
{kind=link}


Picture by Pexels
Machine Studying (ML for brief) isn’t just about making predictions. There are different unsupervised processes, amongst which clustering stands out. This text introduces clustering and cluster evaluation, highlighting the potential of cluster evaluation for segmenting, analyzing, and gaining insights from teams of comparable information
What’s Clustering?
In easy phrases, clustering is a synonym for grouping collectively comparable information gadgets. This may very well be like organizing and inserting comparable fruit and veggies shut to one another in a grocery retailer.
Let’s elaborate on this idea additional: clustering is a type of unsupervised studying job: a broad household of machine studying approaches the place information are assumed to be unlabeled or uncategorized a priori, and the purpose is to find patterns or insights underlying them. Particularly, the aim of clustering is to find teams of knowledge observations with comparable traits or properties.
That is the place clustering is positioned throughout the spectrum of ML strategies:

To higher grasp the notion of clustering, take into consideration discovering segments of consumers in a grocery store with comparable buying habits, or grouping a big physique of merchandise in an e-commerce portal into classes or comparable gadgets. These are frequent examples of real-world eventualities involving clustering processes.
Frequent clustering strategies
There exist varied strategies for clustering information. Three of the preferred households of strategies are:
- Iterative clustering: these algorithms iteratively assign (and generally reassign) information factors to their respective clusters till they converge in the direction of a “ok” resolution. The preferred iterative clustering algorithm is k-means, which iterates by assigning information factors to clusters outlined by consultant factors (cluster centroids) and regularly updates these centroids till convergence is achieved.
- Hierarchical clustering: as their identify suggests, these algorithms construct a hierarchical tree-based construction utilizing a top-down strategy (splitting the set of knowledge factors till having a desired variety of subgroups) or a bottom-up strategy (regularly merging comparable information factors like bubbles into bigger and bigger teams). AHC (Agglomerative Hierarchical Clustering) is a typical instance of a bottom-up hierarchical clustering algorithm.
- Density-based clustering: these strategies determine areas of excessive density of knowledge factors to kind clusters. DBSCAN (Density-Primarily based Spatial Clustering of Functions with Noise) is a well-liked algorithm beneath this class.
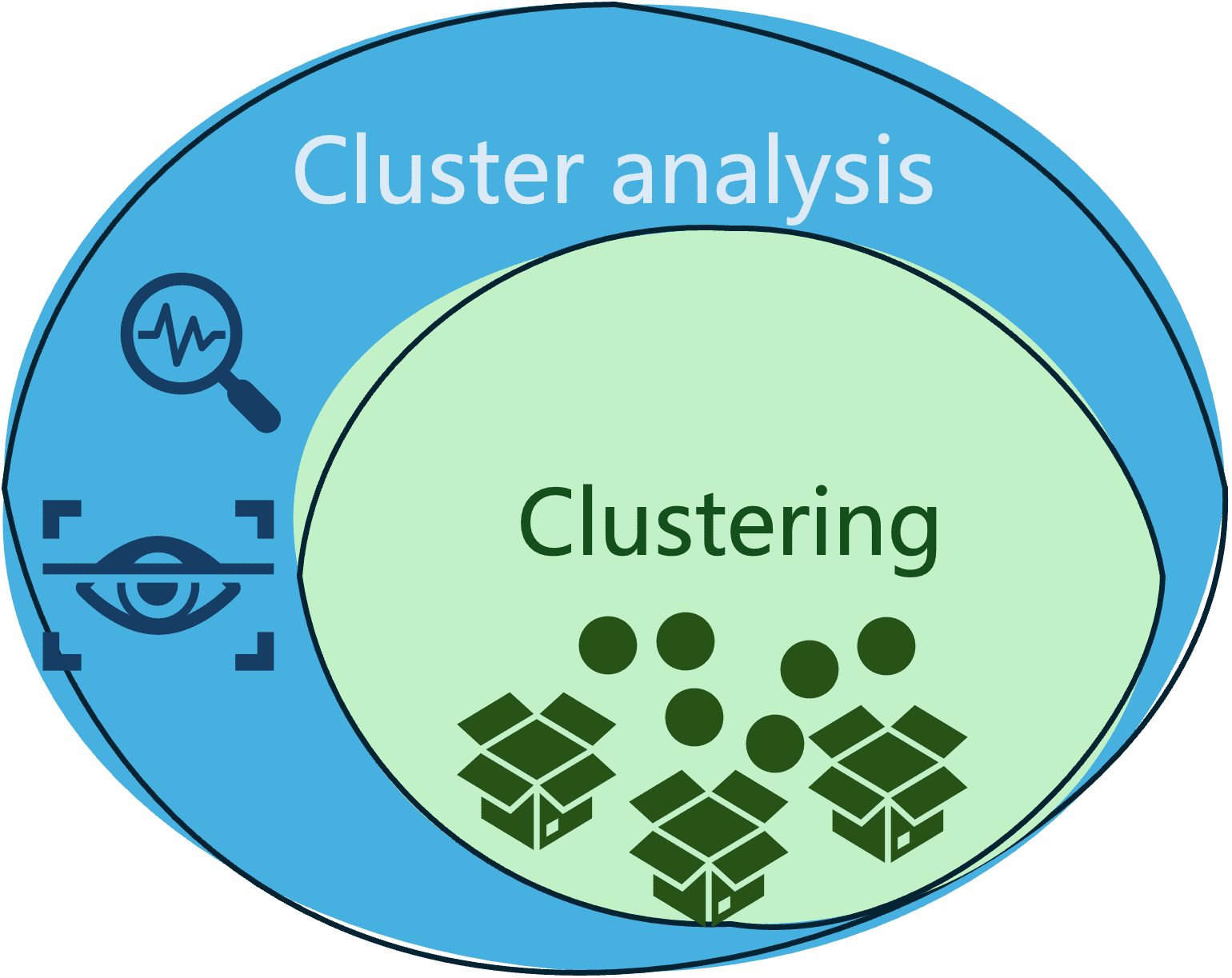
Are Clustering and Cluster Evaluation the Identical?
The burning query at this level may be: do clustering and clustering evaluation check with the identical idea?
