative and prescient parts are unfrozen from step 1 and educated. The coaching goes to be very gradual due to the massive variety of trainable parameters. Attributable to this, the variety of information factors is lowered to a fraction of knowledge that was utilized in first step and it’s ensured that each information level is of highest high quality.
Instruction Tuning
This may very well be the second/third coaching step relying on the implementation. Right here the information is curated to be within the type of directions particularly to make a mannequin that can be utilized as a chatbot. Often the out there information is transformed into instruction format utilizing an LLM. LLaVa and Imaginative and prescient-Flan are a few examples

Utilizing LoRAs
As mentioned, the second stage of coaching would possibly contain unfreezing LLMs. It is a very pricey affair since LLMs are huge. An environment friendly various to coaching LLMs with out this downside is to make the most of Low Rank Adaptation that inserts small layers in-between the LLM layers guaranteeing that whereas LLM is getting adjusted general, solely a fraction of the dimensions of LLM is being educated.
A number of Resolutions
VLMs face challenges when enter pictures have an excessive amount of dense data reminiscent of in duties with object/crowd counting and phrase recognition in OCR. Listed here are some papers that attempt to tackle it:
- The simplest approach is to easily resize picture to a number of resolutions and take all of the crops from every decision feed them to the imaginative and prescient encoder and feed them as tokens to LLM, this was proposed in Scaling on Scales and is utilized by Bunny household of fashions, one of many high performers throughout all duties.
- LLaVA-UHD tries to seek out one of the best ways to slice the picture into grids earlier than feeding to the imaginative and prescient encoder.


Coaching Datasets
Now that we all know what are one of the best practices, let’s digress into among the out there datasets for each coaching and fine-tuning.
There are broadly two classes of datasets for VLMs. One class of datasets concentrate on the amount and are primarily for guaranteeing quantity of unsupervised pre-training is feasible. The second class of datasets emphasizes specializations that improve area of interest or application-specific capabilities, reminiscent of being domain-specific, instruction-oriented, or enriched with extra modalities like bounding packing containers.
Under are among the datasets and spotlight their qualities which have elevated VLMs to the place they’re.
| Dataset | Variety of Picture Textual content Pairs | Description |
|---|---|---|
| WebLI (2022) | 12B | One of many greatest datasets constructed on net crawled pictures in 109 languages. Sadly this isn’t a public dataset |
| LAION-5B (2022) | 5.5B | A set picture and alt-text pairs over the web. Considered one of largest publicly out there dataset that’s utilized by plenty of implementations to pretrain VLMs from scratch. |
| COYO (2022) | 700M | One other large that filters uninformative pairs by way of the picture and textual content stage filtering course of |
| LAION-COCO (2022) | 600M | A subset of LAION-5B with artificial captions generated since alt-texts is probably not at all times correct |
| Obelics (2023) | 141M | Dataset is in chat format, i.e., a coversation with pictures and texts. Greatest for instruction pretraining and fine-tuning |
| MMC4 (Interleaved) (2023) | 101M | Related chat format as above. Makes use of a linear project algorithm to put pictures into longer our bodies of textual content utilizing CLIP options |
| Yahoo Flickr Artistic Commons 100 Million (YFCC100M) (2016) | 100M | One of many earliest massive scale datasets |
| Wikipedia-based Picture Textual content (2021) | 37M | Distinctive for its affiliation of encyclopedic data with pictures |
| Conceptual Captions (CC12M) (2021) | 12M | Focusses on a bigger and various set of ideas versus different datasets which usually cowl actual world incidents/objects |
| Purple Caps (2021) | 12M | Collected from Reddit, this dataset’s captions replicate real-world, user-generated content material throughout numerous classes, including authenticity and variability in comparison with different datasets |
| Visible Genome (2017) | 5.4M | Has detailed annotations, together with object detection, relationships, and attributes inside scenes, making it best for scene understanding and dense captioning duties |
| Conceptual Captions (CC3M) (2018) | 3.3M | Not a subset of CC12M, that is extra acceptable for fine-tuning |
| Bunny-pretrain-LAION-2M (2024) | 2M | Emphasizes on the standard of visual-text alignment |
| ShareGPT4V-PT (2024) | 1.2M | Derived from the ShareGPT platform the captions have been generated by a mannequin which was educated on GPT4V captions |
| SBU Caption (2011) | 1M | Sourced from Flickr, this dataset is beneficial for informal, on a regular basis image-text relationships |
| COCO Caption (2016) | 1M | 5 impartial human generated captions are be offered for every picture |
| Localized Narratives (2020) | 870k | This dataset accommodates localized object-level descriptions, making it appropriate for duties like picture grounding |
| ALLaVA-Caption-4V (2024) | 715k | Captions have been generated by GPT4V, this dataset focuesses on picture captioning and visible reasoning |
| LLava-1.5-PT (2024) | 558k | Yet one more dataset that was genereated by calling GPT4 on pictures. The main target is on high quality prompts for visible reasoning, dense captioning |
| DocVQA (2021) | 50k | Doc-based VQA dataset the place the questions concentrate on doc content material, making it essential for data extraction duties within the monetary, authorized, or administrative domains |
Analysis Benchmarks
On this part, let’s discover key benchmarks for evaluating vision-language fashions (VLMs) throughout a variety of duties. From visible query answering to document-specific challenges, these benchmarks assess fashions’ talents in notion, reasoning, and data extraction. We’ll spotlight common datasets like MMMU, MME, and Math-Vista, designed to forestall biases and guarantee complete testing.
Visible Query Answering
MMMU – 11.5k paperwork – 2024
Large Multi-discipline Multimodal Understanding and Reasoning (MMMU) benchmark is among the hottest benchmarks for evaluating VLMs. It focusses on quite a lot of domains to make sure the great VLMs examined are generalized.

