
{kind=link}

Protein engineering is crucial for designing proteins with particular capabilities, however navigating the complicated health panorama of protein mutations poses a major problem, making it onerous to search out optimum sequences. Zero-shot approaches, which predict mutational results with out counting on homologs or a number of sequence alignments (MSAs), cut back some dependencies however fall quick in predicting various protein properties. Studying-based fashions educated on deep mutational scanning (DMS) or MAVE knowledge have been used to foretell health landscapes alone or with MSAs or language fashions. Nonetheless, these data-driven fashions typically wrestle when experimental knowledge is sparse.
Microsoft Analysis AI for Science researchers launched µFormer, a deep studying framework that integrates a pre-trained protein language mannequin with specialised scoring modules to foretell protein mutational results. µFormer predicts high-order mutants, fashions epistatic interactions, and handles insertions. With reinforcement studying, µFormer effectively explores huge mutant areas to design enhanced protein variants. The mannequin predicted mutants with a 2000-fold improve in bacterial progress charge, pushed by improved enzymatic exercise. µFormer’s success extends to difficult situations, together with multi-point mutations and its predictions had been validated via wet-lab experiments, highlighting its potential for optimizing protein design.
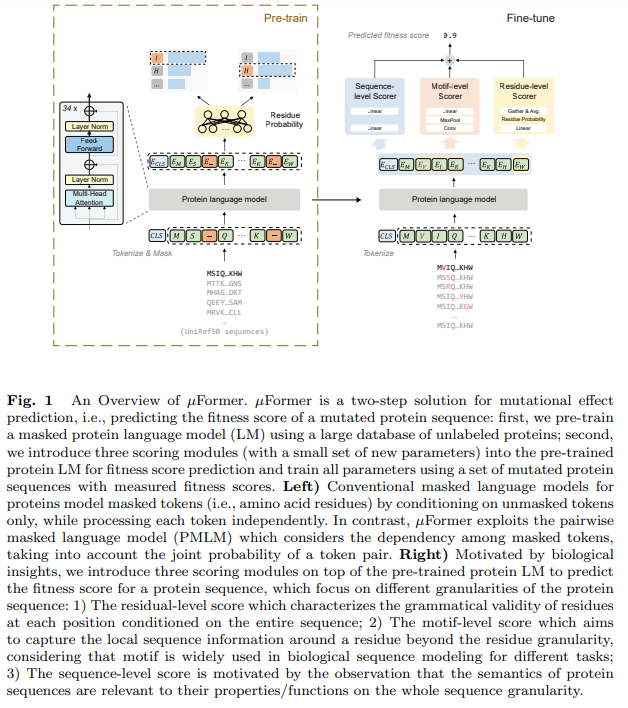
The µFormer mannequin is a deep studying strategy designed to foretell the health of mutated protein sequences. It operates in two phases: first, by pre-training a masked protein language mannequin (PLM) on a big dataset of unlabeled protein sequences, and second, by predicting health scores utilizing three scoring modules built-in into the pre-trained mannequin. These modules—residual-level, motif-level, and sequence-level—seize completely different elements of the protein sequence and mix their outputs to generate the ultimate health rating. The mannequin is educated utilizing identified health knowledge, minimizing errors between predicted and precise scores.
Moreover, the µFormer is mixed with a reinforcement studying (RL) technique to discover the huge house of potential mutations effectively. The protein engineering downside on this framework is modeled as a Markov Resolution Course of (MDP), with Proximal Coverage Optimization (PPO) used to optimize mutation insurance policies. Dirichlet noise is added through the mutation search course of to make sure efficient exploration and keep away from native optima. Baseline comparisons had been made utilizing fashions like ESM-1v and ECNet, and so they had been evaluated on datasets similar to FLIP and ProteinGym.
µFormer, a hybrid mannequin combining a self-supervised protein language mannequin with supervised scoring modules, predicts protein health scores effectively. Pre-trained on 30 million protein sequences from UniRef50 and fine-tuned with three scoring modules, µFormer outperformed ten strategies within the ProteinGym benchmark, reaching a imply Spearman correlation of 0.703. It predicts high-order mutations and epistasis, with sturdy correlations for multi-site mutations. In protein optimization, µFormer, paired with reinforcement studying, designed TEM-1 variants that considerably improved progress, with one double mutant outperforming a identified quadruple mutant.
In conclusion, Earlier research have proven the potential of sequence-based protein language fashions in duties like enzyme operate prediction and antibody design. µFormer, a sequence-based mannequin with three scoring modules, was developed to generalize throughout various protein properties. It achieved state-of-the-art efficiency in health prediction duties, together with complicated mutations and epistasis. µFormer additionally demonstrated its capacity to optimize enzyme exercise, notably in predicting TEM-1 variants in opposition to cefotaxime. Regardless of its success, enhancements will be made by incorporating structural knowledge, creating phenotype-aware fashions, and creating fashions able to dealing with longer protein sequences for higher accuracy.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and LinkedIn. Be a part of our Telegram Channel.
In the event you like our work, you’ll love our publication..
Don’t Neglect to affix our 50k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.