Little question each are very carefully associated, however they aren’t the identical, and there are delicate variations between them.
- Clustering is the means of grouping comparable information in order that any two objects in the identical group or cluster are extra comparable to one another than any two objects in several teams.
- In the meantime, cluster evaluation is a broader time period that features not solely the method of grouping (clustering) information, but additionally the evaluation, analysis, and interpretation of clusters obtained, beneath a selected area context.
The next diagram illustrates the distinction and relationship between these two generally mixed-up phrases.
Sensible Instance
Let’s focus any longer cluster evaluation, by illustrating a sensible instance that:
- Segments a set of knowledge.
- Analyze the segments obtained
NOTE: the accompanying code on this instance assumes some familiarity with the fundamentals of Python language and libraries like sklearn (for coaching clustering fashions), pandas (for information wrangling), and matplotlib (for information visualization).
We’ll illustrate cluster evaluation on the Palmer Archipelago Penguins dataset, which comprises information observations about penguin specimens categorized into three totally different species: Adelie, Gentoo, and Chinstrap. This dataset is kind of common for coaching classification fashions, nevertheless it additionally has loads to say by way of discovering information clusters in it. All we have now to do after loading the dataset file is assume the ‘species’ class attribute is unknown.
import pandas as pd
penguins = pd.read_csv('penguins_size.csv').dropna()
X = penguins.drop('species', axis=1)
We may even drop two categorical options from the dataset which describe the penguin’s gender and the island the place this specimen was noticed, leaving the remainder of the numerical options. We additionally retailer the identified labels (species) in a separate variable y: they are going to be helpful in a while to check clusters obtained in opposition to the precise penguins’ classification within the dataset.
X = X.drop(['island', 'sex'], axis=1)
y = penguins.species.astype("class").cat.codes
With the next few traces of code, it’s doable to use the Ok-means clustering algorithms accessible within the sklearn library, to discover a quantity ok of clusters in our information. All we have to specify is the variety of clusters we need to discover, on this case, we’ll group the info into ok=3 clusters:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, n_init=100)
X["cluster"] = kmeans.fit_predict(X)
The final line within the above code shops the clustering end result, specifically the id of the cluster assigned to each information occasion, in a brand new attribute named “cluster”.