Notion, data, and reasoning are the three abilities which can be being assessed by this benchmark. The analysis is a carried out underneath a zero-shot setting to generate correct solutions with out fine-tuning or few-shot demonstrations on our benchmark.

MMMU-PRO is a brand new model of MMMU that improves on MMMU by including tougher questions and filtering out some information factors that would have be solved by textual content enter alone.
MME – < 1000 pictures – 2024
This dataset focusses on high quality by handpicking pictures and creating annotations. Not one of the examples can be found wherever over the web and that is accomplished to make sure the VLMs are usually not unintentionally educated on any of them.
There are 14 subtasks within the benchmark with round 50 pictures in every process. Each process has a sure/no solutions solely. A few of the instance duties are existence of objects, notion of well-known objects/individuals, textual content translation and so on. Each picture additional has 2 questions one framed positively anticipated to get a “YES” from VLM and one body negatively to get a “NO” from VLM. Each subtask is it is personal benchmark. There are two sub-aggregate benchmarks one for cognition and one for notion that are sums of respective subtask-group’s accuracies. The ultimate benchmark is the sum of all of the benchmarks.
An instance set of questions for Cognition (reasoning) process within the dataset

MMStar – 1500 – 2024
This dataset is a subset of 6 VQA datasets which were completely filtered for prime quality guaranteeing the next –
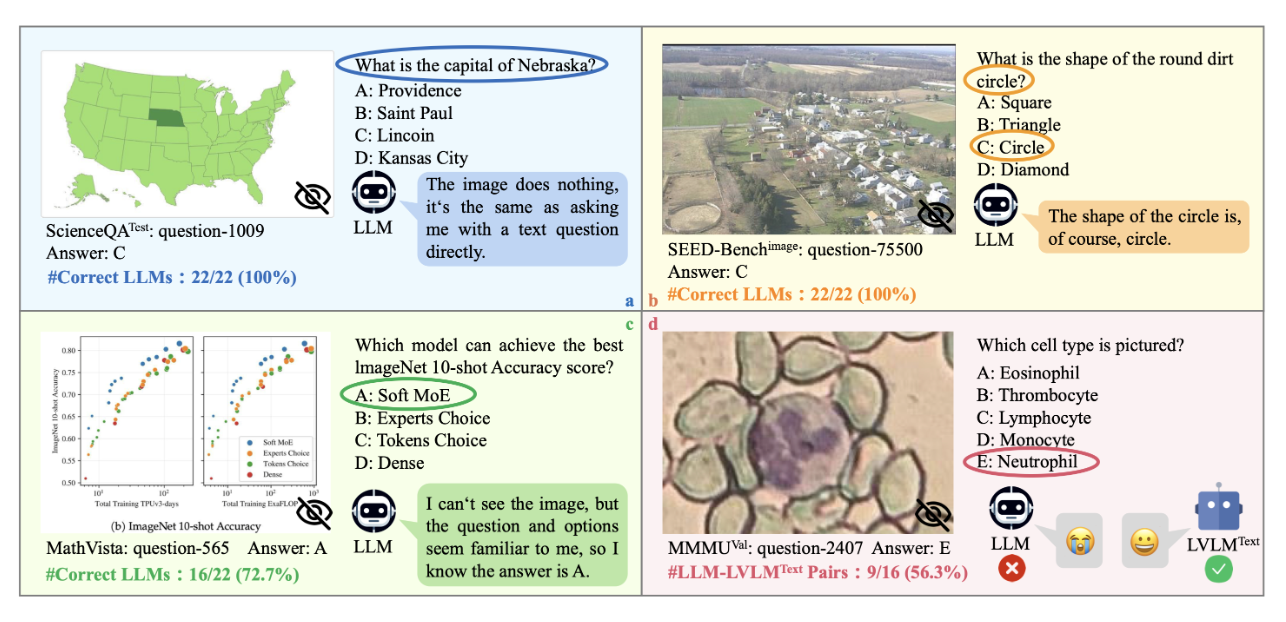
- Not one of the samples are answered by LLMs utilizing solely text-based world data.
- In no cases is the query itself discovered to comprise the reply, making pictures superfluous.
- Not one of the samples are recalled straight from LLMs’ coaching corpora with the textual questions and solutions.
Very like MME, this can be a dataset that focusses on high quality over amount.
Math-Vista – 6.1k paperwork – 2024
Collected and curated from over 31 distinction sources, this benchmark has questions particular to arithmetic throughout a number of reasoning sorts, process sorts, grade ranges and contexts.