Time to generate some visualizations of our clusters for analyzing and decoding them! The next code excerpt is a bit lengthy, nevertheless it boils right down to producing two information visualizations: the primary one reveals a scatter plot round two information options -culmen size and flipper length- and the cluster every remark belongs to, and the second visualization reveals the precise penguin species every information level belongs to.
plt.determine (figsize=(12, 4.5))
# Visualize the clusters obtained for 2 of the info attributes: culmen size and flipper size
plt.subplot(121)
plt.plot(X[X["cluster"]==0]["culmen_length_mm"],
X[X["cluster"]==0]["flipper_length_mm"], "mo", label="First cluster")
plt.plot(X[X["cluster"]==1]["culmen_length_mm"],
X[X["cluster"]==1]["flipper_length_mm"], "ro", label="Second cluster")
plt.plot(X[X["cluster"]==2]["culmen_length_mm"],
X[X["cluster"]==2]["flipper_length_mm"], "go", label="Third cluster")
plt.plot(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,2], "kD", label="Cluster centroid")
plt.xlabel("Culmen size (mm)", fontsize=14)
plt.ylabel("Flipper size (mm)", fontsize=14)
plt.legend(fontsize=10)
# Examine in opposition to the precise ground-truth class labels (actual penguin species)
plt.subplot(122)
plt.plot(X[y==0]["culmen_length_mm"], X[y==0]["flipper_length_mm"], "mo", label="Adelie")
plt.plot(X[y==1]["culmen_length_mm"], X[y==1]["flipper_length_mm"], "ro", label="Chinstrap")
plt.plot(X[y==2]["culmen_length_mm"], X[y==2]["flipper_length_mm"], "go", label="Gentoo")
plt.xlabel("Culmen size (mm)", fontsize=14)
plt.ylabel("Flipper size (mm)", fontsize=14)
plt.legend(fontsize=12)
plt.present
Listed below are the visualizations:

By observing the clusters we will extract a primary piece of perception:
- There’s a delicate, but not very clear separation between information factors (penguins) allotted to the totally different clusters, with some light overlap between subgroups discovered. This doesn’t essentially lead us to conclude that the clustering outcomes are good or dangerous but: we have now utilized the k-means algorithm on a number of attributes of the dataset, however this visualization reveals how information factors throughout clusters are positioned by way of two attributes solely: ‘culmen size’ and ‘flipper size’. There may be different attribute pairs beneath which clusters are visually represented as extra clearly separated from one another.
This results in the query: what if we attempt visualizing our cluster beneath another two variables used for coaching the mannequin?
Let’s attempt visualizing the penguins’ physique mass (grams) and culmen size (mm).
plt.plot(X[X["cluster"]==0]["body_mass_g"],
X[X["cluster"]==0]["culmen_length_mm"], "mo", label="First cluster")
plt.plot(X[X["cluster"]==1]["body_mass_g"],
X[X["cluster"]==1]["culmen_length_mm"], "ro", label="Second cluster")
plt.plot(X[X["cluster"]==2]["body_mass_g"],
X[X["cluster"]==2]["culmen_length_mm"], "go", label="Third cluster")
plt.plot(kmeans.cluster_centers_[:,3], kmeans.cluster_centers_[:,0], "kD", label="Cluster centroid")
plt.xlabel("Physique mass (g)", fontsize=14)
plt.ylabel("Culmen size (mm)", fontsize=14)
plt.legend(fontsize=10)
plt.present

This one appears crystal clear! Now we have now our information separated into three distinguishable teams. And we will extract extra insights from them by additional analyzing our visualization:
- There’s a sturdy relationship between the clusters discovered and the values of the ‘physique mass’ and ‘culmen size’ attributes. From the bottom-left to the top-right nook of the plot, penguins within the first group are characterised by being small as a result of their low values of ‘physique mass’, however they exhibit largely various invoice lengths. Penguins within the second group have medium measurement and medium to excessive values of ‘invoice size’. Lastly, penguins within the third group are characterised by being bigger and having an extended invoice.
- It may be additionally noticed that there are just a few outliers, i.e. information observations with atypical values removed from the bulk. That is particularly noticeable with the dot on the very high of the visualization space, indicating some noticed penguins with an excessively lengthy invoice throughout all three teams.
Wrapping Up
This put up illustrated the idea and sensible software of cluster evaluation as the method of discovering subgroups of parts with comparable traits or properties in your information and analyzing these subgroups to extract useful or actionable perception from them. From advertising and marketing to e-commerce to ecology tasks, cluster evaluation is broadly utilized in a wide range of real-world domains.
Iván Palomares Carrascosa is a frontrunner, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the true world.