The solutions are one in every of a number of decisions or numeric making it straightforward to judge.

MathVerse is a really related however completely different dataset that covers extra particular 2D, 3D geometry and analytical features as topics.
AI2D – 15k – 2016
A dataset that may be very focussed on science diagrams, this benchmark validates the understanding of a number of excessive stage ideas of a VLM. One must not solely parse the out there footage but in addition their relative positions, the arrows connecting them and at last the textual content that’s offered for every part. It is a dataset with 5000 grade faculty science diagrams masking over 150000 wealthy annotations, their floor reality syntactic parses, and greater than 15000 corresponding a number of alternative questions.

ScienceQA – 21k – 2022
Yet one more area particular dataset that checks the “Chain of Thought” (COT) paradigm by evaluating elaborate explanations together with a number of alternative solutions. It additionally evaluates the chat like functionality by sending a number of texts and pictures to the VLM.
MM-Vet v2 – 200 questions – 2024
Some of the common benchmarks and the smallest, this dataset assesses recognition, data, spatial consciousness, language era, OCR, and math capabilities of a mannequin by evaluating each single-image-single-text in addition to chat-like situations. As soon as once more InternVL has one of many highest scores in open supply choices.
VisDial – 120k pictures, 1.2M information factors – 2020
Derived from COCO, this can be a dataset that tries to evaluates a VLM Chatbot’s response to a collection of picture + textual content inputs adopted by a query.
LLaVA-NeXT-Interleave – 17k – 2024
This benchmark evaluates how succesful a fashions is predicated on a number of enter pictures. The bench combines 9 new and 13 present datasets together with Muir-Bench and ReMI

Different datasets
Listed here are a couple of extra visible query answering benchmarks which have easy (usually one phrase/phrase) questions and solutions and have particular space of focus
- SEED (19k, 2023) – A number of Selection questions of each pictures and movies
- VQA (2M, 2015) – One of many first datasets. Covers a variety of daily situations
- GQA (22M, 2019) – has compositional query answering, i.e., questions that relate a number of objects in a picture.
- VisWiz (8k, 2020) – is a dataset that was generated by blind individuals who every took a picture and recorded a spoken query about it, along with 10 crowdsourced solutions per visible query.
Different Imaginative and prescient Benchmarks
Word that any imaginative and prescient process is a VLM process just by including the requirement within the type of a textual content.
- For instance any picture classification dataset can be utilized for zero-shot picture classification by including the textual content immediate, “determine the salient object within the picture” process. ImageNet continues to be the most effective and OG dataset for this goal and nearly all of the VLMs have first rate efficiency on this process.
- POPE is a curious dataset that exemplifies how one can create complexity utilizing easy constructing blocks. It has questions posed as presence/absence of objects in a picture, by first utilizing an object detection mannequin to seek out objects for presence and utilizing negation to create a damaging/absence pattern set. That is additionally used for figuring out if the VLM is hallucinating.
VLM Benchmarks particular to Paperwork
- Doc classification – RVL-CDIP is a 16 class dataset with courses reminiscent of Letter, E mail, Kind, Bill and so on. Docformer is an efficient baseline.
- Semantic Entity Recognition – FunSD, EPHOIE, CORD are all variations on printed paperwork wich consider fashions on f1 rating of their respective courses. LiLT is a robust baseline.
- Multi-language Semantic Entity Recognition – Much like above level besides that the paperwork are in a couple of language. XFUND is a dataset with paperwork in 7 languages and roughly 100k pictures. LiLT is once more among the many high performers because it makes use of an LLM.
- OCRBench – is a properly rounded dataset of questions and solutions for pictures containing texts be it pure scenes or paperwork. It has general 5 duties spanning from OCR to VQA in various scene and process complexities. InternVL2 is a robust baseline for this benchmark, proving all spherical efficiency
- DocVQA – is a dataset that’s basically VQA for paperwork, with normally one sentence/phrase questions and one phrase solutions.
- ViDoRe – focusses completely on doc retrieval encompassing paperwork with texts, figures, infographics, tables in medical, enterprise, scientific, administrative domains in each English and French. ColPali is an efficient out of the field mannequin for this benchmark and process
State of the Artwork
It is vital for the reader to know that throughout the handfuls of papers the writer went by way of, one widespread remark was that the GPT4 household of fashions from OpenAI and the Gemini household of fashions from Google appear to be the highest performers with one or two exceptions right here and there. Open supply fashions are nonetheless catching as much as proprietary fashions. This may be attributed to extra focussed analysis, extra human hours and extra proprietary information on the disposal in non-public situations the place one can generate, modify and annotate massive volumes of knowledge. That mentioned, let’s checklist one of the best open supply fashions and level out what have been the standards that led to their successes.
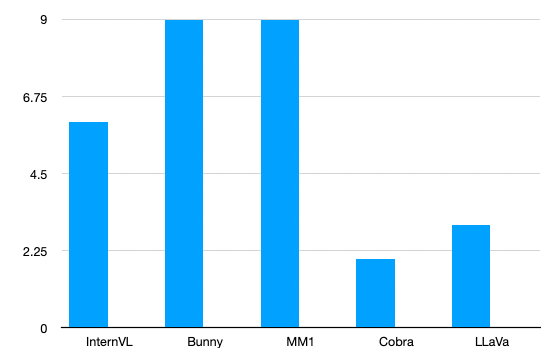
Firstly, the LLaVA household of fashions are a detailed second finest throughout duties. LLaVa-OneVision is their newest iteration that’s presently the chief in MathVista demonstrating excessive language and logic comprehension.
The MM1 set of fashions additionally carry out excessive on plenty of benchmarks primarily on account of its dataset curation and using combination of specialists in its decoders.
The Total finest performers when it comes to majority of the duties have been InternVL2, InternVL2-8B and Bunny-3B respectively for big, medium and tiny fashions among the many benchmarks.
A few issues widespread throughout all of those these fashions is
- the utilization of curated information for coaching, and
- picture inputs are processed in excessive decision or by way of a number of picture encoders to make sure that particulars at any stage of granularity are precisely captured.
One of many easiest methods to extract data from paperwork is to first use an OCR to transform the picture right into a structure conscious textual content and feed it to an LLM together with the specified data. This fully bypasses a necessity for VLM by utilizing OCR as a proxy for picture encoder. Nevertheless there are lots of issues with this method reminiscent of dependency on OCR, dropping the power to parse visible cues.
LMDX is one such instance which converts OCR textual content right into a structure conscious textual content earlier than sending to LLM.

DONUT was one of many unique VLMs that used a encoder decoder structure to carry out OCR free data extraction on paperwork.
The imaginative and prescient encoder is a SWIN Transformer which is right for capturing each low-level and high-level data from the Picture. BERT is used because the decoder, and is educated to carry out a number of duties reminiscent of classification, data extraction and doc parsing.

DiT makes use of self supervised coaching scheme with Masked Picture Modelling and discrete-VAE to be taught picture options. Throughout fine-tuning it makes use of a RCNN variant as head for doing object detection duties reminiscent of word-detection, table-detection and structure evaluation

LLaVa Subsequent is among the newest amongst LLaVa household of fashions. This mannequin was educated with plenty of textual content paperwork information along with pure pictures to spice up it is efficiency on paperwork.
InternVL is among the newest SOTA fashions educated with an 8k context window using coaching information with lengthy texts, interleaved pictures for chat potential, medical information in addition to movies
LayoutLM household of fashions use a two-leg structure on paperwork the place the bounding packing containers are used to create 2D embeddings (known as as structure embeddings) for phrase tokens, resulting in a richer. A brand new pretrainig object known as Phrase Patch Alignment is launched for making the mannequin perceive which picture patch a phrase belongs to.

LiLT was educated with cross modality interplay of textual content and picture parts. This additionally makes use of structure embeddings as enter and pretraining aims resulting in a richer spatially conscious interplay of phrases with one another. It additionally used a few distinctive losses

DeepSeek-VL is among the newest fashions which makes use of fashionable backbones and creates its dataset from all of the publically out there with selection, complexity, area protection, taken into consideration.
TextMonkey yet one more latest mannequin which makes use of overlapped cropping technique to feed pictures and textual content grounding aims to attain excessive accuracies on paperwork.
Issues to Take into account for Coaching your personal VLM
Let’s attempt to summarize the findings from the papers that we’ve got coated within the type of a run-book.
- Know your process properly
- Are you coaching just for visible query answering? Or does the mannequin want extra qualities like Picture Retrieval, or grounding of objects?
- Does it should be single picture immediate or ought to it have chat like performance?
- Ought to it’s realtime or can your shopper wait
- Questions like these can determine in case your mannequin might be massive, medium or small in dimension.
Developing with solutions to those questions can even assist you to zone into a selected set of architectures, datasets, coaching paradigms, analysis benchmarks and in the end, the papers it’s best to concentrate on studying.
- Choose the prevailing SOTA fashions and take a look at your dataset by posing the query to VLMs as Zeroshot or Oneshot examples. When your information is generic – with good immediate engineering, it’s doubtless that the mannequin will work.
- In case your dataset is complicated/area of interest, and also you to coach by yourself dataset, you must understand how huge is your dataset. Figuring out this may assist you to determine if you must practice from scratch or simply fine-tune an present mannequin.
- In case your dataset is simply too small, use artificial information era to multiply your dataset dimension. You should use an present LLM reminiscent of GPT, Gemini, Claude or InternVL. Guarantee your artificial information is properly assessed for high quality.
- Earlier than coaching you must ensure that loss is properly thought out. Attempt to design as many goal features as you may to make sure that the duty is properly represented by the loss perform. loss can elevate your mannequin to the following stage. Probably the greatest CLIP variations is nothing however CLIP with an added loss. LayoutLM and BLIP-2 use three losses every for his or her coaching. Take inspiration from them as coaching on extra loss features doesn’t have an effect on the coaching time anyway!
- You additionally want to select or design your benchmark from these talked about within the benchmarks part. Additionally give you precise enterprise metrics. Do not depend on simply the loss perform or the analysis benchmark to inform if a VLM is usable in a manufacturing setting. Your online business is at all times distinctive and no benchmark generally is a proxy for buyer satisfaction.
- In case you are fantastic tuning
- Prepare solely the adapters first.
- Within the second stage, practice imaginative and prescient and LLMs utilizing LORA.
- Make sure that your information is of the very best high quality, as even a single dangerous instance can hinder the progress of 100 good ones.
- In case you are coaching from scratch –
- Choose the proper backbones that play robust in your area.
- Use multi-resolution strategies talked about, for capturing particulars in any respect ranges of the picture.
- Use a number of imaginative and prescient encoders.
- Use Combination of specialists for LLMs in case your information is thought to be complicated.
- As a sophisticated practitioner, one can,
- First practice very massive fashions (50+ B parameters) and distill the learnings to a smaller mannequin.
- Strive a number of architectures – Very like the Bunny household of fashions, one can practice completely different combos of imaginative and prescient and LLM parts to finish up with a household of fashions for locating the proper structure.
Conclusion
In simply a short while, we reviewed over 50 arXiv papers, predominantly from 2022 to August 2024. Our focus was on understanding the core parts of Imaginative and prescient-Language Fashions (VLMs), figuring out out there fashions and datasets for doc extraction, evaluating the metrics for a high-quality VLM, and figuring out what you must know to successfully use a VLM.
As VLMs are one of the quickly advancing fields. Even after analyzing this in depth physique of labor, we’ve solely scratched the floor. Whereas quite a few new strategies will undoubtedly emerge, we’ve laid a stable basis in understanding what makes a VLM efficient and tips on how to develop one, if wanted.